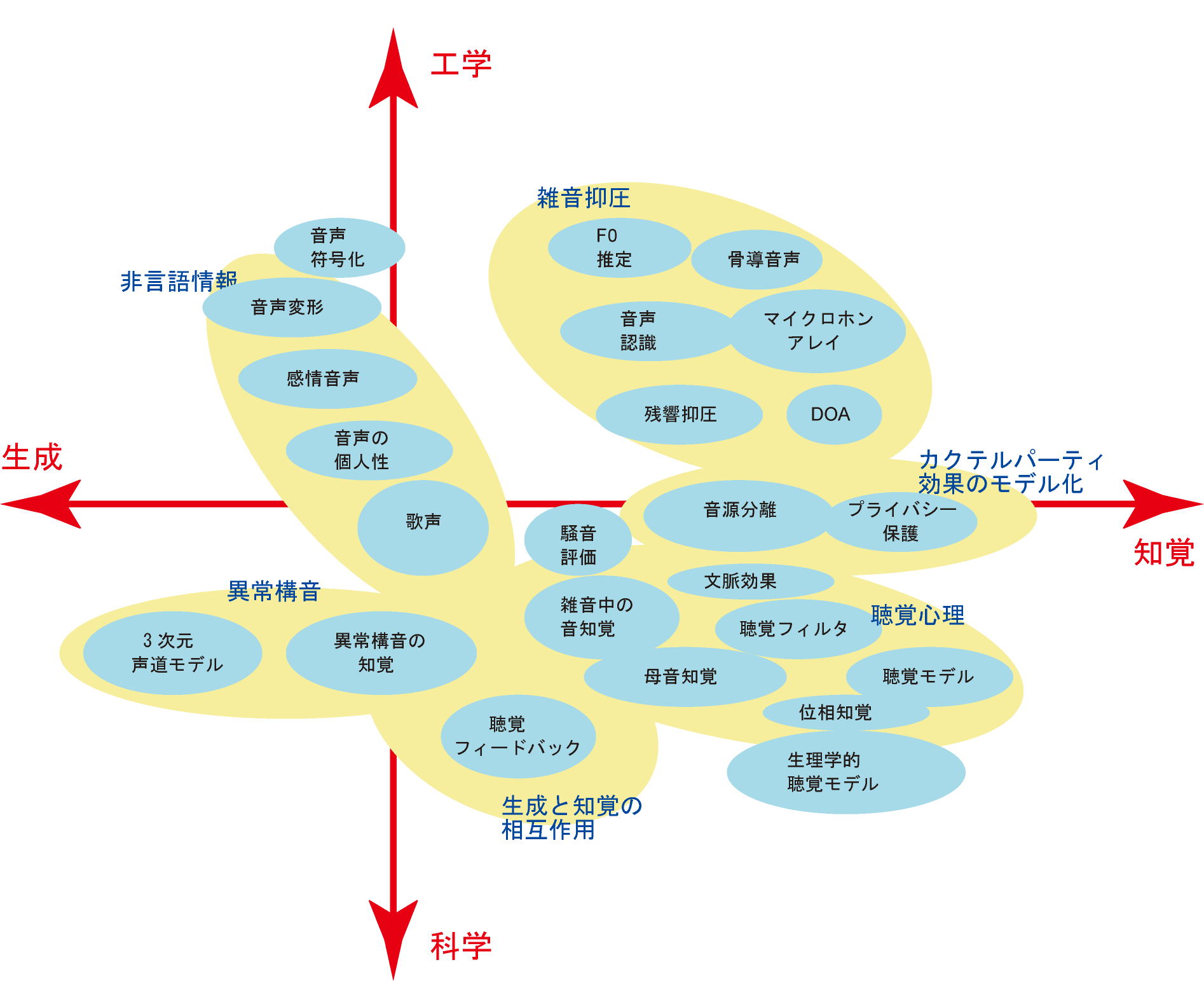
| 研究業績 (平成29年7月1日現在) |
1.非言語情報
1-1 歌声
1-2 音声の個人性
1-3 感情音声
1-4 音声変形
1-5 音声符号化
1-6 アナウンス音声
2.音声回復
2-1 雑音抑圧
2-2 雑音中のF0推定
2-3 残響抑圧
2-4 骨導音声
2-5 音声認識
2-6 音源方向推定
3.カクテルパーティ効果のモデル化
3-1 音源分離
3-2 プライバシー保護
3-3 雑音中の音知覚
4.聴覚心理
4-1 聴覚モデル
4-2 文脈効果
4-3 聴覚フィルタ
4-4 位相知覚
4-5 母音知覚
4-6 騒音評価
4-7 ピッチ知覚
4-8 方向知覚
5.生理学的聴覚モデル
6.異常構音
6-1 異常構音の知覚
6-2 3次元声道モデル
7.生成と知覚の相互作用
8.信号分析
9.書籍等
9-1 書籍等
9-2 その他
10.(参考)その他
10-1 NTT, ATR
10-2 東京工業大学
|
論文のコピーをご希望の方は,JAISTリポジトリからダウンロードできます

|
1.非言語情報
[1] Akagi, M. (2010/11/29). “Rule-based voice conversion derived from expressive speech perception model: How do computers sing a song joyfully?” Tutorial, ISCSLP2010, Tainan, Taiwan.
[2] Akagi, M. (2009/10/6). "Analysis of production and perception
characteristics of non-linguistic information in speech and its application
to inter-language communications," Proc. APSIPA2009, Sapporo, 513-519.
[3] Akagi, M. (2009/08/14). “Multi-layer model for expressive speech perception
and its application to expressive speech synthesis,” Plenary lecture, NCMMSC2009,
Lanzhou, China.
[4] Akagi, M. (2009/02/20). "Introduction of SCOPE project: Analysis
of production and perception characteristics of non-linguistic information
in speech and its application to inter-language communications," International
symposium on biomech
1-1 歌声
<査読付論文・国際会議>
[1] Motoda, H. and Akagi, M. (2013/03/5). “A singing voices synthesis system
to characterize vocal registers using ARX-LF model,” Proc. NCSP2013, Hawaii,
USA, 93-96.
[2] Saitou, T., Goto, M., Unoki, M., and Akagi, M. (2009/08/15) “Speech-to-Singing Synthesis System: Vocal Conversion from Speaking Voices to Singing Voices by Controlling Acoustic Features Unique to Singing Voices,” NCMMSC2009, Lanzhou, China.
[3] Nakamura, T., Kitamura, T. and Akagi, M. (2009/03/01). "A study
on nonlinguistic feature in singing and speaking voices by brain activity
measurement," Proc. NCSP'09, 217-220.
[4] 齋藤,辻,鵜木,赤木(2008).”歌声らしさの知覚モデルに基づいた歌声特有の音響特徴量の分析”,日本音響学会誌,64, 5, 267-277.
[5] Saitou, T., Goto, M., Unoku, M., and Akagi, M. (2007). "Speech-to-singing synthesis: converting speaking voices to singing voices by controlling acoustic features unique to singing voices," Proc. WASPAA2007, New Paltz, NY, pp.215-218
[6] Saitou, T., Goto, M., Unoki, M., and Akagi, M. (2007). "Vocal
conversion from speaking voice to singing voice using STRAIGHT," Proc.
Interspeech2007, Singing Challenge.
[7] Saitou, T., Unoki, M. and Akagi, M. (2005). "Development of an
F0 control model based on F0 dynamic characteristics for singing-voice
synthesis," Speech Communication 46, 405-417.
[8] Saitou, T., Tsuji, N., Unoki, M. and Akagi, M. (2004). “Analysis of acoustic features affecting “singing-ness” and its application to singing-voice synthesis from speaking-voice,” Proc. ICSLP2004, Cheju, Korea.
[9] Saitou, T., Unoki, M., and Akagi, M. (2004). “Control methods of acoustic
parameters for singing-voice synthesis,” Proc. ICA2004, 501-504.
[10] Saitou, T., Unoki, M., and Akagi, M. (2004). “Development of the F0
control method for singing-voices synthesis,” Proc. SP2004, Nara, 491-494.
[11] Saitou, T., Unoki, M., and Akagi, M. (2002). "Extraction of F0 dynamic characteristics and development of F0 control model in singing voice," Proc. ICAD2002, Kyoto.
[12] Unoki, M., Saitou, T., and Akagi, M. (2002). "Effect of F0 fluctuations
and development of F0 control model in singing voice perception,"
NATO Advanced Study Institute 2002 Dynamics of Speech Production and Perception.
[13] Akagi, M. and Kitakaze, H. (2000). "Perception of synthesized
singing voices with fine fluctuations in their fundamental frequency contours,"
Proc. ICSLP2000, Beijing, III-458-461.
<招待講演>
[1] Akagi, M. (2007/12/6). "Conversion of speaking voice into singing voice," ICT Forum Hanoi, Invited talk (Hanoi, Vietnam).
[2] Akagi, M. (2002). "Perception of fundamental frequency fluctuation," HEA-02-003-IP, Forum Acousticum Sevilla 2002 (Invited).
<研究会・大会>
[1] 元田,赤木 (2013/03/14). “ARX-LF に基づく声区表現を組み込んだ歌声合成システムの構築”,日本音響学会平成25年春季研究発表会,2-7-13.
[2] Elbarougy, R., Tokuda, I., and Akagi, M. (2013/03/13). “Acoustic Analysis
of Register Transition between Chest-to-Head Register in Singing Voice,”
Proc. ASJ '2013 Spring Meeting, 1-Q-7c.
[3] 元田,赤木 (2013/02/03). “声区表現可能な歌声合成を目的としたARX-LFパラメータの制御法の検討”,音響学会聴覚研究会資料,41,
7, H-2013-7.
[4] 元田,赤木 (2012/10/13). “声区の違いによる声質の変化と声帯音源特性の関連性”,音響学会聴覚研究会資料,41, 7, H-2012-10.
[5] 中村,北村,赤木 (2009/03/18). ”脳活動測定による歌声と話声に関する非言語特徴の検証”,日本音響学会21年度春季研究発表会,2-Q-12.
[6] 齋藤,後藤,鵜木,赤木 (2009/03/06). ”SingBySpeaking:ユーザの話声を歌声に変換する歌声合成インタフェース”,インタラクション2009.
[7] 中村,北村,赤木 (2008/10/17). ”fMRIを用いた歌声と話声における脳活動の差異の検討”,音響学会聴覚研究会資料、38, 6, H-2008-108.
[8] 齋藤,後藤,鵜木,赤木(2008/3/17).”SingBySpeaking:話声を歌声に変換する歌声合成システム”,日本音響学会平成20年春季研究発表会,
1-11-28.
[9] 齋藤,後藤,鵜木,赤木(2008/2/8).”SingBySpeaking:音声知覚に重要な音響特徴を制御して話声を歌声に変換するシステム”,情報処理学会研究報告,MUS-74
[10] Saitou, T., Unoki, M., and Akagi, M. (2006). "Analysis of acoustic features affecting singing-voice perception and its application to singing-voice synthesis from speaking-voice using STRAIGHT," J. Acoust. Soc. Am., 120, 5, Pt. 2, 3029.
[11] 齋藤,鵜木,赤木(2005).”自然性の高い歌声合成のためのヴィブラート変調周波数の制御法の検討”,電子情報通信学会技術報告、TL2005-10.
[12] 齋藤,辻,鵜木,赤木(2004).“歌声らしさに影響を与える音響的特徴量を考慮した話声からの歌声合成法”,電子情報通信学会技術報告、EA2004-30.
[13] 辻,赤木(2004).“歌声らしさの要因とそれに関連する音響特徴量の検討”,音響学会聴覚研究会資料、H-2004-8.
[14] 齋藤,鵜木,赤木(2003).“歌声のF0制御モデルにおけるパラメータ決定に関する考察”,音響学会聴覚研究会資料、H-2003-111
[15] 赤木,清水(2003).“STRAIGHTを用いた話声からの歌声合成”,電子情報通信学会技術報告、SP2003-37.
[16] 齋藤、鵜木、赤木(2001). ”歌声におけるF0動的変動成分の抽出とF0制御モデル”、音響学会聴覚研究会資料、H-2001-92
[17] 北風、赤木(2000).”基本周波数の微細変動成分に対する知覚”、電子情報通信学会技術報告、SP99-168.
[18] 皆川、赤木(1998).”連続発話母音の基本周波数変動とその知覚”、電子情報通信学会技術報告、SP97-134.
1-2 音声の個人性
<査読付論文・国際会議>
[1] Izumida, T. and Akagi, M. (2012/03/05). “Study on hearing impression
of speaker identification focusing on dynamic features,” Proc. NCSP2012,
Honolulu, HW, 401-404.
[2] Shibata, T. and Akagi, M. (2008/3/6). "A study on voice conversion
method for synthesizing stimuli to perform gender perception experiments
of speech," Proc. NCSP08, 180-183.
[3] Akagi, M., Iwaki, M. and Minakawa, T. (1998). “Fundamental frequency fluctuation in continuous vowel utterance and its perception,” ICSLP98, Sydney, Vol.4, 1519-1522.
[4] Akagi, M. and Ienaga, T. (1997). "Speaker individuality in fundamental
frequency contours and its control", J. Acoust. Soc. Jpn. (E), 18,
2 73-80.
[5] 北村、赤木(1997).”単母音の話者識別に寄与するスペクトル包絡成分”、日本音響学会誌、53, 3, 185-191.
[6] Akagi, M. and Ienaga, T. (1995). "Speaker individualities in fundamental frequency contours and its control", Proc. EUROSPEECH95, 439-442.
[7] Kitamura, T. and Akagi, M. (1995). "Speaker individualities in
speech spectral envelopes", J. Acoust. Soc. Jpn. (E), 16, 5, 283-289.
[8] Kitamura, T. and Akagi, M. (1994). "Speaker Individualities in
speech spectral envelopes", Proc. Int. Conf. Spoken Lang. Process.
94, 1183-1186.
<招待講演>
[1] 赤木正人(1999).”音声に含まれる個人性 −その分析と知覚−”、第38回日本ME学会大会招待講演、OS4-5.
<研究会・大会>
[1] 出水田,赤木 ((2012/03/13). “音声の動的成分に着目した個人性聴取印象の検討”,日本音響学会平成24年春季研究発表会,1-R-1.
[2] 出水田,赤木 (2011/10/01). “聴取印象に着目した音声の個人性知覚に関する基礎研究”,音響学会聴覚研究会資料,41, 7,
H-2011-98.
[3] 出水田,赤木(2011/09/17). “音声の個人性に関連する表現語の検討”, 平成23電気関係学会北陸支部連合大会,G-7.
[4] 柴田,赤木(2008/3/21). "連続発話音声中に含まれる男声•女声知覚に寄与する音響特徴量",電子情報通信学会技術報告、SP2007-206.
[5] 鈴木、赤木(1999).”文音声中に含まれる個人性情報の知覚”、電子情報通信学会技術報告、SP98-159.
[6] 北村、赤木、北澤(1998).”スペクトル遷移パターンが個人性知覚に与える影響について”、音響学会聴覚研究会資料、H-98-97.
