Program
Welcome to the NLDB 2025
In this year's edition of NLDB 2025, we bring together leading minds in Natural Language Processing and Information Systems for an engaging, globally connected conference experience. With a diverse lineup of presenters from around the world, NLDB 2025 will showcase the latest innovations, research breakthroughs, and real-world applications in NLP. We explore the evolving landscape of language technologies, foster international collaboration, and shape the future of human-language interaction in the digital age.
Day 1: July 4th (Fri)
| 9:00 ~ | Registration |
| Room A | |
| 9:30 ~ 9:50 | Opening Ceremony |
| 9:50 ~ 10:40 | Keynote: Real-Time Language Generation from Non-Textual Data - Dr. Hiroya Takamura (Artificial Intelligence Research Center, National Institute of Advanced Industrial Science and Technology) |

Title: Real-Time Language Generation from Non-Textual DataDr. Hiroya TakamuraArtificial Intelligence Research Center, National Institute of Advanced Industrial Science and TechnologyAbstractWhile the progress of large language models (LLMs) has been striking in recent years, their practical deployment for diverse real-world tasks still leaves considerable room for improvement. In particular, real-world applications often require interpreting non-textual data—such as numerical values and visual content—and generating language outputs in real time. This talk focuses on these two crucial aspects: enhancing LLMs' ability to process multimodal inputs and improving their responsiveness for time-sensitive scenarios. Through concrete examples including live sports commentary generation and market comment generation, we will explore methods for improvement and discuss the technical challenges that must be addressed. |
|
| - Break (10:40 ~ 11:00) - | |
🌸 Session 1: 11:00 ~ 12:05
| Room A | Room B | ||
|---|---|---|---|
Session chair: Akiko Aizawa |
Session chair: Flavius Frasincar |
||
| 11:00 ~ 11:25 |
Leveraging Generative AI for Chronic Kidney Disease Prediction: A Comparative Study of Open-Source LLMs
- Abhin B, Hemanth Kumar M, Sowmya Kamath S and Vijayan Sugumaran |
11:00 ~ 11:25 |
Accelerating End-to-End PDF to Markdown Conversion through Assisted Generation
- Changxu Duan |
| 11:25 ~ 11:50 |
Test It Before You Trust It: Applying Software Testing for Trustworthy In-context Learning
- Teeradaj Racharak, Chaiyong Ragkhitwetsagul, Chommakorn Sontesadisai and Thanwadee Sunetnanta |
11:25 ~ 11:50 |
Improve Smart Contract Vulnerability Explanation with Synthetic Data and Chain-of-Thought Prompting
- Nguyen Ngoc Minh, Naoya Inoue and Nguyen Le Minh |
| 11:50 ~ 12:05 |
Hybrid-SET: Few-shot Example Selection Combining Sentence Similarity and Set Coverage - A Case Study on Material Science Domain
- Chencheng Zhu, Tomoki Taniguchi, Tomoko Ohkuma and Kazutaka Shimada |
11:50 ~ 12:05 |
LLM-Supervised Multilingual Skill Extraction and Classification from Job Ads
- Jakob Morup Wang and Zhiru Sun |
| - Lunch (12:10 ~ 13:30) - | |||
🌸 Session 2: 13:30 ~ 15:30
| Room A | Room B | ||
|---|---|---|---|
Session chair: Teeradaj Racharak |
Session chair: Junichiro Niimi |
||
| 13:30 ~ 13:55 |
