
Deep Learning, Natural Language
Understanding, Legal Text Processing
Laboratory on Deep Learning, Natural Language Understanding, Large Language Models, and Legal Text Processing
Professor:NGUYEN, Minh Le
E-mail:
[Research areas]
Artifical Intelligence, Natural Language Processing, Machine Learning
[Keywords]
Natural Language Understanding, Text Summarization, Deep Learning, Knowledge Representation
Skills and background we are looking for in prospective students
Mathematic, Programing (C++, Java, Python),Statistical models, Background on Artificial intelligence (Search algorithms, machine learning models). Background on Natural Language Processing is a plus point.
What you can expect to learn in this laboratory
We expect that students will obtain the following qualities through research activities in the lab. Skilsl in finding problems and reading papers. Have knowledge background on machine learning (deep learning) and natural language processing. With Ph.D students, we expect that after graduation they will become independent researcher and they can know how to write a scientific journal and how to present they works in an international conference. With master student, we expect that they will have skills in working with the problems of how to expoloit machine learning models on semi-structure data (big data). They can also know how to formulate a problem using machine learning models. They will obtain fundmental knowledge on machine learning and knowledge representation.
【Job category of graduates】 communication industry, software industry, service industry
Research outline
Research Overview
Structure representations and machine learning models play a key important role for Artificial intelligence (AI). Our research will focus on how tactical structural representation and machine learning are used for formulating problems in AI ranging from text summarization, natural language understanding, legal engineering, and machine [1][2][3].
Machine Learning
Fundamental problems in machine learning are focused on our research directions. We particularly study on structured prediction modes, which are used to recognize structure representation such as sequence, tree, and graph. On the other hand, designing feature spaces for machine learning is difficult and requiring much human effort. To deal with this, we are concerned on how feature representation is automatically learnt from data. Regarding to this problem, Deep learning would probably be suitable for our goal. We also study on reinforcement learning which can learn by interacting with environments.
Natural Language Understanding

Logical parts in legal paragraph
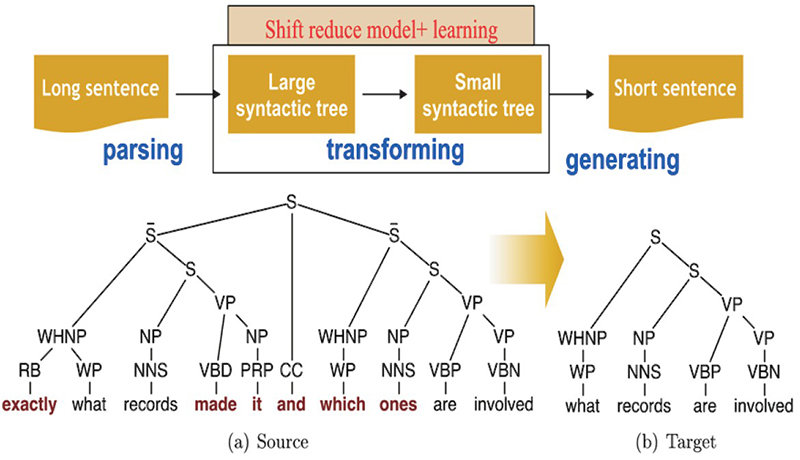
Text Summarization: Sentence Reduction
One of the ultimate goals in AI is to enable computers to converse with humans through human languages. To achieve the goal, we especially pay attention on semantic computation. This research is used to support computers to understanding natural language. Our initial work showed how synchronous grammars could be combined with structured learning models to transform a natural language sentence to a logical form representation [1]. On the other hand, we want to investigate how natural language generation (NLG) can help computers for producing a human understandable language sentence from its meaning representation. One research topic we pursue is to know how probabilistic models can be applied for generating natural language sentences from their underlying semantic in the form of typed lambda calculus.
For legal engineering, our mission is to support people for reading legal documents. The first task aims at recognizing logical parts of law sentences in a paragraph, and then grouping related logical parts into some logical structures of formulas, which describe logical relations between logical parts.
Machine Reading:
One of the direction in our lab is to study the fundamental problems on how we can extract useful information from texts and how to build knowledge from texts. First, we are interested in text summarization which is used to extract gist information from text documents.
We also focus on studying Machine Reading, which automatically extracts knowledge from a large number of documents by reading texts. Communication between human and machine in reading text is also interested in our study. A Question Answering system like IBM-Watson is our expected outcome.
Key publications
- Do, Dinh-Truong; Nguyen, Minh-Phuong; Nguyen, Le-Minh, Enhancing zero-shot multilingual semantic parsing: A framework leveraging large language models for data augmentation and advanced prompting techniques, In: Neurocomputing, vol. 618, pp. 129108, 2025
- Khang Nguyen Le, Ryo Sato, Dai Nakashima, Takeshi Suzuki, Minh Le Nguyen, OptiPrune:Effective Pruning Approach for Every Target Sparsity Proceedings of the 31st International Conference on Computational Linguistics 2025
- NK Le, DH Nguyen, LM Nguyen, ANSPRE: Improving Question-Answering in Large Language Models with Answer-Prefix Generation- In Proceedings of ECAI 2024, 2024
Equipment
Mac Server 64G
Windows Server 64GRAM
Teaching policy
The primary goal for teaching students is that we should teach students how they can develop an ability of self-learning. For supervising graduated students, we think one of the most important things is how to find problems for studying. To support students, we would like to discuss with students as much as possible to help them in choosing the research topic and discovering problems. Reading skill is so important for students in order to enrich their knowledge, and it would be helpful for students in choosing the topics and finding out problems. For this reason, our lab organize seminar courses covering state-of-the-art results. We think reading and discussing on state-of-the-art works, would be useful for improving not only student’s knowledge but also the student’s skills in writing papers. We also organize seminar courses covering the background knowledge both in machine learning and linguistic aspects.
[Website] URL:https://www.jaist.ac.jp/is/labs/nguyen-lab/home/