[7] 大野、赤木(1998).”文音声中の基本周波数パターンに含まれる個人性の検討”、電子情報通信学会技術報告、SP97-128.
[8] 北村、赤木(1996).”連続音声中の母音に含まれる個人性について”、音響学会聴覚研究会資料、H-96-98
[9] 北村、赤木(1996).”話者識別に寄与するスペクトル包絡の成分について”、電子情報通信学会技術報告、SP95-144.
[10] Kitamura, T. and Akagi, M. (1996). "Relationship between physical
characteristics and speaker individualities in speech spectral envelopes",
Proc ASA-ASJ Joint Meeting, 833-838.
[11] 北村、赤木(1995).”個人性情報を含む周波数帯域について”、電子情報通信学会技術報告、SP95-37
[12] 家永、赤木 (1995).”音声のピッチ周波数の時間変化パターンに含まれる個人性とその制御”、電子情報通信学会技術報告、SP94-104
[13] 北村、赤木 (1994).”音声のスペクトル包絡に含まれる個人性について”、電子情報通信学会技術報告、SP93-146
1-3 感情音声
<査読付論文・国際会議>
[1] Asai, T., Suemitsu, A., and Akagi, M. (2017/03/02). “Articulatory Characteristics
of Expressive Speech in Activation-Evaluation Space,” Proc. NCSP2017, Guam,
USA, 313-316.
[2] Xue, Y., Hamada, Y., and Akagi, M. (2016/12/15). “Voice Conversion
to Emotional Speech based on Three-layered Model in Dimensional Approach
and Parameterization of Dynamic Features in Prosody,” Proc. APSIPA2016,
Cheju, Korea
[3] Xue, Y., Hamada, Y., Elbarougy, R., and Akagi, M. (2016/10/27). “Voice conversion system to emotional speech in multiple languages based on three-layered model for dimensional space,” O-COCOSDA2016, Bali, Indonesia, 122-127.
[4] Elbarougy, R. and Akagi, M. (2016/10/24). “Optimizing Fuzzy Inference
Systems for Improving Speech Emotion Recognition,” The 2nd International
Conference on Advanced Intelligent Systems and Informatics (AISI2016),
Cairo, Egypt, 85-95.
[5] Li, X. and Akagi, M. (2016/09/12). “Multilingual Speech Emotion Recognition
System Based on a Three-Layer Model,” Proc. InterSpeech2016, San Francisco,
3608-3612.
[6] Xue, Y. and Akagi, M. (2016/03/07). “A study on applying target prediction model to parameterize power envelope of emotional speech,” Proc. NCSP2016, Honolulu, HW, USA, 157-160.
[7] Li, X. and Akagi, M. (2016/03/07). “Automatic Speech Emotion Recognition
in Chinese Using a Three-layered Model in Dimensional Approach,” Proc.
NCSP2016, Honolulu, HW, USA, 17-20.
[8] Xue, Y., Hamada, Y., and Akagi, M. (2015/12/19). “Emotional speech
synthesis system based on a three-layered model using a dimensional approach,”
Proc. APSIPA2015, Hong Kong, 505-514.
[9] Hamada, Y., Elbarougy, R., Xue, Y., and Akagi, M. (2015/12/9). “Study on method to control fundamental frequency contour related to a position on Valence-Activation space,” Proc. WESPAC2015, Singapore, 519-522.
[10] Li, X. and Akagi, M. (2015/10/28). “Toward Improving Estimation Accuracy
of Emotion Dimensions in Bilingual Scenario Based on Three-layered Model,”
Proc. O-COCOSDA2015, Shanghai, 21-26.
[11] Xiao Han, Reda Elbarougy, Masato Akagi,Junfeng Li, Thi Duyen Ngo,
and The Duy Bui (2015/02/28). “A study on perception of emotional states
in multiple languages on Valence-Activation approach,” Proc NCSP2015, Kuala
Lumpur, Malaysia.
[12] Yasuhiro Hamada, Reda Elbarougy and Masato Akagi (2014/12/12). “A Method for Emotional Speech Synthesis Based on the Position of Emotional State in Valence-Activation Space,” Proc. APSIPA2014, Siem Reap, Cambodia.
[13] Masato AKAGI, Xiao HAN, Reda ELBAROUGY, Yasuhiro HAMADA, and Junfeng
LI (2014/12/10). “Toward Affective Speech-to-Speech Translation: Strategy
for Emotional Speech Recognition and Synthesis in Multiple Languages,”
Proc. APSIPA2014, Siem Reap, Cambodia.
[14] Elbarougy. R., Han.X., Akagi, M., and Li, J. (2014/09/10). “Toward
relaying an affective speech-to-speech translator: Cross-language perception
of emotional state represented by emotion dimensions,” Proc. O-COCOSDA2014,
Phuket, Thailand, 48-53.
[15] Akagi, M., Han, X., El-Barougy, R., Hamada, Y. and Li, J. (2014/08/27). “Emotional Speech Recognition and Synthesis in Multiple Languages toward Affective Speech-to-Speech Translation System,” Proc. IIHMSP2014, Kitakyushu, Japan, 574-577.
[16] Akagi, M. and Elbarougy, R. (2014/07/16). “Toward Relaying Emotional
State for Speech-To-Speech Translator: Estimation of Emotional State for
Synthesizing Speech with Emotion,” Proc. ICSV2014. Beijing.
[17] Li, Y. and Akagi, M. (2014/03/02). “Glottal source analysis of emotional
speech,” Proc. NCSP2014, Hawaii, USA, 513-516.
[18] Elbarougy, R. and Akagi, M. (2014/03/01). “Improving Speech Emotion Dimensions Estimation Using a Three-Layer Model for Human Perception,” Acoustical Science and Technology, 35, 2, 86-98.
[19] Elbarougy, R. and Akagi, M. (2013/11/01). “Cross-lingual speech emotion
recognition system based on a three-layer model for human perception,”
Proc. APSIPA2013, Kaohsiung, Taiwan.
[20] Elbarougy, R. and Akagi, M. (2012/12/04). “Speech Emotion Recognition
System Based on a Dimensional Approach Using a Three-Layered Model,” Proc.
APSIPA2012, Hollywood, USA.
[21] Dang, J., Li, A., Erickson, D., Suemitsu, A., Akagi, M., Sakuraba, K., Mienmatasu, N., and Hirose, K. (2010/11/01). “Comparison of emotion perception among different cultures,” Acoust. Sci. & Tech. 31, 6, 394-402.
[22] Zhou, Y., Li, J., Sun, Y., Zhang, J., Yan, Y., and Akagi, M. (2010/10).
“A hybrid speech emotion recognition system based on spectral and prosodic
features,” IEICE Trans. Info. & Sys., E93D (10): 2813-2821.
[23] Hamada, Y., Kitamura, T., and Akagi, M. (2010/08/24). “A study on
brain activities elicited by emotional voices with various F0 contours,”
Proc. ICA2010, Sydney, Australia.
[24] Hamada, Y., Kitamura, T., and Akagi, M. (2010/07/01). “A study of brain activities elicited by synthesized emotional voices controlled with prosodic features,” Journal of Signal Processing, 14, 4, 265-268.
[25] Hamada, Y., Kitamura, T., and Akagi, M. (2010/03/04). "A study
on brain activities elicited by synthesized emotional voices controlled
with prosodic features," Proc. NCSP10, Hawaii, USA, 472-475.
[26] Dang, J., Li, A., Erickson, D., Suemitsu, A., Akagi, M., Sakuraba,
K., Minematsu, N., and Hirose, K. (2009/10/6). "Comparison of emotion
perception among different cultures," Proc. APSIPA2009, Sapporo, 538-544.
[27] Aoki, Y., Huang, C-F., and Akagi, M. (2009/03/01). "An emotional speech recognition system based on multi-layer emotional speech perception model," Proc. NCSP'09, 133-136.
[28] Huang, C-F. and Akagi, M. (2008/10) "A three-layered model for
expressive speech perception," Speech Communication 50, 810-828.
[29] Huang, C. F., Erickson, D., and Akagi, M. (2008/07/01). "Comparison
of Japanese expressive speech perception by Japanese and Taiwanese listeners,"
Acoustics2008, Paris, 2317-2322.
[30] Huang, C. F. and Akagi, M. (2007). "A rule-based speech morphing for verifying an expressive speech perception model," Proc. Interspeech2007, 2661-2664.
[31] Sawamura K., Dang J., Akagi M., Erickson D., Li, A., Sakuraba, K.,
Minematsu, N., and Hirose, K. (2007). "Common factors in emotion perception
among different cultures," Proc. ICPhS2007, 2113-2116.
[32] Huang, C. F. and Akagi, M. (2007). "The building and verification
of a three-layered model for expressive speech perception," Proc.
JCA2007, CD-ROM.
[33] Huang, C. F. and Akagi, M. (2005). "A Multi-Layer fuzzy logical model for emotional speech Perception," Proc. EuroSpeech2005, Lisbon, Portugal, 417-420.
[34] Ito, S., Dang, J., and Akagi, M. (2004). “Investigation of the acoustic features of emotional speech using physiological articulatory model,” Proc. ICA2004, 2225-2226.
<本(章)>
[1] Huang, C. F. and Akagi, M. (2005). "Toward a rule-based synthesis of emotional speech on linguistic description of perception," Affective Computing and Intelligent Interaction, Springer LNCS 3784, 366-373.
<解説>
[1] 赤木正人(2010/08/01). “音声に含まれる感情情報の認識 ―感情空間をどのように表現するか―”,日本音響学会誌,66, 8,
393-398.
[2] 赤木正人(2005).”表現豊かな音声 ―その生成・知覚と音声合成への応用―”,日本音響学会誌,61, 6, 346-351.
<招待講演>
[1] Akagi, M. (2016/12/13). “Toward Affective Speech-to-Speech Translation,”
Keynote Speech, International Conference on Advances in Information and
Communication Technology 2016, Thai Nguyen, Vietnam, DOI 10.1007/978-3-319-49073-1
3.
[2] 赤木正人 (2015/05/23). “表現豊かな音声の認識・合成とAffective Speech-to-Speech Translationへの応用”,2015音学シンポジウム(電通大学),情報処理学会研究報告,2015-MUS-107,
6 (招待講演).
[3] 赤木正人 (2009/9/15). ”感情音声知覚モデルの提案とその応用”,日本音響学会平成21年秋季研究発表会(招待講演), 1-3-5.
<研究会・大会>
[1] Li, Y., Sakakibara, K., Morikawa, D., and Akagi, M. (2017/03/17). “Commonalities
and differences of glottal sources and vocal tract shapes among speakers
in emotional speech,” Proc. ASJ '2017 Spring Meeting, 3-Q-28.
[2] Xue, Y. and Akagi, M. (2017/03/17). “Acoustic features related to
speaking styles in valence-arousal dimensional space,” Proc. ASJ '2017
Spring Meeting, 3-Q-25.
[3] 浅井,末光,赤木 (2017/03/17). “EMAデータに基づいた演技感情音声発話時の調音運動制御の分析”,日本音響学会平成29年度春季研究発表会,
3-Q-18.
[4] Li, X. and Akagi, M. (2017/03/15). “Acoustic feature selection for improving estimation of emotions using a three layer model,” Proc. ASJ '2017 Spring Meeting, 1-Q-14.
[5] Li, Y., Morikawa, D., and Akagi, M. (2016/11/28). “A method to estimate
glottal source waves and vocal tract shapes for widely pronounced types
using ARX-LF model,” 2016 ASA-ASJ Joint meeting, Honolulu, Hawaii, JASA
140, 2963. doi: http://dx.doi.org/10.1121/1.4969159
[6] Xue, Y., Hamada, Y., and Akagi, M. (2016/11/28). “Emotional voice conversion
system for multiple languages based on three-layered model in dimensional
space,” 2016 ASA-ASJ Joint meeting, Honolulu, Hawaii, JASA 140, 2960. doi:
http://dx.doi.org/10.1121/1.4969141
[7] Li, Y., Morikawa, D., and Akagi, M. (2016/09/15). “Estimation of glottal source waves and vocal tract shapes of emotional speech using ARX-LF model,” Proc. ASJ '2016 Fall Meeting, 2-Q-36.
[8] Xue, Y. and Akagi, M. (2016/09/15). “Application of emotional voice
conversion system based on three-layer model for dimensional space to multiple
languages,” Proc. ASJ '2016 Fall Meeting, 2-Q-33.
[9] Xue, Y. and Akagi, M. (2015/10/23). “Rule-based emotional voice conversion
utilizing three-layered model for dimensional approach,” Proc. Auditory
Res. Meeting, The Acoustical Society of Japan, Taiwan, H-2015-103.
[10] Li, X. and Akagi, M. (2015/10/23). “Improving estimation accuracy of dimension values for speech emotion in bilingual cases using a three-layered model,” Proc. Auditory Res. Meeting, The Acoustical Society of Japan, Taiwan, H-2015-102.
[11] Xue, Y., Hamada, Y., and Akagi, M. (2015/09/16). “A method for synthesizing
emotional speech using the three-layered model based on a dimensional approach,”
Proc. ASJ '2015 Fall Meeting, 1-Q-40.
[12] Li, X., Akagi, M. (2015/09/16). “Study on estimation of bilingual
speech emotion dimensions using a three-layered model,” Proc. ASJ '2015
Fall Meeting, 1-Q-39.
[13] Li, Y., Hamada, Y., and Akagi, M. (2015/05/24). “Analysis of glottal source waves for emotional speech using ARX-LF model,” 2015 Otogaku Symposium, IPSJ SIG Technical Report, 2015-MUS-107, 69.
[14] 濱田 康弘,Elbarougy Reda,Li Yongwei,赤木 正人 (2015/03/16). “感情音声合成におけるValence-Activation
2 次元空間と関連する音響特徴の制御法の検討”, Proc. ASJ '2015 Spring Meeting, 2-Q-45.
[15] 李 永偉,浜田 康弘,赤木 正人 (2015/03/16). “Analysis of glottal source waves for
emotional speech using ARX-LF model,” Proc. ASJ '2015 Spring Meeting, 2-Q-44.
[16] 濱田康弘,Elbarougy, R., 赤木正人 (2014/10/23). “Valence-Activation2次元感情空間で定式化された感情音声合成法の提案”, 電子情報通信学会技術報告,SP2014-74.
[17] 濱田康弘, ELBAROUGY Reda, 赤木正人 (2014/09/03). “Valence-Activation 2 次元空間での感情表現にもとづいた感情音声合成”,日本音響学会平成26年度秋季研究発表会,
1-7-12.
[18] Han, X., Elbarougy, R., Akagi, M., and Li, J. (2014/09/03). “Study
on perceived emotional states in multiple languages on Valence-Activation
space,” Proc. ASJ '2014 Fall Meeting, 1-7-11.
[19] Han, X., Elbarougy, R., Akagi, M., and Li, J. (2014/06/19). “Comparison of perceived results of emotional states on Valence-Activation space among multi-languages,” IEICE Tech. Report, SP2014-55.