A Comparative Study on the Development of a Thai Legal QA Framework Using Large Language Models and Mixed Legal Datasets
- Supachoke Hanwiboonwat, Chaichana Thavornthaveekul, Prachya Boonkwan, Apivadee Piyatumrong and Peerapon Vateekul |
13:30 ~ 13:55 |
Multiple Graphical Convolution Networks Approach for Aspect-Based Sentiment Classification
- Diana Kazakova, Flavius Frasincar and Jasmijn Klinkhamer |
| 13:55 ~ 14:20 |
LADDER: Latent Attention and Decomposition for Deep Enhanced Retrieval in Medical Question-Answering Systems
- Sidhaarth Murali, Sowmya Kamath S and Vijayan Sugumaran |
13:55 ~ 14:20 |
MultiProSE: A Multi-label Arabic Dataset for Propaganda, Sentiment, and Emotion Detection
- Lubna Alhenaki, Hend Al-Khalifa, Abdulmalik Al-Salman, Hajar Alqubayshi, Hind Al-Twailay, Gheeda Alghamdi and Hawra Aljasim |
| 14:20 ~ 14:45 |
Multi-hop Question Answering in SlideVQA Based on Beam Retrieval
- Mizuki Yamano and Hisashi Miyamori |
14:20 ~ 14:35 |
News Timeline Summarization: Recent Methods
- Vandana Yadav, Jon Atle Gulla, Özlem Özgobek and Lemei Zhang |
| 14:45 ~ 15:00 |
Fusion-in-LLM: A Parallel Approach to Improve Retrieval-Augmented Generation for Quiz-Based Question Answering
- Yuuki Tachioka |
14:35 ~ 14:50 |
Towards an Ontological Approach to Browser Fingerprinting Detection and Privacy Risk Assessment
- Christopher D. McDermott, Lankeshwara Munasinghe and Mathew Nicho |
| 15:00 ~ 15:15 |
Utilization of SLMs as Generator in RAG
- Kouya Abe and Hiroyuki Shinnou |
14:50 ~ 15:05 |
Explainable AI for NLP: Enhancing Transparency in Sentiment Analysis and Named Entity Recognition
- Feras Elkharrat, Mohamed Ghoniem, Ahmed Sherif and Caroline Sabty |
| - Break (15:30 ~ 15:50) - | |||
🌸 Session 3: 15:50 ~ 17:30
| Room A | Room B | ||
|---|---|---|---|
Session chair: Benjamin Uwe Kille |
Session chair: Vijayan Sugumaran |
||
| 15:50 ~ 16:15 |
Memory Efficient LM Compression using Fisher Information from Low-Rank Representations
- Daniil Moskovskiy, Sergey Pletenev, Sergey Zagoruyko and Alexander Panchenko |
15:50 ~ 16:15 |
ViMRHP: A Vietnamese Benchmark Dataset for Multimodal Review Helpfulness Prediction via Human-AI Collaborative Annotation
- Truc Nguyen, Dat Nguyen, Son Luu and Kiet Nguyen |
| 16:15 ~ 16:40 |
Explaining Bias in Internal Representations of Large Language Models via Concept Activation Vectors
- Jasper Kyle Catapang |
16:15 ~ 16:40 |
Instruction Tuning TextFlow Semi-Automatic RFCs Generation
- Jie Bian |
| 16:40 ~ 16:55 |
FairNM: Fairness in Name Matching
- Yuan Liu and Flavius Frasincar |
16:40 ~ 17:05 |
Augmented method for Legal Textual Entailment
- Huy Chu, Hoang Chu, Phuong Nguyen and Minh Nguyen |
| 16:55 ~ 17:10 |
Repurposing Annotation Guidelines to Instruct LLM Annotators: A Case Study
- Kon Woo Kim, Rezarta Islamaj, Jin-Dong Kim, Florian Boudin and Akiko Aizawa |
||
| 17:10 ~ 17:25 |
Pretraining Data Exposure in Large Language Models: A Survey of Membership Inference, Data Contamination, and Security Implications
- Ziyi Tong, Feifei Sun and Le Minh Nguyen |
||
| - Banquet* (18:30 ~) - | |||
Note: The conference's banquet will be held at KKR Hotel (2-32 Otemachi, Kanazawa, Ishikawa 920-0912).
