
How can we implement a computational auditory model?
Laboratory on Acoustic Information Science
Professor:UNOKI Masashi
E-mail:
[Research areas]
Multimedia information hiding, auditory information processing, speech signal processing
[Keywords]
Audio information hiding, computational auditory model, modulation perception, speech security, deep learning
Skills and background we are looking for in prospective students
Students in our laboratory are required to have knowledge of psychology and physiology related to the auditory system, programming skills, presentation skills, and communication skills. This knowledge and these skills can be obtained by participating in the regular laboratory meetings.
What you can expect to learn in this laboratory
Students can gain wide research knowledge with regard to auditory, audio, and speech signal processing and communication skills to become experts. They can also have the chance to think logically, be creative, and have a profound insight into researching challenging topics. In particular, master’s students can learn the ability to resolve research issues by themselves while PhD students can learn the ability to think up research seeds and adaptively cope with various issues from various points of view.
【Job category of graduates】 ICT, SE/SI, Audio & Automotive Industries, Academic staff
Research outline
Humans can easily hear a target sound that they are listening for in real environments including noisy and reverberant ones. On the other hand, it is very difficult for a machine (i.e., a computer) to perform the same task using a computational auditory model. Implementing auditory signal processing with the same function as that of the human hearing system on a computer would enable us to do human-like speech signal processing. Such a processing system would be highly suitable for a range of applications, such as speech recognition processing and hearing aids. Achieving this is the ultimate goal of our research team.
The following research projects have used an auditory filterbank to process speech signals: the selective sound segregation model, noise reduction model based on auditory scene analysis, speech enhancement methods based on the concept of the modulation transfer function, and bone-conducted speech restoration model for improving speech intelligibility. We usually use the gammatone auditory filterbank as the first approximation of a nonlinear auditory filterbank in these projects. Our perspective is to model the 'cocktail party effect' and apply this model to solving challenging problems by developing our research projects using a nonlinear auditory signal processing.
Unauthenticated multimedia fabricated by means of state-of-the-art techniques such as deep learning has become a growing concern in the areas of digital forensics, data tampering, spoofing, and privacy distribution. The root cause of these issues is deepfake speech, as advanced AI-based speech analysis/synthesis techniques can now be used to skillfully fabricate unauthentic replicas from authentic multimedia information. Therefore, the imminent threat of deepfake speech attacks, such as the spoofing speech problem as shown in Fig. 1, must be addressed as soon as possible. In our current projects, we are developing speech information techniques for speech security such as secure speech communication and preventing the tampering of speech content on the Internet as shown in Fig. 1.
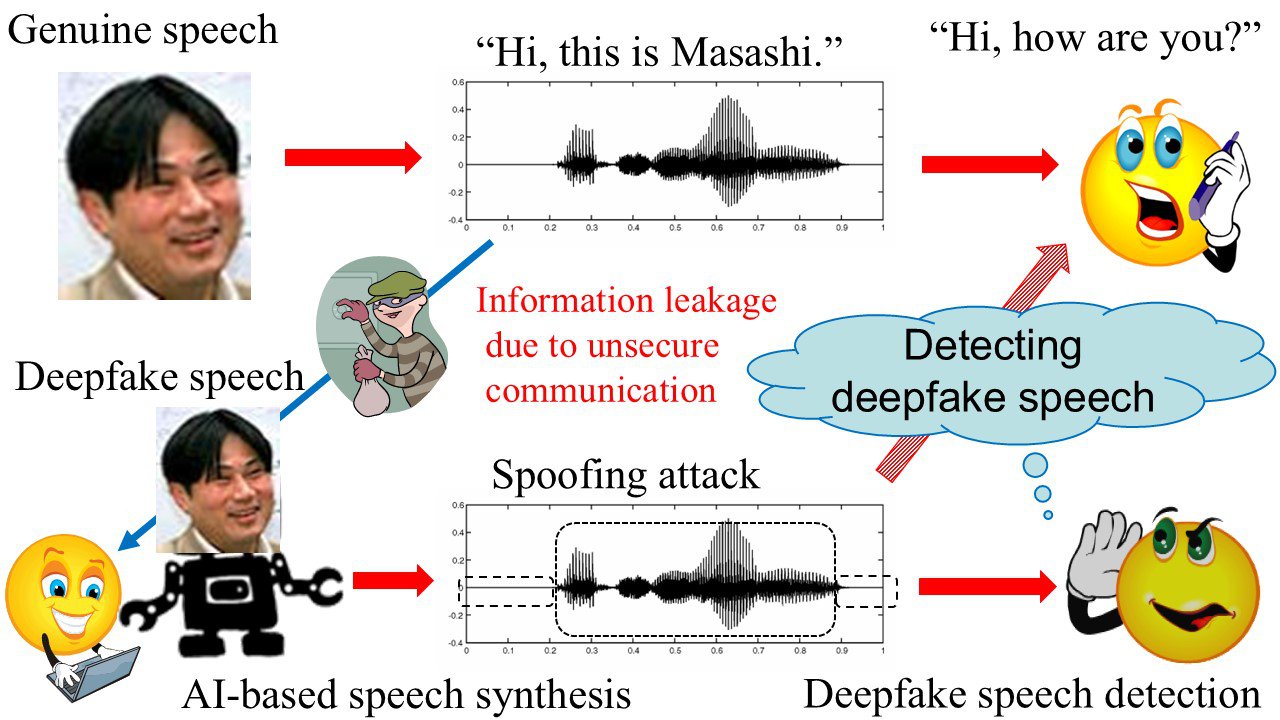
Fig. 1 Speech spoofing by deepfake speech attacks.
Key publications
- Anuwat Chaiwongyen, Suradej Duangpummet, Jessada Karnjana, Waree Kongprawechnon, and Masashi Unoki, “Potential of Speech-pathological Features for Deepfake Speech Detection,” IEEE Access, vol. 12, pp. 121958 – 121970, Aug. 2024. DOI: 10.1109/ACCESS.2024.3447582.
- Takuto Isoyama, Shunsuke Kidani, Masashi Unoki, “Computational models of sound-quality metrics using method for calculating loudness with gammatone/gammachirp auditory filterbank,” Applied Acoustics, Volume 218, 109914, March 2024. DOI: https://doi.org/10.1016/j.apacoust.2024.109914
- Candy Mawalim, Benita Angela Titalim, Shogo Okada, Masashi Unoki, “A Non-Intrusive Speech Intelligibility Prediction Using Auditory Periphery Model under Hearing Loss Perception,” Applied Acoustics, vol. 214, 109663, 2023. DOI: https://doi.org/10.1016/j.apacoust.2023.109663
Equipment
Equipment for psychoacoustical experiments
Sound-proof rooms and an anechoic box
Measurement system for room acoustics
Computer servers for machine learnings
Teaching policy
Unoki Laboratory aims to investigate the basis of human auditory perception and its mechanism by taking two approaches of the scientific research on human auditory systems and audio signal processing. Laboratory members have meetings and seminars to study the basis of these two approaches and brainstorm for improving their own abilities to be future researchers. Each student has his/her own project for his/her MS or PhD dissertation. All laboratory members can share information and have important opportunities for doing his/her own research as well as working with the best laboratory members.
[Website] URL:https://www.jaist.ac.jp/~unoki/lab/en/index.html