[20] Elbarougy, R. and Akagi, M. (2014/03/11). “Emotion recognition using
optimized adaptive neuro-fuzzy inference systems”,日本音響学会平成26年春季研究発表会,2-Q4-18.
[21] Elbarougy, R. and Akagi, M. (2013/09/25). “Cross-lingual Speech Emotion
Dimensions Estimation Based on a Three-Layer Model,” Proc. ASJ '2013 Fall
Meeting, 1-P-1a.
[22] Elbarougy, R. and Akagi, M. (2013/03/01). “Automatic Speech Emotion Recognition Using A Three Layer Model,” 電子情報通信学会技術報告,SP2012-127.
[23] Elbarougy, R. and Akagi, M. (2012/06/14). “Comparison of methods for
emotion dimensions estimation in speech using a three-layered model,” IEICE
Tech. Report, SP-2012-36.
[24] 濱田,李,赤木 (2012/05/25). “EEGによる基本周波数の時間変化に応じた脳活動の計測”, 音響学会聴覚研究会資料,42,
3, H-2012-45.
[25] 濱田,末光,赤木 (2011/09/20). “基本周波数の時間変化が事象関連電位に及ぼす影響”,日本音響学会平成23年秋季研究発表会, 1-Q-7.
[26] 濱田,北村,赤木 (2010/10/16). ”基本周波数包絡が異なる感情音声聴取時の脳活動測定”,音響学会聴覚研究会資料,40,
8, H-2010-117.
[27] 濱田康弘,北村達也,赤木正人 (2010/3/8). ”fMRI による感動詞「ええ」呈示時の脳活動測定”,日本音響学会平成22年春季研究発表会,
1-R-4.
[28] Zhou, Y., Li, J., Akagi, M., and Yan, Y. (2009/9/15). "Physiologically-Inspired Feature Extraction for Emotion Recognition," Proc. ASJ '2009 Fall Meeting, 1-R-11.
[29] 末光,朴,党,赤木,櫻庭,峯松,広瀬 (2009/03/19). ”異文化間における3 感情音声認知と6 感情音声認知の比較検討”,日本音響学会21年度春季研究発表会,3-6-3.
[30] 青木,黄,赤木(2009/03/18). ”音声からの感情認識による感情知覚多層モデルの評価”,日本音響学会21年度春季研究発表会,2-P-18.
[31] Huang, C. F., Erickson, D., and Akagi, M. (2007). "Perception of Japanese expressive speech: Comparison between Japanese and Taiwanese listeners," Proc. ASJ '2007 Fall Meeting, 1-4-6.
[32] Huang C. F., Erickson, D., and Akagi M. (2007). "A study on expressive
speech and perception of semantic primitives: Comparison between Taiwanese
and Japanese," 電子情報通信学会技術報告、SP2007-32.
[33] 黄,赤木(2005).”感情知覚モデルを検証するための規則の構築”,電子情報通信学会技術報告、SP2005-39.
[34] Huang, C. F. and Akagi, M. (2004). “A multi-layer fuzzy logical model for emotional speech perception,” Trans. Psycho. & Physio. Acoust., ASJ, H-2004-95.
[35] 平舘、赤木(2002).”怒りの感情音声における音響特徴量の分析”、電子情報通信学会技術報告、SP2001-141.
1-4 音声変形
<査読付論文・国際会議>
[1] Dinh, A. T., Phan, T. S., and Akagi, M. (2016/12/12). “Quality Improvement
of Vietnamese HMM-Based Speech Synthesis System Based on Decomposition
of Naturalness and Intelligibility Using Non-negative Matrix Factorization,”
International Conference on Advances in Information and Communication Technology
2016, Thai Nguyen, Vietnam, 490-499, DOI 10.1007/978-3-319-49073-1 53.
[
2] Dinh, A. T. and Akagi, M. (2016/10/26). “Quality Improvement of HMM-based
Synthesized Speech Based on Decomposition of Naturalness and Intelligibility
using Non-Negative Matrix Factorization,” O-COCOSDA2016, Bali, Indonesia,
62-67.
[3] Dinh, T. A, Morikawa, D., and Akagi, M. (2016/07/01), “Study on quality improvement of HMM-based synthesized voices using asymmetric bilinear model,” Journal of Signal Processing, 20, 4, 205-208.
[4] Dinh, T. A, Morikawa, D., and Akagi, M. (2016/03/07), “A study on quality
improvement of HMM-based synthesized voices using asymmetric bilinear model,”
Proc. NCSP2016, Honolulu, HW, USA, 13-16.
[5] Phung Trung Nghia, Luong Chi Mai, Masato Akagi (2015). “Improving the
naturalness of concatenative Vietnamese speech synthesis under limited
data conditions,” Journal of Computer Science and Cybernetics, V.31, N.1,
1-16.
[6] Phung, T. N., Phan, T. S., Vu, T. T., Loung, M. C., and Akagi, M. (2013/11/01). “Improving naturalness of HMM-based TTS trained with limited data by temporal decomposition,” IEICE Trans. Inf. & Syst., E96-D, 11, 2417-2426.
[7] Phung, T. N., Luong, M. C., and Akagi, M. (2013/09/02). “A Hybrid
TTS between Unit Selection and HMM-based TTS under limited data conditions,”
Proc. 8th ISCA Speech Synthesis Workshop, Barcelona, Spain 281-284.
[8] Phung, T. N., Luong, M. C., and Akagi, M. (2012/12/12). “Transformation
of F0 contours for lexical tones in concatenative speech synthesis of tonal
languages,” Proc. O-COCOSDA2012, Macau, 129-134.
[9] Phung, T. N., Luong, M. C., and Akagi, M. (2012/12/06). “A concatenative speech synthesis for monosyllabic languages with limited data,” Proc. APSIPA2012, Hollywood, USA.
[10] Phung, T. N., Luong, M. C., and Akagi, M. (2012/08). “On the stability
of spectral targets under effects of coarticulation,” International Journal
of Computer and Electrical Engineering, Vol. 4, No. 4, 537-541.
[11] Phung, T. N., Luong, M. C., and Akagi, M. (2012/08). “An investigation
on speech perception under effects of coarticulation,” International Journal
of Computer and Electrical Engineering, Vol. 4, No. 4, 532-536.
[12] Trung-Nghia Phung, Mai Chi Luong, and Masato Akagi (2011/02). “An investigation on perceptual line spectral frequency (PLP-LSF) target stability against the vowel neutralization phenomenon,” Proc. ICSAP2011, VI, 512-514.
[13] Trung-Nghia Phung, Mai Chi Luong, and Masato Akagi (2011/02). “An
investigation on speech perception over coarticulation,” Proc. ICSAP2011,
VI, 507-511.
[14] Nguyen B. P. and Akagi M. (2009/9/9). “Efficient modeling of temporal
structure of speech for applications in voice transformation,” Proc. InterSpeech2009,
Brighton, 1631-1634.
[15] Nguyen, B. P. and Akagi, M. (2009/5/1) "A flexible spectral modification method based on temporal decomposition and Gaussian mixture model," Acoust. Sci. & Tech., 30, 3, 170-179.
[16] Nguyen, B. P., Shibata, T., and Akagi, M. (2008/09/24). "High-quality
analysis/synthesis method based on Temporal decomposition for speech modification,"
Proc. InterSpeech2008, Brisbane, 662-665.
[17] Nguyen B. P. and Akagi M. (2008/6/6). "Phoneme-based spectral
voice conversion using temporal decomposition and Gaussian mixture model,"
Proc. ICCE2008, 224-229.
[18] Nguyen B. P. and Akagi M. (2008/3/7). "Control of spectral dynamics using temporal decomposition in voice conversion and concatenative speech synthesis," Proc. NCSP08, 279-282.
[19] Nguyen B. P. and Akagi M. (2007). "A flexible spectral modification
method based on temporal decomposition and Gaussian mixture model,"
Proc. Interspeech2007, 538-541.
[20] Nguyen B. P. and Akagi M. (2007). "Spectral Modification for
Voice Gender Conversion using Temporal Decomposition," Journal of
Signal Processing, 11, 4, 333-336.
[21] Nguyen B. P. and Akagi M. (2007). "Spectral Modification for Voice Gender Conversion using Temporal Decomposition," Proc. NCSP2007, 481-484.
[22] Takeyama, Y., Unoki, M., Akagi, M., and Kaminuma, A. (2006). "Synthesis of mimic speech sounds uttered in noisy car environments," Proc. NCSP2006, 118-121.
<招待講演>
[1] Akagi, M. (2008/6/5). "Voice conversion to add non-linguistic
information into speaking voices," ICCE2008, Tutorial (Hoian, Vietnam).
[2] Akagi, M., Saitou, T., and Huang, C-F. (2007). "Voice conversion
to add non-linguistic information into speaking voices," Proc. JCA2007,
CD-ROM.
[3] 赤木正人(2004).“「ビギナーズレクチャー」音声の音色を変えてみよう ‐話声から歌声へ,平声から怒声へ‐”,音響学会聴覚研究会資料、H-2004-105.
<研究会・大会>
[1] Dinh, T. A, and Akagi, M. (2016/03/29), “Quality improvement of HMM-based
synthesized speech based on decomposition of naturalness and intelligibility
using asymmetric bilinear model with non-negative matrix factorization,”
IEICE Tech. Report, SP2015-141.
[2] Phung, T. N. and Akagi, M. (2013/09/25). “Improving the naturalness
of speech synthesized by HMM-based systems by producing an appropriate
smoothness,” Proc. ASJ '2013 Fall Meeting, 2-7-9.
[3] Phung, T. N., Luong, M. C., and Akagi, M. (2013/03/13). “Improving the flexibility of unit-selection speech synthesis with Temporal Decomposition,” Proc. ASJ '2013 Spring Meeting, 1-7-16.
[4] Phung, T. N., Luong, M. C., and Akagi, M. (2012/06/14).” A low-cost
concatenative TTS for monosyllabic languages,” IEICE Tech. Report, SP-2012-35.
[5] Nguyen, B. P. and Akagi, M. (2009/02/20). "Applications of Temporal
Decomposition to Voice Transformation," International symposium on
biomechanical and physiological modeling and speech science, 19-24.
[6] Nguyen B. P. and Akagi M. (2008/3/17). "Improvement of Peak Estimation using Gaussian Mixture Model for Speech Modification," Proc. ASJ '2008 Spring Meeting, 1-11-27.
[7] Nguyen B. P. and Akagi M. (2007). "Temporal decomposition-based
speech spectra modeling using asymmetric Gaussian mixture model,"
Proc. ASJ '2007 Fall Meeting, 3-4-6.
[8] Nguyen B. P. and Akagi M. (2007). "A flexible temporal decomposition-based
spectral modification method using asymmetric Gaussian mixture model,"
電子情報通信学会技術報告、SP2007-25.
[9] 竹山,鵜木,赤木,神沼(2006).”自動車走行雑音下における車室内発話音声の合成”,平成18年春季音響学会講演論文、1-Q-18
1-5 音声分析・符号化
<査読付論文・国際会議>
[1] Kosugi, T., Haniu, A., Miyauchi, R., Unoki, M., and Akagi, M. (2011/03/01).
“Study on suitable-architecture of IIR all-pass filter for digital-audio
watermarking technique based on cochlear-delay characteristics,”Proc. NCSP2011,
Tianjin, China, 135-138.
[2] Tomoike, S. and Akagi, M. (2008). "Estimation of local peaks based
on particle filter in adverse environments," Journal of Signal Processing,
12, 4, 303-306.
[3] Tomoike, S. and Akagi, M. (2008/3/7). "Estimation of local peaks based on particle filter in adverse environments," Proc. NCSP08, 391-394.
[4] Nguyen, P. C., Akagi, M., and Nguyen, P. B. (2007). "Limited error
based event localizing temporal decomposition and its application to variable-rate
speech coding," Speech Communication, 49, 292-304.
[5] Akagi, M., Nguyen, P. C., Saitou, T., Tsuji, N., and Unoki, M. (2004).
“Temporal decomposition of speech and its application to speech coding
and modification,” Proc. KEST2004, 280-288.
[6] Akagi, M. and Nguyen, P. C. (2004). “Temporal decomposition of speech and its application to speech coding and modification,” Proc. Special Workshop in MAUI (SWIM), 1-4, 2004.
[7] Nguyen, P. C. and Akagi, M. (2003). “Efficient quantization of speech
excitation parameters using temporal decomposition,” Proc. EUROSPEECH2003,
Geneva, 449-452.
[8] Nguyen, P. C., Akagi, M., and Ho, T. B. (2003). "Temporal decomposition:
A promising approach to VQ-based speaker identification," Proc. ICME2003,
Baltimore, V.III, 617-620.
[9] Nguyen, P. C., Akagi, M., and Ho, T. B. (2003). "Temporal decomposition: A promising approach to VQ-based speaker identification," Proc. ICASSP2003, Hong Kong, I-184-187.
[10] Nguyen, P. C., Ochi, T., and Akagi, M. (2003). “Modified Restricted
Temporal Decomposition and its Application of Low Rate Speech Coding,”
IEICE Trans. Inf. & Syst., E86-D, 3, 397-405.
[11] Nguyen, P. C. and Akagi, M.. (2002). "Variable rate speech coding
using STRAIGHT and temporal decomposition," Proc. SCW2002, Tsukuba,
26-28.
[12] Nguyen, P. C. and Akagi, M.. (2002). "Coding speech at very low rates using STRAIGHT and temporal decomposition," Proc. ICSLP2002, Denver, 1849-1852.
[13] Nguyen, P. C. and Akagi, M. (2002). "Limited error based event
localizing temporal decomposition," Proc. EUSIPCO2002, Toulouse, 190.
[14] Nguyen, P. C. and Akagi, M.. (2002). "Improvement of the restricted
temporal decomposition method for line spectral frequency parameters,"
Proc. ICASSP2002, Orlando, I-265-268.
[15] Nandasena, A.C.R, Nguyen, P. C., and Akagi, M. (2001). " Spectral stability based event localizing temporal decomposition", Computer Speech & Language, Vol. 15, No. 4, 381-401
[16] Nandasena, A.C.R. and Akagi, M. (1998). “Spectral stability based event localizing temporal decomposition,” Proc. ICASSP98, II, 957-960
<研究会・大会>
[1] Dong, L., Elbarougy. R., and Akagi, M. (2014/09/03). “HMM-based phonetic
segmentation using Adaptive Neuro Fuzzy Inference,” Proc. ASJ '2014 Fall
Meeting, 1-7-2.
[2] Dong, L., Elbarougy, R., and Akagi, M. (2014/06/20). “Accurate phoneme
segmentation method using combination of HMM and Fuzzy Inference system,”
IEICE Tech. Report, SP2014-57.
[3] 鵜木,小杉,羽二生,宮内,赤木(2011/08/09). “電子音響透かし法のための蝸牛遅延フィルタの最適構成に関する検討”, 電子情報通信学会技術報告,EA2011-55.