Day 2: July 5th (Sat)
| Room A | |
|---|---|
| 9:00 ~ 9:50 |
Keynote: Teaching Machines to Abstract: The Next Breakthrough for Large Language Models - Dr. Hen-Hsen Huang (Academia Sinica, Institute of Information Science, Taiwan) |

Title: Teaching Machines to Abstract: The Next Breakthrough for Large Language ModelsDr. Hen-Hsen HuangAcademia Sinica, Institute of Information Science, TaiwanAbstractThe fundamental skill of decomposing complex problems into manageable sub-problems—is central to computer science. While today's large language models (LLMs) excel at generalization, their reliance on linear, token-level reasoning prevents effective handling of hierarchical and high-order tasks. This talk highlights our pioneering work in explicitly training LLMs to abstract through algorithmic problem-solving scenarios, thereby enhancing their reasoning power, and discusses how this advancement can reshape the future role of AI across diverse applications. |
|
| - Break (9:50 ~ 10:10) - | |
🌸 Session 4: 10:10 ~ 11:50
| Room A | Room B | ||
|---|---|---|---|
Session chair: Ramakanth Kavuluru |
Session chair: Zhiru Sun |
||
| 10:10 ~ 10:35 |
Context Is The Key For LLM-Based Text Segmentation
- Amit Maraj and Miguel Martin |
10:10 ~ 10:35 |
CLIP-Driven Deep Hashing for Cross-Modal Retrieval
- Zhichao Han, Azreen Azman, Mas Rina Mustaffa and Fatimah Khalid |
| 10:35 ~ 11:00 |
WIP: Iterative Post-Training Pruning with Weighted Importance Estimation for Large Language Models
- Dinh Truong Do, Kiyoaki Shirai and Le Minh Nguyen |
10:35 ~ 11:00 |
Dual-Style Transcription of Historical Manuscripts based on Multimodal Small Language Models with Switchable Adapters
- Sergio Torres Aguilar |
| 11:00 ~ 11:25 |
A Survey of LoRA Algorithm Variations for Language Models
- Mengyao Zhu and Phuc Nguyen |
11:00 ~ 11:25 |
TopicVD: A Topic-Based Dataset of Video-Guided Multimodal Machine Translation for Documentaries
- Jinze Lv, Jian Chen, Zi Long, Xianghua Fu and Yin Chen |
| 11:25 ~ 11:40 |
Is a Similar Task Useful for Few-Shot Selection? Aspect Term Extraction Using LLM
- Koki Imazato and Kazutaka Shimada |
11:25 ~ 11:50 |
Multimodal Event Detection: Current Approaches and Defining the New Playground through LLMs and VLMs
- Abhishek Dey, Rishav Aryan, Saurabh Srivastava, Aabha Bothera, Samhita Sarikonda, Sanjay Kumar Podishetty, Akshay Havalgi and Gaurav Singh |
| 11:40 ~ 11:55 |
IRIS: Rapid Curation Framework for Iterative Improvement of Noisy Named Entity Annotations