[4] 小杉,羽二生,宮内,鵜木,赤木.(2011/03/09). “蝸牛遅延特性に基づく音声ステガノグラフィーの検討”,日本音響学会平成23年春季研究発表会,
1-Q-33.
[5] 越智、Nguyen, P. C.、赤木 (2002). ”Temporal Decompositionを用いたSTRAIGHT用低ビットレート音声符号化”、平成14年春季音響学会講演論文、3-10-24.
[6] Nandasena, A.C.R. and Akagi, M. (1997). "S2BEL Temporal Decomposition for Efficient Spectral Coding", Proc. ASJ '97 Fall Meeting, 1-P-21.
[7] 橋本、赤木(1996).”音声のスペクトル補間符号化のための基準フレームの性質”、平成8年秋季音響学会講演論文、3-6-18.
[8] 桑原、赤木 (1994).”音声のスペクトル補間を用いた音声符号化・復号化”、電子情報通信学会技術報告、SP93-152
1-6 アナウンス音声
<査読付論文・国際会議>
[1] Ngo, T. V., Kubo, R., Morikawa, D., and Akagi, M. (2017/03/02). “Acoustical analyses of Lombard speech by different background noise levels for tendencies of intelligibility,” Proc. NCSP2017, Guam, USA, 309-312.
[2] Kubo, R, Morikawa, D., and Akagi, M. (2016/08/22). “Effects of speaker’s
and listener’s acoustic environments on speech intelligibility and annoyance”,
Proc. Inter-Noise2016, Hamburg, Germany, 171-176.
<研究会・大会>
[1] Ngo, V. T., Kubo, R., Morikawa, D., and Akagi, M. (2017/03/17). “Acoustic
variation of Lombard speech produced in various noise-level environments,”
Proc. ASJ '2017 Spring Meeting, 3-Q-20.
[2] 久保,森川,赤木 (2017/03/17). “残響環境下での話速変化が音声了解度に与える影響” , 日本音響学会平成29年度春季研究発表会, 3-Q-5.
[3] 久保 理恵子,森川 大輔,赤木 正人 (2016/03/28). “音声の耳障り感と了解性にロンバード効果が与える影響”,電子情報通信学会技術報告,SP2015-110.
[4] 久保 理恵子,森川 大輔,赤木 正人 (2016/03/9). “ロンバード効果が音声の了解度と耳障りさに与える影響”,日本音響学会平成28年度春季研究発表会,
1-9-11.
[5] 久保 理恵子,森川 大輔,赤木 正人 (2015/09/17). “雑音呈示方法が Lombard 効果に与える影響”,日本音響学会平成27年度秋季研究発表会,
2-P-46.
2.雑音抑圧
2-1 マイクロホンアレイ
<査読付論文・国際会議>
[1] Junfeng Li, Risheng Xia, Dongwen Ying, Yonghong Yan, and Masato Akagi
(2014/12/05). “Investigation of objective measures for intelligibility
prediction of noise-reduced speech for Chinese, Japanese, and English,”
J. Acoust. Soc. Am. 136 (6), 3301-3312.
[2] Li, J, Chen, F., Akagi, M., and Yan, Y. (2013/08/27), “Comparative investigation of objective speech intelligibility prediction measures for noise-reduced signals in Mandarin and Japanese,” Proc. InterSpeech2013, Lyon, 1184-1187.
[3] Li, J., Akagi, M., and Yan, Y. (2013/07/09). “Objective Japanese intelligibility
prediction for noisy speech signals before and after noise-reduction processing,”
Proc. ChinaSIP2013, Beijing, 352-355.
[4] Xia, R., Li, J., Akagi, M., and Yan, Y. (2012/03/28). “Evaluation of
objective intelligibility prediction measures for noise-reduced signals
in Mandarin,” Proc. ICASSP2012, Kyoto, 4465-4468.
[5] Li, J., Sakamoto, S., Hongo, S., Akagi, M., and Suzuki, Y. (2011/06). “Two-stage binaural speech enhancement with Wiener filter for high-quality speech communication,” Speech Communication 53 677-689.
[6] Li, J., Yang, L., Zhang, J., Yan, Y., Hu, Y., Akagi, M., and Loizou,
P. C. (2011/05). “Comparative intelligibility investigation of single-channel
noise-reduction algorithms for Chinese, Japanese, and English,” J. Acoust.
Soc. Am., 129, 3291-3301.
[7] Li, J., Chau, D. T., Akagi, M., Yang, L., Zhang, J., and Yan, Y. (2010/11/30).
“Intelligibility Investigation of Single-Channel Noise Reduction Algorithms
for Chinese and Japanese,” in: Proc. ISCSLP2010, Tainan, Taiwan.
[8] Li, J., Sakamoto, S., Hongo, S., Akagi, M., and Suzuki, Y. (2009/10/20). "Two-stage binaural speech enhancement with Wiener filter based on equalization-cancellation model," Proc. WASPAA, New Palts, NY, 133-136.
[9] Li, J., Sakamoto, S., Hongo, S., Akagi, M., and Suzuki, Y. (2009/9/21).
"Advancement of two-stage binaural speech enhancement (TS-BASE) for
high-quality speech communication," Proc. WESPAC2009, Beijing, CD-ROM.
[10] Li, J., Fu, Q-J., Jiang, H., and Akagi, M. (2009/04/24). "Psychoacoustically-motivated
adaptive β-order generalized spectral subtraction for cochlear implant
patients," Proc ICASSP2009, 4665-4668.
[11] Li, J., Jiang, H., and Akagi, M. (2008/09/23). "Psychoacoustically-motivated
adaptive β-order generalized spectral subtraction based on data-driven
optimization," Proc. InterSpeech2008, Brisbane, 171-174.
[12] Li, J., Sakamoto, S., Hongo, S., Akagi, M., and Suzuki, Y. (2008/08/16).
"Improved two-stage binaural speech enhancement based on accurate
interference estimation for hearing aids," IHCON2008
[13] Li, J., Sakamoto, S., Hongo, S., Akagi, M., and Suzuki, Y. (2008).
“Adaptive -order generalized spectral subtraction for speech enhancement,”
Signal Processing, vol. 88, no. 11, pp. 2764-2776, 2008.
[14] Li, J., Sakamoto, S., Hongo, S., Akagi, M., and Suzuki, Y. (2008/0630). "A two-stage binaural speech enhancement approach for hearing aids with preserving binaural benefits in noisy environments," Acoustics2008, Paris, 723-727.
[15] Li, J., Akagi, M., and Suzuki, Y. (2008). "A two-microphone noise
reduction method in highly non-stationary multiple-noise-source environments,"
IEICE Trans. Fundamentals, E91-A, 6, 1337-1346.
[16] Li, J. and Akagi, M. (2008). "A hybrid microphone array post-filter
in a diffuse noise field," Applied Acoustics 69, 546-557.
[17] Li, J., Sakamoto, S., Hongo, S., Akagi, M., and Suzuki, Y. (2007). "Noise reduction based on adaptive beta-order generalized spectral subtraction for speech enhancement," Proc. Interspeech2007, 802-805.
[18] Li, J., Akagi, M., and Suzuki, Y. (2006). "Noise reduction based
on microphone array and post-filtering for robust speech recognition,"
Proc. ICSP, Guilin.
[19] Li, J. and Akagi, M. (2006). "Noise reduction method based on
generalized subtractive beamformer," Acoust. Sci. & Tech., 27,
4, 206-215.
[20] Li, J, Akagi, M., and Suzuki, Y. (2006). "Improved hybrid microphone array post-filter by integrating a robust speech absence probability estimator for speech enhancement," Proc. ICSLP2006, Pittsburgh, USA, 2130-2133.
[21] Li, J. and Akagi, M. (2006). "A noise reduction system based
on hybrid noise estimation technique and post-filtering in arbitrary noise
environments," Speech Communication, 48, 111-126.
[22] Li, J., Akagi, M., and Suzuki, Y. (2006). "Noise reduction based
on generalized subtractive beamformer for speech enhancement," WESPAC2006,
Seoul
[23] Li, J. and Akagi, M. (2005). "Theoretical analysis of microphone arrays with postfiltering for coherent and incoherent noise suppression in noisy environments," Proc. IWAENC2005, Eindhoven, The Netherlands, 85-88.
[24] Li, J. and Akagi, M. (2005). "A hybrid microphone array post-filter
in a diffuse noise field," Proc. EuroSpeech2005, Lisbon, Portugal,
2313-2316.
[25] Li, J., Lu, X., and Akagi, M. (2005). "Noise reduction based
on microphone array and post-filtering for robust speech recognition in
car environments," Proc. Workshop DSPinCar2005, S2-9
[26] Li, J., Lu, X., and Akagi, M. (2005). “A noise reduction system in arbitrary noise environments and its application to speech enhancement and speech recognition,” Proc. ICASSP2005, Philadelphia, III-277-280.
[27] Li, J. and Akagi, M. (2005). “Suppressing localized and non-localized
noises in arbitrary noise environments,” Proc. HSCMA2005, Piscataway.
[28] Li, J. and Akagi, M. (2004). “Noise reduction using hybrid noise estimation
technique and post-filtering,” Proc. ICSLP2004, Cheju, Korea.
[29] Akagi, M. and Kago, T. (2002). "Noise reduction using a small-scale microphone array in multi noise source environment," Proc. ICASSP2002, Orlando, I-909-912.
[30] Mizumachi, M., Akagi, M. and Nakamura, S. (2000). "Design of
robust subtractive beamformer for noisy speech recognition," Proc.
ICSLP2000, Beijing, IV-57-60.
[31] Mizumachi, M. and Akagi, M. (2000). "Noise reduction using a
small-scale microphone array under non-stationary signal conditions,"
Proc. WESTPRAC7, 421-424.
[32] Mizumachi, M. and Akagi, M. (1999). "Noise reduction method that is equipped for robust direction finder in adverse environments," Proc. Workshop on Robust Methods for Speech Recognition in Adverse Conditions, Tampere, Finland, 179-182.
[33] 水町、赤木(1999).”マイクロホン対を用いたスペクトルサブトラクションによる雑音除去法”、電子情報通信学会論文誌、J82-A,
4, 503-512.
[34] Mizumachi, M. and Akagi, M. (1998). “Noise reduction by paired-microphones
using spectral subtraction,” Proc. ICASSP98, II, 1001-1004
[35] Akagi, M. and Mizumachi, M. (1997). "Noise Reduction by Paired
Microphones", Proc. EUROSPEECH97, 335-338.
<本(章)>
[1] Li, J., Akagi, M., and Suzuki, Y. (2006). "Multi-channel noise reduction in noisy environments," Chinese Spoken Language Processing, Proc. ISCSLP2006, Springer LNCS 4274, 258-269.
<研究会・大会>
[1] Li, J. and Akagi, M. (2009/3/8). "Intelligibility investigation
of single-channel speech enhancement algorithms using Japanese corpus,"
Proc. ASJ '2010 Spring Meeting, 1-9-3.
[2] Li, J., Sakamoto, S., Hongo, S., Akagi, M., and Suzuki, Y. (2009/9/16).
"Subjective evaluation of TS-BASE/WF for speech enhancement and sound
localization," Proc. ASJ '2009 Fall Meeting, 2-4-3.
[3] Li, J., Yang, L., Zhang, J., Yan, Y., and Akagi, M. (2009/9/16). "Comparative
evaluations of single-channel speech enhancement algorithms on Mandarin
and English speech intelligibility," Proc. ASJ '2009 Fall Meeting,
2-P-24.
[4] Yang, L., Li, J., Zhang, J., Yan, Y., and Akagi, M. (2009/6/26). "Effects of single-channel enhancement algorithms on Mandarin speech intelligibility," IEICE Tech. Report, EA2009-32.
[5] Li, J., Jiang, H., Fu, Q., Sakamoto, S., Hongo, S., Akagi, M., and
Suzuki, Y. (2008/09/12). "Adaptive -order generalized spectral subtraction-based
speech enhancement for cochlear implant patients," Proc. ASJ '2008
Fall Meeting, 3-8-5.
[6] Li, J., Sakamoto, S., Hongo, S., Akagi, M., and Suzuki, Y. (2008/3/19).
"A two-stage binaural speech enhancement approach with adaptive filter
and Wiener filter: Theory, implementation and evaluation," Proc. ASJ
'2008 Spring Meeting, 3-6-8.
[7] Li, J., Sakamoto, S., Hongo, S., Akagi, M., and Suzuki, Y. (2007). "A speech enhancement approach for binaural hearing aids," Proc. 22th SIP Symposium, Sendai, 263-268.
[8] Li, J., Sakamoto, S., Hongo, S., Akagi, M., and Suzuki, Y. (2006).
"Adaptive beta-order generalized spectral subtraction for speech enhancement,"
Tech. Report of IEICE, EA2006-42.
[9] Li, J. and Akagi, M. (2005). “A noise reduction method based on a
generalized subtractive beamformer,” Tech. Report of IEICE, EA2005-44.
[10] Li, J. and Akagi, M. (2004). “A noise reduction system in localized and non-localized noise environments,” Tech. Report of IEICE, EA2004-34.
[11] 水町、赤木(1997).”複数マイクロホンを用いたスペクトルサブトラクションによる雑音除去法”、電子情報通信学会技術報告、SP97-35.
[12] 赤木、水町(1997).”マイクロホン対を用いた雑音除去法(NORPAM)”、電子情報通信学会技術報告、SP97-34.
[13] 今田、赤木(1996).”2点受音波形からの音源分離”、平成8年春季音響学会講演論文、3-3-14.
2-2 雑音中のF0推定
<査読付論文・国際会議>
[1] Ishimoto, Y., Akagi, M., Ishizuka, K., and Aikawa, K. (2004). “Fundamental
frequency estimation for noisy speech using entropy-weighted periodic and
harmonic features,” IEICE Trans. Inf. & Syst., E87-D, 1, 205-214.
[2] Ishimoto, Y., Unoki, M., and Akagi, M. (2001). "A fundamental
frequency estimation method for noisy speech based on instantaneous amplitude
and frequency", Proc. EUROSPEECH2001, Aalborg, 2439-2442.
[3] Ishimoto, Y., Unoki, M., and Akagi, M. (2001). "A fundamental frequency estimation method for noisy speech based on instantaneous amplitude and frequency ", Proc. CRAC, Aalborg.
[4] Ishimoto, Y., Unoki, M., and Akagi, M. (2001). "A fundamental
frequency estimation method for noisy speech based on periodicity and harmonicity",
Proc. ICASSP2001, SPEECH-SF3, Salt Lake City.
[5] Ishimoto, Y. and Akagi, M. (2000). "A fundamental frequency estimation
method for noisy speech," Proc. WESTPRAC7, 161-164.
<研究会・大会>
[1] 鵜木,石本,赤木(2005).”残響音声からの基本周波数推定に関する検討”,JAIST Tech. Report, IS-RR-2005-007.
[2] Ishimoto, Y., Unoki, M., and Akagi, M. (2005). "Fundamental frequency
estimation for noisy speech based on instantaneous amplitude and frequency,"
JAIST Tech. Report, IS-RR-2005-006.
[3] 石本,鵜木,赤木(2004) .“時間情報と周波数情報を用いた実環境雑音下における基本周波数推定”,電子情報通信学会技術報告、SP2003-201.
[4] 石本、鵜木、赤木(2001).”瞬時振幅の周期性と調波性を考慮した雑音環境における基本周波数推定”、話し言葉の科学と工学ワークショップ講演予稿集、149-156.
[5] 石本、鵜木、赤木(2000).”周期性と調波性を考慮した雑音環境における基本周波数推定”、音響学会聴覚研究会資料、H-2000-81.
[6] 石本、赤木(2000).”雑音が付加された音声の基本周波数推定と雑音抑圧”、電子情報通信学会技術報告、SP99-169.
2-3 残響抑圧
<査読付論文・国際会議>
[1] Morita, S., Unoki, M., Lu, X., and Akagi, M. (2015/06/11). “Robust
Voice Activity Detection Based on Concept of Modulation Transfer Function
in Noisy Reverberant Environments,” Journal of Signal Processing Systems,
DOI 10.1007/s11265-015-1014-4
[2] Morita, S., Unoki, M., Lu, X., and Akagi, M. (2014/09/13). “Robust
Voice Activity Detection Based on Concept of Modulation Transfer Function
in Noisy Reverberant Environments,” Proc. ISCSLP2014, Singapore, 108-112.
[3] Unoki, M., Ikeda, T., Sasaki, K., Miyauchi, R., Akagi, M., and Kim, N-S. (2013/07/08). “Blind method of estimating speech transmission index in room acoustics based on concept of modulation transfer function,” Proc. ChinaSIP2013, Beijing, 308-312.
[4] Sasaki, Y. and Akagi, M. (2012/03/05), “Speech enhancement technique
in noisy reverberant environment using two microphone arrays,” Proc. NCSP2012,
Honolulu, HW, 333-336.
[5] Unoki, M., Lu, X., Petrick, R., Morita, S., Akagi, M., and Hoffmann
R. (2011/08/30). “Voice activity detection in MTF-based power envelope
restoration,” Proc. INTERSPEECH 2011, Florence, Italy, 2609-2612.
[6] Unoki, M., Ikeda, T., and Akagi, M. (2011/06/27). “Blind estimation method of speech transmission index in room acoustics,” Proc. Forum Acousticum 2011, Aalborg, Denmark, 1973-1978.
[7] Morita, S., Lu, X., Unoki, M., and Akagi, M. (2011/03/02). “Study on
MTF-based power envelope restoration in noisy reverberant environments,”
Proc. NCSP2011, Tianjin, China, 247-250.
[8] Ikeda, T., Unoki, M., and Akagi, M. (2011/03/02). “Study on blind estimation
of Speech Transmission Index in room acoustics,”Proc. NCSP2011, Tianjin,
China, 235-238.
[9] Morita, S., Unoki, M., and Akagi, M. (2010/07/01). “A study on the IMTF-based filtering on the modulation spectrum of reverberant signal,” Journal of Signal Processing, 14, 4, 269-272.
[10] Li, J. Sasaki, Y., Akagi, M. and Yan, Y. (2010/03/04). "Experimental
evaluations of TS-BASE/WF in reverberant conditions," Proc. NCSP10,
Hawaii, USA, 269-272.
[11] Morita, S., Unoki, M., and Akagi, M. (2010/03/04). "A study on
the MTF-based inverse filtering for the modulation spectrum of reverberant
speech," Proc. NCSP10, Hawaii, USA, 265-268.
[12] Unoki, M., Yamasaki, Y., and Akagi, M. (2009/08/25). “MTF-based power envelope restoration in noisy reverberant environments,” Proc. EUSIPCO2009, Glasgow, Scotland, 228-232.
[13] Petric, R., Lu, X., Unoki, M., Akagi, M., and Hoffmann, R. (2008/09/24).
"Robust front end processing for speech recognition in reverberant
environments: Utilization of speech characteristics," Proc. InterSpeech2008,
Brisbane, 658-661.
[14] Unoki, M., Toi, M., and Akagi, M. (2006). "Refinement of an
MTF-based speech dereverberation method using an optimal inverse-MTF filter,"
SPECOM2006, St. Petersburg, 323-326.
[15] Unoki, M., Toi, M., and Akagi, M. (2005). “Development of the MTF-based speech dereverberation method using adaptive time-frequency division,” Proc. Forum Acousticum 2005, 51-56.
[16] Toi, M., Unoki, M. and Akagi, M. (2005). “Development of adaptive
time-frequency divisions and a carrier reconstruction in the MTF-based
speech dereverberation method,” Proc. NCSP05, Hawaii, 355-358.
[17] Unoki, M., M., Sakata, Furukawa, K. and Akagi, M. (2004). “A speech
dereverberation method based on the MTF concept in power envelope restoration,”
Acoust. Sci. & Tech., 25, 4, 243-254.
[18] Unoki, M., Furukawa, M., Sakata, K. and Akagi, M. (2004). “An improved method based on the MTF concept for restoring the power envelope from a reverberant signal,” Acoust. Sci. & Tech., 25, 4, 232-242.
[19] Unoki, M., Toi, M., and Akagi, M. (2004). “A speech dereverberation
method based on the MTF concept using adaptive time-frequency divisions,”
Proc. EUSIPCO2004, 1689-1692.
[20] Unoki, M., Sakata, K., Toi, M., and Akagi, M. (2004). “Speech dereverberation
based on the concept of the modulation transfer function,” Proc. NCSP2004,
Hawaii, 423-426.
[21] Unoki, M., Sakata, K. and Akagi, M. (2003). “A speech dereverberation method based on the MTF concept,” Proc. EUROSPEECH2003, Geneva, 1417-1420.
[22] Unoki, M., Furukawa, M., Sakata, K., and Akagi, M. (2003). "A
method based on the MTF concept for dereverberating the power envelope
from the reverberant signal," Proc. ICASSP2003, Hong Kong, I-840-843.
[23] Unoki, M., Furukawa, M., and Akagi, M. (2002). "A method for
recovering the power envelope from reverberant speech," SPA-Gen-002,
Forum Acousticum Sevilla 2002.
<研究会・大会>
[1] 石川,小林,赤木,鵜木 (2017/03/15). “室内インパルス応答のモデル化とその室内音響特性”, 日本音響学会平成29年度春季研究発表会,
1-P-19.
[2] 鵜木,石川,柏原,小林,赤木 (2016/11/17). “室内インパルス応答のモデル化とその室内音響特性の検討”, 電子情報通信学会技術報告,EA2016-67.
[3] 鵜木 祐史,森田 将太,宮崎 晃和,赤木 正人 (2015/09/16). “雑音残響環境における室内音響パラメータのブラインド推定法の検討”,日本音響学会平成27年度秋季研究発表会, 1-6-11.
[4] 鵜木,森田,宮崎,赤木 (2015/07/22). “雑音残響環境における音声伝達指標の推定と音声回復処理”,音響学会聴覚研究会資料,45,
5, H-2015-80.
[5] 森田,鵜木,ルー,赤木. (2014/05/24). “変調伝達関数に基づく雑音残響に頑健な音声区間検出法:帯域分割型SNR推定法の利用”,
電子情報通信学会技術報告,SP2014-41.
[6] 森田,鵜木,ルー,赤木. (2014/03/12). “PRISM の総合評価:PRISM をフロントエンドとした音声認識性能”,日本音響学会平成26年春季研究発表会,3-Q5-25.
[7] 森田,鵜木,赤木 (2013/09/25). “雑音残響にロバストな音声区間検出法の検討”,日本音響学会平成25年度秋季研究発表会,
1-P-22b.
[8] 鵜木,佐々木,宮内,赤木 (2013/07/18). “残響音声からの音声伝達指標のブラインド推定法の検討”, 電子情報通信学会技術報告,EA-2013-44.
[9] 鵜木,Lu, S.,Reco, P.,森田,赤木,Hoffman, R. (2012/05/24). “変調伝達関数に基づいたパワーエンベロープ回復処理における音声区間検出の検討”, 電子情報通信学会技術報告,EA-2012-2.
[10] 佐々木,赤木 (2012/03/13). “二チャンネルマイクロホンアレイによる雑音残響環境下音声強調手法”, 日本音響学会平成24年春季研究発表会,1-Q-7.
[11] 佐々木,赤木 (2011/10/01). “残響環境下におけるTS-BASE/WFの性能評価 TS-BASE/WFの改良手法についての検討”,音響学会聴覚研究会資料,41,
7, H-2011-101.
[12] 鵜木,森田,Lu,赤木 (2011/09/22). “残響にロバストな音声区間検出法とその比較評価”, 日本音響学会平成23年秋季研究発表会, 3-P-1.
[13] 鵜木,池田,宮内,赤木(2011/07/15).“変調伝達関数の概念に基づいた音声伝達指標のブラインド推定法の検討”,電子情報通信学会技術報告,EA2011-47.
[14] 鵜木,森田,澤口,赤木.(2011/03/10). “MTF に基づいたパワーエンベロープ回復処理による音声区間検出の検討”,日本音響学会平成23年春季研究発表会,2-P-26.
[15] 森田,Lu,鵜木,赤木.(2011/03/10). “雑音残響にロバストな音声認識のための帯域分割型パワーエンベロープ回復処理の検討”,日本音響学会平成23年春季研究発表会,2-P-16.
[16] 池田,鵜木,赤木.(2011/03/09). “MTF の概念に基づいた音声伝達指標のブラインド推定法に関する研究”,日本音響学会平成23年春季研究発表会,1-12-1.
[17] 森田,山崎,鵜木,赤木 (2010/10/21).“雑音残響環境下におけるMTFに基づくパワーエンベロープ回復処理の検討”,電子情報通信学会技術報告,EA2010-78.
[18] 鵜木祐史,山崎 悠,赤木正人 (2010/3/9).“雑音残響環境下におけるMTF ベース・パワーエンベロープ回復処理の検討”,日本音響学会平成22年春季研究発表会, 2-P-27.
[19] 森田翔太,鵜木祐史,赤木正人 (2010/3/9).“変調伝達関数に基づいた変調スペクトル逆フィルタ処理の検討”,日本音響学会平成22年春季研究発表会,
2-P-21.
[20] Petric, R., Lu, X., Unoki, M., Akagi, M., and Hoffmann, R. (2008).
"Robust front end processing for speech recognition in reverberant
environments: Utilization of Speech Properties," 電子情報通信学会技術報告、SP2008-44.
[21] Uniki, M., Toi, M., Shibano, Y., and Akagi, M. (2006). "Suppression of speech intelligibility loss through a modulation transfer function-based speech dereverberation method," J. Acoust. Soc. Am., 120, 5, Pt. 2, 3360.
[22] 鵜木,戸井,赤木(2005).”変調伝達関数に基づいた残響音声回復法の改良と総合評価”,音響学会聴覚研究会資料、H-2005-55
[23] 戸井、鵜木、赤木(2004).“適応的な時間‐周波数分割を考慮した残響音声回復法の改良”,音響学会聴覚研究会資料、H-2004-66.
[24] 酒田,鵜木,赤木(2003).”MTFに基づいた残響音声の回復法の検討”、電子情報通信学会技術報告、SP2002-181.
[25] 古川、鵜木、赤木(2002).”MTFに基づいた残響音声パワーエンベロープの回復方法”、電子情報通信学会技術報告、SP2002-15.
2-4 骨導音声
<査読付論文・国際会議>
[1] Phung, T. N., Unoki, M., and Akagi, M. (2012/09/01). “A study on restoration
of bone-conducted speech in noisy environments with LP-based model and
Gaussian mixture model,” Journal of Signal Processing, 16, 5, 409-417.
[2] Phung, T. N., Unoki, M. and Akagi, M. (2010/12/14). “Improving Bone-Conducted
Speech Restoration in noisy environment based on LP scheme,” Proc. APSIPA2010,
Student Symposium, 12.
[3] Kinugasa, K., Unoki, M., and Akagi, M. (2009/07/01). "An MTF-based method for Blind Restoration for Improving Intelligibility of Bone-conducted Speech," Journal of Signal Processing, 13, 4, 339-342.
[4] Kinugasa, K., Unoki, M., and Akagi, M. (2009/6/24). "An MTF-based
method for blindly restoring bone-conducted speech," Proc. SPECOM2009,
St. Petersburg, Russia, 199-204.
[5] Kinugasa, K., Unoki, M., and Akagi, M. (2009/03/01). "An MTF-based
Blind Restoration Method for Improving Intelligibility of Bone-conducted
Speech," Proc. NCSP'09, 105-108.
[6] Vu, T. T. Unoki, M. and Akagi, M. (2008/6/5). "An LP-based blind model for restoring bone-conducted speech," Proc. ICCE2008, 212-217.
[7] Vu, T. T., Unoki, M., and Akagi, M. (2008/3/7). "A study of blind
model for restoring bone-conducted speech based on liner prediction scheme,"
Proc. NCSP08, 287-290.
[8] Vu, T. T. Unoki, M. and Akagi, M. (2007). “The Construction of Large-scale
Bone-conducted and Air-conducted Speech Databases for Speech Intelligibility
Tests,” Proc. Oriental COCOSDA2007, 88-91.
[9] Vu, T. T., Unoki, M., and Akagi, M. (2007). "A blind restoration model for bone-conducted speech based on a linear prediction scheme," Proc. NOLTA2007, Vancouver, 449-452.
[10] Vu, T. T., Seide, G., Unoki, M., and Akagi, M. (2007). "Method
of LP-based blind restoration for improving intelligibility of bone-conducted
speech," Proc. Interspeech2007, 966-969.
[11] Vu, T., Unoki, M., and Akagi, M. (2006). "A Study on Restoration
of Bone-Conducted Speech with MTF-Based and LP-based Models," Journal
of Signal Processing, 10, 6, 407-417.
[12] Vu, T., Unoki, M., and Akagi, M. (2006). "A study on an LP-based model for restoring bone-conducted speech," Proc. HUT-ICCE2006, Hanoi.
[13] Vu, T. T., Unoki, M., and Akagi, M. (2006). "A study on an LPC-based
restoration model for improving the voice-quality of bone-conducted speech,"
Proc. NCSP2006, 110-113.
[14] Kimura, K., Unoki, M. and Akagi, M. (2005). “A study on a bone-conducted
speech restoration method with the modulation filterbank,” Proc. NCSP05,
Hawaii, 411-414.
<研究会・大会>
[1] 鵜木,フンチュンニア,赤木.(2011/03/09). “線形予測に基づいた骨導音声回復法の改良とその総合評価”,日本音響学会平成23年春季研究発表会,1-Q-31.
[2] Phung, T. N., Unoki, M., and Akagi, M. (2010/06/11). “Comparative evaluation
of bone-conducted-speech restoration based on linear prediction scheme,”
IEICE Tech. Report, EA2010-31.
[3] 衣笠,鵜木,赤木(2009/6/26).”変調伝達関数に基づいた骨導音声ブラインド回復法の検討”,電子情報通信学会技術報告,EA2009-31.