- Ken Yano, Makoto Miwa and Sophia Ananiadou |
||
| - Lunch (12:10 ~ 13:10) - | |||
🌸 Session 5: 13:10 ~ 14:30
| Room A | Room B | ||
|---|---|---|---|
Session chair: Elena Tutubalina |
Session chair: Miguel Vargas Martin |
||
| 13:10 ~ 13:35 |
Multi-Scale Convolutional Fusion with Contrastive Feature Alignment for Imbalanced Data Classification
- Keito Inoshita, Takato Ueno and Xiaokang Zhou |
13:10 ~ 13:35 |
Unveiling Emotional Signature in Conspiracy Topics on Social Media through Vector Analysis
- Luigi Lomasto, Delfina Malandrino, Rocco Zaccagnino, Nicola Lettieri and Valerio Mosca |
| 13:35 ~ 14:00 |
CAFE: Context-aware Applicability-weighted Fairness Evaluation
- Fumian Chen and Hui Fang |
13:35 ~ 14:00 |
Semantic Reasoning for Device Identification in Dynamic Internet of Things Environments with Large Language Models
- Zhou Gui, Layla Kuty, Daniel Schraudner and Andreas Harth |
| 14:00 ~ 14:15 |
Exploration of Rationale-Extraction Methods for Closed-Domain Question Answering with a New Sentence-Level Rationale Dataset
- Lize Pirenne, Samy Mokeddem, Damien Ernst and Gilles Louppe |
14:00 ~ 14:25 |
QA2HALL: A Framework for Generating Non-trivial Hallucination Detection Datasets from KGQA Datasets
- Kosuke Nakamura, Rie Hasegawa, Kotaro Otomura, Ryutaro Ichise and Jumpei Hato |
| 14:15 ~ 14:30 |
Efficiently Summarizing Norwegian Legal Texts
- Tu My Doan, David Baumgartner and Benjamin Kille |
||
Excursion in KanazawaThe excursion will be held from 15:00 ~ 18:00 on Saturday, July 5. All conference participants are welcome to join for free. Explore the cultural highlights of Kanazawa, including Oyama-Jinjya Shrine, Gyokuseninmaru Garden, Kanazawa Castle, Kenrokuen Garden, and the 21st Century Museum of Contemporary Art. This guided tour offers a wonderful chance to experience the city's history, beauty, and creativity, while connecting with fellow participants. 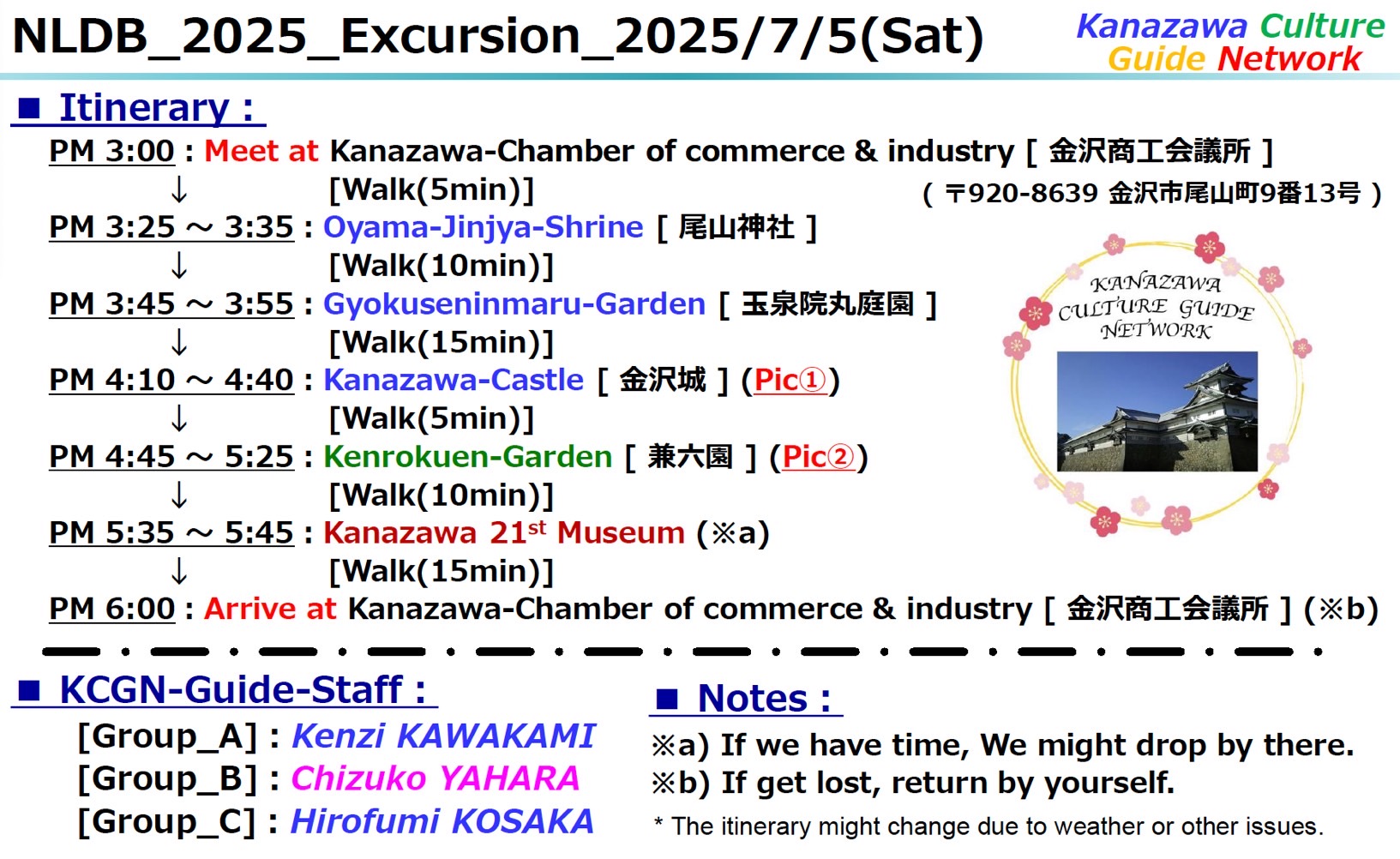
|
|||
Day 3: July 6th (Sun)
🌸 Session 6: 9:00 ~ 10:20
| Room A | Room B | ||
|---|---|---|---|
Session chair: Gui Zhou |
Session chair: Azreen Bin Azman |
||
| 9:00 ~ 9:25 |
ShortPathQA: A Dataset for Controllable Fusion of Large Language Models with Knowledge Graphs
- Mikhail Salnikov, Andrey Sakhovskiy, Irina Nikishina, Aida Usmanova, Angelie Kraft, Cedric Moller, Debayan Banerjee, Junbo Huang, Longquan Jiang, Rana Abdullah, Xi Yan, Ricardo Usbeck, Elena Tutubalina and Alexander Panchenko |