[4] 衣笠,Lu,Vu,鵜木,赤木(2008/09/10).”線形予測分析に基づいた骨導音声ブラインド回復法の総合評価:Lombard 効果による影響について”,日本音響学会平成20年秋季研究発表会, 1-R-8.
[5] 鵜木,ルー,ヴ,衣笠,赤木 (2008/06/27).”線形予測分析に基づいた骨導音声ブラインド回復法の総合的評価”,電子情報通信学会技術報告、SP2008-24.
[6] Vu, T. T., Unoki, M., and Akagi, M. (2008/3/20) "A study on the
LP-based blind model in restoring bone-conducted speech," Asian Student
workshop, Tokyo SP2007-189
[7] Unoki M., Vu T. T., Seide J., and Akagi, M. (2007). "Evaluation of an LP-based blind restoration method to improve intelligibility of BC speech," 電子情報通信学会技術報告、SP2007-41.
[8] Vu T. T., Unoki M., and Akagi, M. (2007). "An LP-based blind restoration
method for improving intelligibility of bone-conducted speech," 電子情報通信学会技術報告、SP2006-172.
[9] Vu, T., Unoki, M., and Akagi, M. (2006). "A parameter estimation
method for a bone-conducted speech restoration based on the linear presiction,"
Trans. Tech. Comm. Psychol. Physiol. Acoust., ASJ, 36, 7, H-2006-104.
[10] 鵜木,木村,赤木(2005).“変調伝達特性に着目した骨導音声回復法の検討”,音響学会聴覚研究会資料、H-2005-33
2-5 音声認識
<査読付論文・国際会議>
[1] Du, Y. and Akagi, M. (2014/03/02). “Speech recognition in noisy conditions
based on speech separation using Non-negative Matrix Factorization,” Proc.
NCSP2014, Hawaii, USA, 429-432.
[2] Haniu, A., Unoki, M., and Akagi, M. (2009/9/21). "A psychoacoustically-motivated
conceptual model for automatic speech recognition," Proc. WESPAC2009,
Beijing, CD-ROM.
[3] Lu, X., Unoki, M., and Akagi, M. (2008/11/1). "Comparative evaluation of modulation-transfer-function-based blind restoration of sub-band power envelopes of speech as a front-end processor for automatic speech recognition systems," Acoustical Science and Technology, 29, 6, 351-361.
[4] Lu, X., Unoki, M., and Akagi, M. (2008/07/01). "An MTF-based blind
restoration for temporal power envelopes as a front-end processor for automatic
speech recognition systems in reverberant environments," Acoustics2008,
Paris, 1419-1424.
[5] Haniu, A., Unoki, M., and Akagi, M. (2008/3/6). "A speech recognition
method based on the selective sound segregation in various noisy environments,"
Proc. NCSP08, 168-171.
[6] Haniu, A., Unoki, M. and Akagi, M. (2007). "A study on a speech recognition method based on the selective sound segregation in various noisy environments," Proc. NOLTA2007, Vancouver, 445-448.
[7] Haniu, A., Unoki, M. and Akagi, M. (2007). "A study on a speech
recognition method based on the selective sound segregation in noisy environment,"
Proc. JCA2007, CD-ROM.
[8] Lu, X., Unoki, M., and Akagi, M. (2006). "A robust feature extraction
based on the MTF concept for speech recognition in reverberant environment,"
Proc. ICSLP2006, Pittsburgh, USA, 2546-2549.
[9] Lu, X., Unoki, M., and Akagi, M. (2006). "MTF-based sub-band power envelope restoration in reverberant environment for robust speech recognition, "Proc. NCSP2006, 162-165.
[10] Haniu, A., Unoki, M. and Akagi, M. (2005). “A study on a speech recognition method based on the selective sound segregation in noisy environment,” Proc. NCSP05, Hawaii, 403-406.
<解説・招待講演>
[1] 赤木,羽二生.(2011/03/09). “音声の知覚と認識 -人は脳で音声を聞く.機械は?-”,日本音響学会平成23年春季研究発表会,1-13-2 (招待講演).
<研究会・大会>
[1] 羽二生,鵜木,赤木 (2009/6/25).“ヒトの聴覚情報処理過程を考慮した音声認識モデル”,電子情報通信学会技術報告,SP2009-33.
[2] Haniu, A., Unoki, M., and Akagi, M. (2008/3/20) "Improvement of
robustness using selective sound segregation for automatic speech recognition
systems in noisy environments," Asian Student workshop, Tokyo SP2007-196
[3] Lu, X., Unoki, M., and Akagi, M. (2008/3/17), "Comparative evaluation of modulation transfer function based dereverberation for robust speech recognition," Proc. ASJ '2008 Spring Meeting, 1-10-12.
[4] 羽二生,鵜木,赤木(2008/3/17).”雑音環境における選択的音源分離を規範とした音声認識”,日本音響学会平成20年春季研究発表会,
1-Q-1.
[5] Lu, X., Unoki, M., and Akagi, M. (2006). "Sub-band temporal envelope
restoration for ASR in reverberation environment," Proc. Int. Sympo.
Frontiers in Speech and Hearing Research, 73-78
[6] 羽二生,鵜木,赤木(2004).“雑音環境下における音源分離を認識規範とした音声認識法の提案”,電子情報通信学会技術報告、SP2004-31.
2-6 音源方向推定
<査読付論文・国際会議>
[1] Chau, D. T., Li, J., and Akagi, M. (2014/10/01). “Binaural sound source localization in noisy reverberant environments based on Equalization-Cancellation Theory,” IEICE Trans. Fund., E97-A, 10, 2011-2020.
[2] Chau, D. T., Li, J., and Akagi, M. (2013/07/08). “Improve equalization-cancellation-based
sound localization in noisy reverberant environments using direct-to-reverberant
energy ratio,” Proc. ChinaSIP2013, Beijing, 322-326.
[3] Chau, D. T., Li, J., and Akagi, M. (2011/07/01). “Towards intelligent
binaural speech enhancement by meaningful sound extraction,” Journal of
Signal Processing, 15, 4, 291-294.
[4] Chau, D. T., Li, J., and Akagi, M. (2011/03/03). “Towards an intelligent binaural speech enhancement system by integrating meaningful signal extraction,”Proc. NCSP2011, Tianjin, China, 344-347.
[5] Chau, D. T., Li, J., and Akagi, M. (2010/09/30). "A DOA estimation algorithm based on equalization-cancellation theory," Proc. INTERSPEECH2010, Makuhari, 2770-2773.
<研究会・大会>
[1] Chau, D. T., Li, J., and Akagi, M. (2014/03/28). “Binaural sound source
localization in noisy reverberant environments based on Equalization-Cancellation
Theory,” IEICE Tech. Report, EA2013-123.
[2] Chau, D. T., Li, J., and Akagi, M. (2013/05/16). “Adaptive equalization-cancellation model and its application to sound localization in noisy reverberant environments,” IEICE Tech. Report, EA2013-24, SP-2013-24.
[3] Chau, T. D., Li, J. and Akagi, M. (2013/03/13). “Binaural multiple-source
localization in noisy reverberant environments based on Equalization-Cancellation
model,” Proc. ASJ '2013 Spring Meeting, 1-P-44.
[4] Chau, D. T., Li, J., and Akagi, M. (2010/06/11). “A DOA estimation
algorithm based on equalization-cancellation theory,” IEICE Tech. Report,
EA2010-28.
[5] 小林、西田、赤木(2001).”雑音と反射音に対してロバストな話者方向推定法”、平成13年春季音響学会講演論文、2-7-9.
3.カクテルパーティ効果のモデル化
3-1 音源分離
<査読付論文・国際会議>
[1] Unoki, M., Kubo, M., Haniu, A., and Akagi, M. (2006). "A Model-Concept
of the Selective Sound Segregation: — A Prototype Model for Selective Segregation
of Target Instrument Sound from the Mixed Sound of Various Instruments
—," Journal of Signal Processing, 10, 6, 419-431.
[2] Unoki, M., Kubo, M., Haniu, A., and Akagi, M. (2005). "A model
for selective segregation of a target instrument sound from the mixed sound
of various instruments," Proc. EuroSpeech2005, Lisbon, Portugal, 2097-2100.
[3] Unoki, M., Kubo, M., and Akagi, M. (2003). “A model for selective segregation of a target instrument sound from the mixed sound of various instruments,” Proc. ICMC2003, Singapore, 295-298.
[4] Akagi, M., Mizumachi, M.,Ishimoto, Y., and Unoki, M. (2000). "Speech
enhancement and segregation based on human auditory mechanisms", Proc.
IS2000, Aizu, 246-253.
[5] 鵜木、赤木(1999).”聴覚の情景解析に基づいた雑音下の調波複合音の一抽出法”、電子情報通信学会論文誌、J82-A, 10, 1497-1507.
[6] Unoki, M. and Akagi, M. (1999). "Segregation of vowel in background noise using the model of segregating two acoustic sources based on auditory scene analysis", Proc. EUROSPEECH99, 2575-2578.
[7] Unoki, M. and Akagi, M. (1999). "Segregation of vowel in background
noise using the model of segregating two acoustic sources based on auditory
scene analysis", Proc. CASA99, IJCAI-99, Stockholm, 51-60.
[8] Akagi, M., Iwaki, M. and Sakaguchi, N. (1998). “Spectral sequence compensation
based on continuity of spectral sequence,” Proc. ICSLP98, Sydney, Vol.4,
1407-1410.
[9] Unoki, M. and Akagi, M. (1998). “Signal extraction from noisy signal based on auditory scene analysis,” ICSLP98, Sydney, Vol.5, 2115-2118.
[10] Unoki, M. and Akagi, M. (1998). “A method of signal extraction from
noisy signal based on auditory scene analysis,” Speech Communication, 27,
3-4, 261-279.
[11] Unoki, M. and Akagi, M. (1997). "A method of signal extraction
from noisy signal", Proc. EUROSPEECH97, 2587-2590.
[12] Unoki, M. and Akagi, M. (1997). "A method of signal extraction from noisy signal based on auditory scene analysis", Proc. CASA97, IJCAI-97, Nagoya, 93-102.
[13] Unoki, M. and Akagi, M. (1997). “A method for signal extraction from
noise-added signals”, Electronics and Communications in Japan, Part 3,
80, 11, 1-11.
[14] 鵜木、赤木(1997).”雑音が付加された波形からの信号波形の一抽出法”、電子情報通信学会論文誌、J80-A, 3, 444-453.
<本(章)>
[1] Akagi, M., Mizumachi, M., Ishimoto, Y., and Unoki, M. (2002). "Speech enhancement and segregation based on human auditory mechanisms", in Enabling Society with Information Technology, Q. Jin, J. Li, N. Zhang, J. Cheng, C. Yu, and S. Noguchi (Eds.), Springer Tokyo, 186-196
<解説・招待講演>
[1] 赤木正人(2002).”人間の聴覚特性を考慮した音声分離・強調”,電子情報通信学会技術報告(ビギナーズセミナー招待講演),SP2002-55
[2] 赤木正人(1995).”カクテルパーティ効果とそのモデル化”、電子情報通信学会誌解説, 78, 5, 450-453.
<研究会・大会>
[1] 窪,鵜木,赤木(2002).“楽器音の音響的特徴を知識として利用した選択的分離抽出法”,音響学会聴覚研究会資料、H-2002-90
[2] 鵜木、赤木(1999).”聴覚の情景解析に基づいた二波形分離モデルの提案”、電子情報通信学会技術報告、SP98-158.
[3] 鵜木、赤木(1998).“共変調マスキング解除の計算モデルの提案”、音響学会聴覚研究会資料、H-98-51
[4] Unoki, M. and Akagi, M. (1998). “A method of signal extraction from noisy signal based on auditory scene analysis,” JAIST Tech. Report, IS-RR-98-0005P.
[5] 鵜木、赤木(1998).”基本周波数の時間変動を考慮した調波複合音の抽出法”、電子情報通信学会技術報告、SP97-129.
[6] 坂口、赤木(1998).”スペクトルピーク追跡モデルを用いたスペクトル予測・追跡”、平成10年春季音響学会講演論文、1-8-14.
[7] 鵜木、赤木(1997).”帯域雑音中のAM調波複合音の一抽出法”、電子情報通信学会技術報告、SP96-123.
[8] 鵜木祐史、赤木正人(1996).”共変調マスキング解除の計算モデルに関する一考察”、電子情報通信学会技術報告、SP96-37.
[9] 鵜木、赤木(1995).”雑音が付加された波形からの信号波形の抽出法”、音響学会聴覚研究会資料、H-95-79
[10] 井川、赤木 (1994).”位相の変化に着目した2波形分離法”、平成6年春季音響学会講演論文、3-4-15
3-2 プライバシー保護
<査読付論文・国際会議>
[1] 赤木正人,入江佳洋 (2014/04/01). “音情景解析の概念にもとづいた音声プライバシー保護”,電子情報通信学会論文誌 A, J97-A,
4, 247-255.
[2] Akagi, M. and Irie, Y. (2012/08/22). “Privacy protection for speech
based on concepts of auditory scene analysis,” Proc. INTERNOISE2012, New
York, 485.
[3] Tezuka, T. and Akagi, M. (2008/3/6). "Influence of spectrum envelope on phoneme perception," Proc. NCSP08, 176-179.
[4] Minowa A., Unoki M., and Akagi M. (2007). "A study on physical conditions for auditory segregation/integration of speech signals based on auditory scene analysis," Proc. NCSP2007, 313-316.
<招待講演>
[1] 赤木,入江 (2012/03/14). “カクテルパーティ効果とスピーチプライバシー保護”,日本音響学会平成24年春季研究発表会,2-2-3(招待講演).
[2] 赤木,入江 (2011/12/09). “音情景理解を応用した音声プライバシー保護”, 電子情報通信学会技術報告,EMM2011-59.
(招待講演)
<研究会・大会>
[1] 太長根,赤木,入江(2005).“音源の知覚的融合にもとづいた会話のプライバシー保護の検討”,平成17年春季音響学会講演論文、1-2-3.
3-3 雑音中の音知覚
<査読付論文・国際会議>
[1] Yano, Y., Miyauchi, R., Unoki, M., and Akagi, M. (2012/03/06). “Study on detectability of signals by utilizing differences in their amplitude modulation,” Proc. NCSP2012, Honolulu, HW, 611-614.
[2] Yano, Y., Miyauchi, R., Unoki, M., and Akagi, M. (2011/03/02). “Study
on detectability of target signal by utilizing differences between movements
in temporal envelopes of target and background signals,” Proc. NCSP2011,
Tianjin, China, 231-234.
[3] Mizukawa, S. and Akagi, M. (2011/03/02). “A binaural model accounting
for spatial masking release,” Proc. NCSP2011, Tianjin, China, 179-182.
[4] Naoki Kuroda, Junfeng Li, Yukio Iwaya, Masashi Unoki, and Masato Akagi, “Effects of spatial cues on detectability of alarm signals in noisy environments,” Proc. IWPASH2009, P7. Zaou, Japan, Nov. 2009 (CDROM).
[5] Kuroda, N., Li, J., Iwaya, Y., Unoki, M., and Akagi, M. (2009/03/01).
"Effects from Spatial Cues on Detectability of Alarm Signals in Car
Environments," Proc. NCSP'09, 45-48.
[6] Kusaba, M., Unoki, M., and Akagi, M. (2008/3/6). "A study on detectability
of target signal in background noise by utilizing similarity of temporal
envelopes in auditory search," Proc. NCSP08, 13-16.
[7] Uchiyama, H., Unoku, M., and Akagi, M. (2007). "Improvement in detectability of alarm signals in noisy environments by utilizing spatial cues," Proc. WASPAA2007, New Paltz, NY, pp.74-77.
[8] Uchiyama H., Unoki M., and Akagi M. (2007). "A study on perception
of alarm signal in car environments," Proc. NCSP2007, 389-392.
[9] Nakanishi, J., Unoki, M., and Akagi, M. (2006). "Effect of ITD
and component frequencies on perception of alarm signals in noisy environments,"
Journal of Signal Processing, 10, 4, 231-234.
[10] Nakanishi, J., Unoki, M., and Akagi, M. (2006). "Effect of ITD
and component frequencies on perception of alarm signals in noisy environments,"
Proc. NCSP2006, 37-40.
<本(章)>
[1] Kuroda, N., Li, J., Iwaya, Y., Unoki, M., and Akagi, M. (2011). “Effects of spatial cues on detectability of alarm signals in noisy environments,” In Principles and applications of spatial hearing (Eds. Suzuki, Y., Brungart, D., Iwaya, Y., Iida, K., Cabrera, D., and Kato, H.), World Scientific, 484-493.
<研究会・大会>
[1] 矢野,宮内,鵜木,赤木 (2012/03/14). “音信号の振幅変調成分の違いが音の聴き取りやすさに与える影響”,日本音響学会平成24年春季研究発表会,2-8-8.
[2] 矢野,宮内,鵜木,赤木 (2012/02/04). “振幅変調成分の動きの知覚と検出に関する研究”,音響学会聴覚研究会資料,42, 1, H-2012-11.
[3] 矢野,宮内,鵜木,赤木(2011/09/17). “目的音と背景音の振幅包絡の動きの違いが目的音の検知されやすさに与える影響”,平成23電気関係学会北陸支部連合大会,G-5.
[4] 水川,赤木(2011/03/). “方向性マスキング解除を説明する両耳聴モデルの提案”,日本音響学会平成23年春季研究発表会,3-P-56.
[5] 矢野,宮内,鵜木,赤木.(2011/03/11). “背景音に対する目的音の振幅包絡の動きの違いが目的音検知に与える影響”,日本音響学会平成23年春季研究発表会,3-P-18.
[6] 黒田,李,岩谷,鵜木,赤木 (2009/03/06). ”方向性の手掛かりが雑音環境下での報知音の検知能力に及ぼす影響”,電子情報通信学会技術報告、SP2008-149.
[7] 内山,鵜木,赤木(2007).”方向性の手がかりを利用した雑音環境下での報知音の知覚能力の向上”,電子情報通信学会技術報告、SP2007-27.
4.聴覚心理
<招待講演>
[1] 赤木正人 (2011/10/02). “聴覚と音研究”,音響学会聴覚研究会資料,41, 7, H-2011-104.(招待講演)
4-1 聴覚モデル
<査読付論文・国際会議>
[1] Unoki, M. and Akagi, M. (2001). "A computational model of co-modulation masking release," in Computational Models of Auditory Function, (Eds. Greenberg, S. and Slaney, M.), NATO ASI Series, IOS Press, Amsterdam, 221-232.
<招待講演>
[1] 赤木正人 (1993).”音声の知覚と聴覚モデル”、電子情報通信学会技術報告(ビギナーズセミナー招待講演)、SP93-47
<研究会・大会>
[1] Unoki, M. and Akagi, M. (1998). “A computational model of co-modulation
masking release,” Computational Hearing, Italy, 129-134.
[2] Unoki, M. and Akagi, M. (1998). “A computational model of co-modulation
masking release,” JAIST Tech. Report, IS-RR-98-0006P.
4-2 文脈効果
<査読付論文・国際会議>
[1] 米沢、赤木(1997).”文脈効果のモデル化とそれを用いたワードスポッティング”、電子情報通信学会論文誌、J80-D-II, 1, 36-43.
[2] Yonezawa, Y. and Akagi, M. (1996). "Modeling of contextual effects and its application to word spotting", Proc. Int. Conf. Spoken Lang. Process. 96, 2063-2066.
[3] Akagi, M., van Wieringen, A. and Pols, L. C. W. (1994). "Perception of central vowel with pre- and post-anchors", Proc. Int. Conf. Spoken Lang. Process. 94, 503-506.
<本(章)>
[1] Akagi, M. (1992). "Psychoacoustic evidence for contextual effect models", Speech Perception, Production and Linguistic Structure, IOS Press, Amsterdam, 63-78
<研究会・大会>
[1] 米沢、赤木(1997).”発話速度を考慮した文脈効果のモデル化”、電子情報通信学会技術報告、SP97-33.
[2] 萩原、米沢、赤木(1996).”文脈効果の大きさと音韻性の関係について”、電子情報通信学会技術報告、SP95-139.
[3] 米沢、赤木(1995).”文脈効果モデルを用いたワードスポッティング”、電子情報通信学会技術報告、SP95-108.
[4] 米沢、赤木 (1995).”最小分類誤り学習による文脈効果モデルの定式化”、電子情報通信学会技術報告、SP94-114
[5] 中川、赤木 (1994).”母音知覚における文脈効果の測定とそのモデリング”、電子情報通信学会技術報告、SP93-151
4-3 聴覚フィルタ
<解説・招待講演>
[1] 赤木他(2001).”特集−音響学における20世紀の成果と21世紀に残された課題− 聴覚分野”、日本音響学会誌、57, 1, 5-10.
[2] 赤木正人(1998).”聴覚特性を考慮した波形分析”、日本音響学会誌, 54, 8, 575-581.
[3] 赤木正人(1995).”Q&Aコーナー、mel尺度、Bark尺度とERB尺度の違い”、日本音響学会誌、51, 9, 738-739.
[4] 赤木正人 (1994).”聴覚フィルタとそのモデル”、電子情報通信学会誌解説, 77, 9, 948-956
[5] 赤木正人 (1993).”音声の知覚と聴覚モデル”、電子情報通信学会技術報告(ビギナーズセミナー),SP93-47
4-4 位相知覚
<招待講演>
[1] 赤木正人(1997).”位相と知覚 −人間ははたして位相聾か?−”、平成9年秋季音響学会招待講演論文、1-2-2.
<研究会・大会>
[1] Akagi, M., and Nishizawa, M. (2001). "Detectability of phase change
and its computational modeling," J. Acoust. Soc. Am., 110, 5, Pt.
2, 2680.
[2] 西澤、赤木(2000).”位相の違いに対する音色知覚機構について”、音響学会聴覚研究会資料、H-2000-40.
[3] 赤木、安武(1998).“時間方向情報の知覚の検討 −位相変化の音色知覚に及ぼす影響について−”、電子情報通信学会技術報告、EA98-19.
4-5 音声知覚
<査読付論文・国際会議>
[1] Kubo, R., Akagi, M., and Akahane-Yamada, R. (2015/9/1). “Dependence
on age of interference with phoneme perception by first- and second-language
speech maskers,” Acoustical Science and Technology, 36, 5, 397-407.
[2] Kubo, R., Akagi, M., and Akahane-Yamada, R. (2014/05/09). “Perception
of second language phoneme masked by first- or second-language speech in
20 – 60 years old listeners,” 167th ASA, Providence, RI
[3] Kubo, R. and Akagi, M. (2013/06/04). “Exploring auditory aging can
exclusively explain Japanese adults′ age-related decrease in training effects
of American English /r/-/l/,” Proc. ICA2013, 2aSC34, Montreal.
<研究会・大会>
[1] 久保,赤木(2015/05/23). “米語/r/-/l/知覚で生じる母語干渉における成人の年代変化”,2015音学シンポジウム(電通大学),情報処理学会研究報告,2015-MUS-107,
41.
[2] 久保理恵子,赤木正人,山田玲子 (2014/09/05). “第二言語音韻知覚時におけるマスキング音の影響 -異なる言語のバブルノイズをマスキング音とした場合の比較-”,日本音響学会平成26年度秋季研究発表会,
3-Q-43.
[3] 久保,赤木,山田. (2014/03/11). “音声マスキングを用いた第二言語音韻知覚の年齢効果の検討”,日本音響学会平成26年春季研究発表会,2-P5-26.
[4] 久保,赤木(2014/02/08).“競合音声マスキングを用いた第二言語音韻知覚における年齢効果の検討”,音響学会聴覚研究会資料,44,
1, H-2014-5.
[5] 久保,赤木 (2013/06/14). “/r/-/l/訓練における年齢効果:聴覚機能劣化の影響の有無”,音響学会聴覚研究会資料,43, 4, H-2013-61
[6] 久保,赤木 (2013/03/13). “聴覚機能低下が/r/-/l/音韻訓練へ与える影響”,日本音響学会平成25年春季研究発表会,1-8-6.
[7] 久保,山田,山田,赤木 (2011/10/01). “中高齢者の日本語話者に対する米語音韻対/r/-/l/聴取訓練”,音響学会聴覚研究会資料,41,
7, H-2011-95.
[8] 田高、赤木(2002).”3連続母音の中心母音知覚に寄与するわたり部の時間構造”、電子情報通信学会技術報告、SP2001-143.
4-6 騒音評価
<査読付論文・国際会議>
[1] Akagi, M., Kakehi, M., Kawaguchi, M., Nishinuma, M., and Ishigami,
A. (2001). "Noisiness estimation of machine working noise using human
auditory model", Proc. Internoise2001, 2451-2454.
[2] Mizumachi, M. and Akagi, M. (2000). "The auditory-oriented spectral distortion for evaluating speech signals distorted by additive noises," J. Acoust. Soc. Jpn. (E), 21, 5 251-258.
[3] Mizumachi, M. and Akagi, M. (1999). "An objective distortion estimator for hearing aids and its application to noise reduction," Proc. EUROSPEECH99, 2619-2622.
<研究会・大会>
[1] 筧、赤木、川口、西村(2001).”聴覚末梢系処理モデルを用いた非定常機械騒音の評価”、平成13年春季音響学会講演論文、1-5-3.
[2] 水町、赤木(2000).”加法性雑音に対する客観的歪み音声評価尺度”、音響学会聴覚研究会資料、H-2000-4.
4-7 ピッチ知覚
<査読付論文・国際会議>
[1] Ishida, M. and Akagi, M. (2010/03/04). "Pitch perception of complex sounds with varied fundamental frequency and spectral tilt," Proc. NCSP10, Hawaii, USA, 480-483.
<研究会・大会>
[1] 石田舞,赤木正人 (2010/3/8).“音色的高さに影響を及ぼす物理量の検討”,日本音響学会平成22年春季研究発表会, 1-R-21.
4-8 方向知覚
<査読付論文・国際会議>
[1] Akagi, M. and Hisatsune, H. (2013/10/17). “Admissible range for individualization
of head-related transfer function in median plane,” Proc. IIHMSP2013, Beijing.
[2] Hisatsune, H. and Akagi, M. (2013/03/6). “A Study on individualization
of Head-Related Transfer Function in the median plane,” Proc. NCSP2013,
Hawaii, USA, 161-164.
5.生理学的聴覚モデル
<査読付論文・国際会議>
[1] 牧,赤木,廣田 (2009/5/1).“聴覚末梢系の機能モデルの提案-聴神経の位相固定性及びスパイク生成機構のモデル化-”,日本音響学会論文誌,65,
5, 239-250. (日本音響学会佐藤論文賞)
[2] 牧,赤木,廣田(2004).“下丘細胞の時間応答特性に関する計算モデルの提案”,日本音響学会誌,60, 6, 304-313.
[3] 牧,赤木,廣田(2004).“蝸牛神経核背側核細胞の周波数応答特性に関する神経回路モデルの提案―トーンバースト刺激に対する応答―”,日本音響学会誌,60, 1, 3-11. (日本音響学会佐藤論文賞)
[4] Ito, K. and Akagi, M. (2003). “Study on improving regularity of neural
phase locking in single neuron of AVCN via computational model,” Proc.
ISH2003, 77-83.
[5] Maki, K. and Akagi, M. (2003). “A computational model of cochlear nucleus
neurons,” Proc. ISH2003, 70-76.
[6] 牧,伊藤,赤木(2003).“初期聴覚系における神経発火の時間-周波数応答パターン”,日本音響学会誌、59, 1, 52-58.
[7] 牧,赤木,廣田(2003).”蝸牛神経核腹側核細胞モデルの振幅変調音に対する応答特性”、日本音響学会誌、59, 1, 13-22.
[8] Ito, K. and Akagi, M. (2001). “A computational model of auditory sound
localization,” in Computational Models of Auditory Function (Eds. Greenberg,
S. and Slaney, M.), NATO ASI Series, IOS Press, Amsterdam, 97-111.
[9] Ito, K. and Akagi, M. (2000). "A computational model of binaural coincidence detection using impulses based on synchronization index." Proc, ISA2000 (BIS2000), Wollongong, Australia.
[10] 牧、赤木、廣田(2000).”蝸牛神経核細胞の機能モデルの提案 −前腹側核細胞の応答特性−”、日本音響学会論文誌、56, 7, 457-466.
[11] Ito, K. and Akagi, M. (2000). "A study on temporal information
based on the synchronization index using a computational model," Proc.
WESTPRAC7, 263-266.
[12] Maki, K., Akagi, M. and Hirota, K. (1999). "Effect of the basilar membrane nonlinearities on rate-place representation of vowel in the cochlear nucleus: A modeling approach," Abstracts of Symposium on Recent Developments in Auditory Mechanics, Sendai, Japan, 29P06, 166-167.
[13] Ito, K. and Akagi, M. (1999). "A computational model of auditory
sound localization based on ITD," Abstracts of Symposium on Recent
Developments in Auditory Mechanics, Sendai, Japan, 29P01, 156-157.
[14] Maki, K. and Akagi, M. (1997). "A functional model of the auditory
peripheral system", Proc. ASVA97, Tokyo, 703-710.
<本(章)>
[1] Ito, K. and Akagi, M. (2005). "Study on improving regularity of neural phase locking in single neurons of AVCN via a computational model," In Auditory Signal Processing, Springer, 91-99.
[2] Maki, K. and Akagi, M. (2005). "A computational model of cochlear
nucleus neurons," In Auditory Signal Processing, Springer, 84-90.