9:00 ~ 9:25 |
Comparison of pipelines, seq2seq models, and LLMs for rare disease information extraction
- Shashank Gupta, Xuguang Ai, Yuhang Jiang and Ramakanth Kavuluru |
| 9:25 ~ 9:50 |
The benefits of query-based KGQA systems for complex and temporal questions in LLM era
- Artem Alexeev, Mikhail Chaichuk, Miron Butko, Alexander Panchenko, Elena Tutubalina and Oleg Somov |
9:25 ~ 9:50 |
How important is domain-specific language model pretraining and instruction finetuning for biomedical relation extraction?
- Aviv Brokman and Ramakanth Kavuluru |
| 9:50 ~ 10:15 |
ReSHQ: Re-ranking Based on the Similarity between Hypothetical Query and Query
- Keito Fukuoka and Hisashi Miyamori |
9:50 ~ 10:05 |
Cross-Domain Named Entity Recognition: A Resource-Efficient Transfer Learning Approach
- Gianmaria Balducci, Elisabetta Fersini and Enza Messina |
| 10:05 ~ 10:20 |
EcoRAG: A Multi-Hop Economic QA Benchmark for Retrieval-Augmented Generation Using Knowledge Graphs
- Hanieh Khorashadizadeh, Sanju Tiwari, Farah Benamara, Nandana Mihindukulasooriya, Jinghua Groppe, Soror Sahri, Morteza Ezzabady, Frederic Ieng and Sven Groppe |
10:05 ~ 10:20 |
Duplicate Bug Report Retrieval for New Bug Reports
- Miao Hu, Zhiwei Lin and Adele Marshall |
| - Break (10:30 ~ 10:50) - | |||
🌸 Special Track: 10:50 ~ 12:20
| Room A: Industry/Demo Session | |||
|---|---|---|---|
Session chair: Kiyoaki Shirai |
|||
| 10:50 ~ 11:05 |
Should Embedding-Based News Recommendation Be Revisited? A Focus on the Differences Between News Publishers and Aggregators
- Takumi Tamura, Yoichiro Ito, Masaki Aota, Kenta Yamada and Shotaro Ishihara |
||
| 11:05 ~ 11:20 |
A Simple Ensemble Strategy for LLM Inference: Towards More Stable Text Classification
- Junichiro Niimi |
||
| 11:20 ~ 11:35 |
Testing Procedure Generation based on Testing requirements for Automotive Components with LLM fine-tuning
- Man Yiu Chow and Mitsuhiro Kitani |
||
| 11:35 ~ 11:50 |
OpenThaiGPT 1.5: A Thai-Centric Open Source Large Language Model
- Sumeth Yuenyong, Kobkrit Viriyayudhakorn, Apivadee Piyatumrong and Jillaphat Jaroenkantasima |
||
| 11:50 ~ 12:05 |
ESG-Consultant: Developing of an ESG Compliance Consulting Tool for Companies Using RAG
- Angel Ontiveros, Irina Nikishina, Moritz Gomm, Christopher Schmit and Chris Biemann |
||
| 12:05 ~ 12:20 |
CaLuX: A Catalyst and Lubricant Properties Extraction System for Domain Experts
- Catalina Riano and Hui Fang |
||
| - Closing Ceremony (12:20-12:45) - | |||