[3] Ito, K. and Akagi, M. (2001). “A computational model of auditory sound
localization,” in Computational Models of Auditory Function (Eds. Greenberg,
S. and Slaney, M.), NATO ASI Series, IOS Press, Amsterdam, 97-111.
[4] Maki, K., Akagi, M. and Hirota, K. (2000). "Effect of the basilar membrane nonlinearities on rate-place representation of vowel in the cochlear nucleus: A modeling approach," In Recent Developments in Auditory Mechanics, World Scientific Publishing, 490-496.
[5] Ito, K. and Akagi, M. (2000). "A computational model of auditory sound localization based on ITD," In Recent Developments in Auditory Mechanics, World Scientific Publishing, 483-489.
<研究会・大会>
[1] 伊藤,赤木(2004).“頭内定位実験による聴覚系の位相情報伝達に関する検討”,音響学会聴覚研究会資料、H-2004-1.
[2] 伊藤、赤木(2002).” 神経細胞における時間情報伝達の仕組みに関する一考察:SBCの位相同期特性とentrainment特性について”、音響学会聴覚研究会資料、H-2002-02.
[3] 伊藤、赤木(2001).”位相同期特性に基づく多重入力と時間差検出に関する一考察”、音響学会聴覚研究会資料、H-2001-5.
[4] 牧、赤木、廣田(2000).”聴覚モデルに基づいた蝸牛神経核背側核における時間および平均発火応答特性に関する検討”、音響学会聴覚研究会資料、H-2000-2.
[5] 牧、赤木、廣田(1999).”下丘細胞の多様な時間応答特性に関する計算モデルの提案”、音響学会聴覚研究会資料、H-99-98.
[6] 牧、赤木、廣田(1998).“前腹側蝸牛神経核細胞の機能モデルの提案”、音響学会聴覚研究会資料、H-98-104
[7] 牧、赤木、廣田(1998).“モデルに基づいた前腹側蝸牛神経核における母音に対するチョッパー型応答に関する検討”、音響学会聴覚研究会資料、H-98-50
[8] Ito, K. and Akagi, M. (1998). “A computational model of auditory sound
localization,” Computational Hearing, Italy, 67-72
[9] Maki, K., Hirota, K. and Akagi, M. (1998). “A functional model of the auditory peripheral system: Responses to simple and complex stimuli,” Computational Hearing, Italy, 13-18.
[10] 伊藤、赤木(1998).”音源方向定位のための聴覚モデルの検討”、電子情報通信学会技術報告、SP97-138.
[11] 牧、赤木、廣田(1997).”聴覚末梢系モデルに基づいた聴神経における母音の符号化に関する検討”、音響学会聴覚研究会資料、H-97-70
[12] 牧、赤木(1996).”聴覚末梢系における実時間モデルの検討”、音響学会聴覚研究会資料、H-96-74
6.異常構音
6-1 異常構音の知覚
<査読付論文・国際会議>
[1] Kozaki-Yamaguchi, Y., Suzuki, N., Fujita, Y., Yoshimasu, H., Akagi,
M., and Amagasa, T. (2005). "Perception of hypernasality and its physical
correlates," Oral Science International, 2, 1, 21-35.
[2] Kozaki, Y., Suzuki, N., Amagasa, T., and Akagi, M. (2004). “Perception of hypernasality and its physical correlates,” Proc. ICA2004. 3313-3316.
[3] Akagi, M., Suzuki, N., Hayashi, K., Saito, H., and Michi, K. (2001). " Perception of Lateral Misarticulation and Its Physical Correlates", Folia Phoniatrica et Logopaedica, 53, 6, 291-307
<招待講演>
[1] 赤木正人(2001).”口の中の音響学 −口を大きくあけて声を出すとなぜ”あ”なのか?−”、第25回日本口蓋裂学会教育講演(招待講演)、日本口蓋裂学会雑誌、26, 2, 161.
<研究会・大会>
[1] 古崎,吉増,天笠,鈴木,赤木(2003).“スペクトル操作合成音声の聴取と声道形状モデルによる開鼻声の音響的特徴の分析”,電子情報通信学会技術報告、SP2003-36.
[2] 斉藤、鈴木、北村、赤木、道(1999).”舌・口底切除における異常構音の音響的特徴−スペクトルのピーク分析の試み−”、電子情報通信学会技術報告、SP98-149.
[3] 斉藤、赤木(1998).“口腔疾患に伴う構音障害の音響的特徴に関する研究”、JAIST Tech. Report, IS-RR-98-0011P.
[4] 斉藤、鈴木、赤木、高橋、道(1998).”舌・口底切除症例における構音動態及び音響特性”、電子情報通信学会技術報告、SP97-122.
[5] Akagi, M., Kitamura, T., Suzuki, N. and Michi, K. (1996). "Perception
of lateral misarticulation and its physical correlates", Proc ASA-ASJ
Joint Meeting, 933-936.
[6] 赤木正人、高木直子、北村達也、鈴木規子、藤田幸弘、道健一(1996).”側音化構音の知覚と物理関連量”、電子情報通信学会技術報告、SP96-34.
[7] 高木、北村、赤木、鈴木、藤田、道(1996).”側音化構音の音響特性について”、平成8年春季音響学会講演論文、1-3-3.
6-2 3次元声道モデル
<査読付論文・国際会議>
[1] Nishimoto, H. and Akagi, M. (2006). "Effects of complicated vocal
tract shapes on vocal tract transfer functions," Journal of Signal
Processing, 10, 4, 267-270.
[2] 西本,赤木,北村,鈴木(2006).“有限要素法による声道伝達特性推定の有効性に関する検討”, 日本音響学会誌,62, 4, 306-315.
[3] Nishimoto, H. and Akagi, M. (2006). "Effects of complicated vocal tract shapes on vocal tract transfer functions," Proc. NCSP2006, 114-117.
[4] Nishimoto, H., Akagi, M., Kitamura, T. and Suzuki, N. (2004). “Estimation
of transfer function of vocal tract extracted from MRI data by FEM,” Proc.
ICA2004, 1473-1476.
[5] 斉藤、鈴木、藤田、道、高橋、赤木、和久本(2000).”MR撮像法を用いた3次元声道形状の計測 −舌・口底切除症例の検討−”、昭和歯学会雑誌、20,
2, 198-214.
<研究会・大会>
[1] 西本,赤木,北村,鈴木(2004).”MRI計測による声道モデルの伝達特性の推定精度の検討”、電子情報通信学会技術報告、SP2003-191.
[2] 岡崎,西本,赤木(2004) .“無声摩擦子音発声時の気流の数値流体解析”,平成16年春季音響学会講演論文、3-7-4.
[3] Nishimoto, H., Akagi, M., Kitamura, T., and Suzuki, N. (2002). "FEM analyses of three dimensional vocal tract models after tongue and mouth floor resection," NATO Advanced Study Institute 2002 Dynamics of Speech Production and Perception.
[4] Nishimoto, H., Akagi, M., Kitamura, T., Suzuki, N., and Saito, H. (2001).
"FEM analysisof three-dimensional vocal tract models after tongue
and mouth floor resection," J. Acoust. Soc. Am., 110, 5, Pt. 2, 2761.
[5] 西本、赤木、北村、鈴木、齋藤、道、高橋(2001).”舌・口底切除患者の3次元声道形状モデルの有限要素法による分析”、電子情報通信学会技術報告、SP2000-154.
[6] 北村、鈴木、齋藤、道、高橋、赤木、和久本(2001).”MRIによる舌・口底切除患者の3次元声道形状の分析”、電子情報通信学会技術報告、SP2000-153.
7.生成と知覚の相互作用
<査読付論文・国際会議>
[1] Shih, T, Suemitsu, A., and Akagi, M. (2011/03/03). “Influences of transformed
auditory feedback with first three formant frequencies,” Proc. NCSP2011,
Tianjin, China, 340-343.
[2] Dang, J., Akagi, M., and Honda, K. (2006). "Communication between
speech production and perception within the brain - Observation and simulation,"
J. Comp. Sci. & Tech., 21, 1, 95-105.
[3] Matsuoka, R., Lu, X., Dang, J., and Akagi, M. (2004). “Investigation
of interaction between speech perception and speech production,” Proc.
KIT Int. Sympo. Brain and Language 2004, 27-28.
<研究会・大会>
[1] Shih, T., Suemitsu, A., and Akagi, M. (2010/10/16). "Influences
of real-time auditory feedback on formant perturbations," Proc. Auditory
Research Meeting, ASJ, 40, 8, H-2010-121.
[2] 内山田,Lu,党,赤木(2007).”変形聴覚フィードバックに対する発話系の反応の計測”,平成19年春季音響学会講演論文,2-Q-18
[3] Akagi, M., Dang, J., Lu, X., and Uchiyamada, T. (2006). "Investigation of interaction between speech perception and production using auditory feedback," J. Acoust. Soc. Am., 120, 5, Pt. 2, 3253.
[4] 内山田,Lu,党,赤木(2006)."変形聴覚フィードバックによる発話系の補償動作について",平成18年秋季音響学会講演論文、3-P-9.
[5] 田中,Lu,党,赤木(2006).”変形聴覚フィードバックにおける摂動量と補正動作の関係について”,平成18年春季音響学会講演論文、2-3-11
[6] 松岡,Lu,党,赤木(2004).“調音情報を考慮した聴覚系と発話系の相互作用に関する検討”,音響学会聴覚研究会資料、H-2004-103.
8.信号分析
<査読付論文・国際会議>
[1] 西江純教,赤木正人 (2014/04/01). “弦楽器F0 推定のための精密周波数測定方法”,電子情報通信学会論文誌A, J97-A,
4, 332-342.
[2] Kobayashi, K., Morikawa, D., and Akagi, M. (2014/03/01). “Study on
Analyzing Individuality of Instrurment Sounds Using Non-negative Matrix
Factorization,” Proc. NCSP2014, Hawaii, USA, 37-40.
[3] Nishie, S. and Akagi, M. (2013/09/11). “Acoustic sound source tracking
for a moving object using precise Doppler-shift measurement,” Proc. EUSIPCO2013,
Marrakesh, Morocco.
<研究会・大会>
[1] 西江,赤木. (2014/03/10). “遅延器による位相差を利用するデジタルFM復調器の提案”,日本音響学会平成26年春季研究発表会,1-6-9.
[2] 小林,森川,赤木. (2014/03/10). “非負値行列因子分解を用いたピアノ音の個体差要因の分析”,日本音響学会平成26年春季研究発表会,1-5-5.
[3] 西江,赤木 (2013/12/13). “遅延器による位相差を利用する瞬時周波数測定方法の提案“,電子情報通信学会技術報告,EA-2013-93.
[4] 西江,赤木 (2013/09/25). “微細ドップラーシフト計測による移動音源追跡”,日本音響学会平成25年度秋季研究発表会, 1-P-35c.
[5] 西江,赤木 (2013/0718). “フーリエ変換を使用しない基本周波数推定による楽器音F0推定“,電子情報通信学会技術報告,EA-2013-36.
[6] 西江,赤木 (2013/03/15). “フーリエ変換を使用しない実時間F0 推定の試み”,日本音響学会平成25年春季研究発表会,3-P-52b.
[7] 西江,赤木 (2012/05/24). “2周波数混合波形による瞬時周波数計測の精度測定”,電子情報通信学会技術報告,EA-2012-8
[8] 西江,赤木 (2012/03/09). “疑似直交変換による瞬時位相計測方法 ―Hilbert変換器の位相精度検証―”,電気学会計測研究会資料,IM-12-021.
9.書籍等
9-1 書籍等
[1] 日本音響学会編(2011).共著.”音響学入門”、コロナ社
[2] 日本音響学会編(2003).共著.”新版音響用語辞典”、コロナ社
[3] 甘利、外山編(2000).共著.”脳科学大事典”、朝倉書店
[4] 日本音響学会編(1996).共著.”音のなんでも小辞典”、講談社ブルーバックス
[5] ホイットマン・リチャーズ編、石川、平原訳(赤木:翻訳協力)(1994).”ナチュラルコンピュテーション”、パーソナルメディア
[6] 赤木正人 (1993).”音声の知覚と聴覚モデル”、bit, 25, 9, 99-107、共立出版
9-2 その他
[1] 赤木正人(1997).”私の意見:企業から大学に移って思うこと”、電子情報通信学会誌、80, 1, 90-91.
10.(参考)その他
10-1 NTT, ATR
<査読付論文・国際会議>
[1] Akagi, M. (1993). "Modeling of contextual effects based on spectral
peak interaction", J. of Acoust. Society of America, 93, 2, 1076-1086.
[2] Akagi, M. (1992). "Psychoacoustic evidence for contextual effect
models", Speech Perception, Production and Linguistic Structure, IOS
Press, Amsterdam, 63-78
[3] Akagi, M. (1990). "Contextual effect models and psychoacoustic evidence for the models", Proc. Int. Conf. Spoken Lang. Process. 90, 569-572.
[4] Akagi, M. and Tohkura, Y. (1990). "Spectrum target prediction
model and its application to speech recognition", Computer Speech
and Language, 4, Academic Press 325-344.
[5] Akagi, M. (1990). "Evaluation of a spectrum target prediction
model in speech perception", J. of Acoust. Society of America, 87,
2, 858-865.
[6] Ueda, K. and Akagi, M. (1990). "Sharpness and amplitude envelopes of broadband noise", J. of Acoust. Society of America, 87, 2, 814-819.
[7] Furui, S. and Akagi, M. (1985). "On the role of spectral transition
in phoneme perception and its modeling", Proc. 12th Int. Conf. Acoustics,
A2-6.
[8] Akagi, M. and Tohkura, Y. (1988). "On the application of spectrum
target prediction model to speech recognition", Proc. Int. Conf. Acoustics
Speech and Signal Process., New York, 139-142.
[9] 赤木、古井(1986).”音声知覚における母音ターゲット予測機構のモデル化”、電子情報通信学会論文誌、J69-A, 10, 1277-1285
<研究会・大会>
[1] Akagi, M. (1990). "Psychoacoustic evidence for a contextual effect
model", J. Acoust. Soc. Am., Spl 1, 87, MMM2 (119th Meeting of ASA).
[2] Akagi, M. (1989). "Modeling of contextual effect based on spectral
peak interaction", J. Acoust. Soc. Am., Spl 1, 85, II8 (117th Meeting
of ASA).
[3] Akagi, M. (1987). "Evaluation of a spectrum target prediction
model in speech perception", J. Acoust. Soc. Am., Spl 1, 81, G8 (113th
Meeting of ASA).
10-2 東京工業大学
<査読付論文・国際会議>
[1] 赤木、飯島(1984).”極性誤差識別法による日本語破裂音の認識”、電子情報通信学会論文誌、J67-A, 11, 1013-1019
[2] 赤木、飯島(1984).”極性誤差識別法による日本語音素認識−POLPEC II−”、電子情報通信学会論文誌、J67-A, 5, 439-446
[3] 赤木、飯島(1984).”極変動追随フィルタの一構成法”、電子情報通信学会論文誌、J67-A, 2, 133-140
[4] 赤木、飯島(1982).”極性誤差識別法による音声認識−POLPEC法−”、電子情報通信学会論文誌、J65-A, 8, 759-766
|
|
|