HA3CI Research
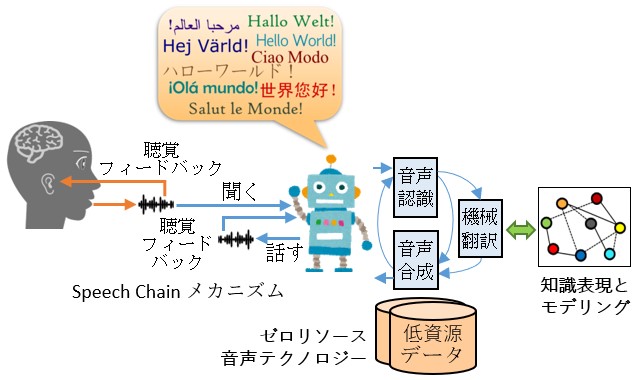
音声認識と合成
自動音声認識(ASR)およびテキスト読み上げ合成(TTS)を使用して、聞き取りと話しができるテクノロジーを研究および開発します。考えられる研究トピックには、多言語/コードスイッチングASRとTTS、インクリメンタルASRとTTS、が含まれます。
関連論文:
- S. Novitasari, A. Tjandra, S. Sakti, S. Nakamura, "Sequence-to-sequence Learning via Attention Transfer for Incremental Speech Recognition", Proc. of Interspeech 2019, Graz, Austria, Sep 2019 [PDF]
- T. Yanagita, S. Sakti and S. Nakamura, "Neural iTTS: Toward Synthesizing Speech in Real-time with End-to-end Neural Text-to-Speech Framework 10th Speech Synthesis Workshop (SSW10), Sep. 2019 [PDF]
- M. Okamoto, S. Sakti and S. Nakamura, "Towards Speech Entrainment: Considering ASR Information in Speaking Rate Variation of TTS Waveform Generation Oriental COCOSDA, pp.139-144, Nov. 6, 2020 [PDF]
- S. Nakayama, A. Tjandra, S. Sakti, S. Nakamura, "Code-Switching ASR and TTS using Semisupervised Learning with Machine Speech Chain", IEICE Transactions on Information and Systems, Vol.E104-D, No.10, July. 7-8, 2021 [PDF]
マシンスピーチチェーン
この研究は、人間の発話知覚と発話生成を統合することに焦点を当てており、聞くことも話すこともできる技術を提供するだけでなく、話している間に聞くこともできます。考えられる研究トピックには、多言語/マルチモーダルスピーチチェーン、インクリメンタルスピーチチェーン、音声エントレインメントが含まれます。
関連論文:
- A. Tjandra, S. Sakti, S. Nakamura, "Machine Speech Chain," IEEE/ACM Transactions on Audio, Speech, and Language Processing, Vol. 28, pp. 976-989, 2020 [PDF]
- S. Novitasari, A. Tjandra, S. Sakti, S. Nakamura, "Cross-Lingual Machine Speech Chain for Javanese, Sundanese, Balinese, and Bataks Speech Recognition and Synthesis", Proc. SLTU-CCURL, pp. 131-138, May 2020 [PDF]
- J. Effendi, A. Tjandra, S. Sakti, S. Nakamura, "Multimodal Chain: Cross-Modal Collaboration Through Listening, Speaking, and Visualizing", IEEE Access, pp. 70286-70299, 2021 [PDF]
- S. Novitasari, S. Sakti, S. Nakamura, "Dynamically Adaptive Machine Speech Chain Inference for TTS in Noisy Environment: Listen and Speak Louder", Proc. Interspeech 2021, pp. 4124-4128, Aug. 30, 2021 [PDF]
ゼロリソース音声技術
幼児のような言語を学び、徐々に知識を構築することができる技術の開発に焦点を当てています。考えられる研究トピックには、ゼロリソース音声処理、教師なし/半教師あり深層学習、知識表現およびモデリングが含まれます。
関連論文:
- M. Heck, S. Sakti, S. Nakamura, "Feature Optimized DPGMM Clustering for Unsupervised Subword Modeling: A Contribution to ZeroSpeech 2017", Proceedings of IEEE Automatic Speech Recognition and Understanding (ASRU), 2017 [PDF]
- A. Tjandra, B. Sisman, M. Zhang, S. Sakti, H. Li, S. Nakamura, "VQVAE Unsupervised Unit Discovery and Multi-Scale Code2Spec Inverter for Zerospeech Challenge 2019", Interspeech, 2019 [PDF]
- B. Wu, S. Sakti, J. Zhang and S. Nakamura, "Tackling Perception Bias in Unsupervised Phoneme Discovery Using DPGMM-RNN Hybrid Model and Functional Load", IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2020", Proc. SLTU-CCURL, pp. 131-138, May 2020 [PDF]
- S. Takahashi, S. Sakti, S. Nakamura, "Unsupervised Neural-Based Graph Clustering for Variable-Length Speech Representation Discovery of Zero-Resource Languages", Proc. Interspeech 2021, pp. 1559-1563, 2021 [PDF]
- J. Effendi, S. Sakti, S. Nakamura, "End-to-End Image-to-Speech Generation for Untranscribed Unknown Languages", IEEE Access, pp.55144-55154, Apr. 7, 2021 [PDF]
音声翻訳
この研究は、テキストに翻訳されるのではなく、音声から音声に直接翻訳される人間のような同時音声解釈に焦点を当てており、言語情報とパラ言語情報の両方をカバーしています。考えられる研究トピックには、音声から音声への翻訳、パラ言語表現の翻訳が含まれます。
関連論文:
- T. Kano, S. Sakti, S. Nakamura, "End-to-end Speech Translation with Transcoding by Multi-task Learning for Distant Language Pairs", IEEE/ACM Transactions on Audio, Speech and Language Processing, Vol: 28, No. 1, pp. 1342-1355, 2020 [PDF]
- Q.-T. Do, S. Sakti, and S. Nakamura, "Sequence-to-Sequence Models for Emphasis Speech Translation", IEEE/ACM Transactions on Audio, Speech, and Language Processing, Vol. 26, No. 10, 2018 [PDF]
- H. Tokuyama, S. Sakti, Katsuhito Sudoh, S. Nakamura, "Transcribing Paralinguistic Acoustic Cues to Target Language Text in Transformer-Based Speech-to-Text Translation", Proc. Interspeech 2021, pp. 2262-2266, 2021 [PDF]
- A. Tjandra, S. Sakti, S. Nakamura, "Speech-to-speech Translation between Untranscribed Unknown Languages", Proc. of the IEEE Automatic Speech Recognition and Understanding (ASRU) Workshop, 2019 [PDF]
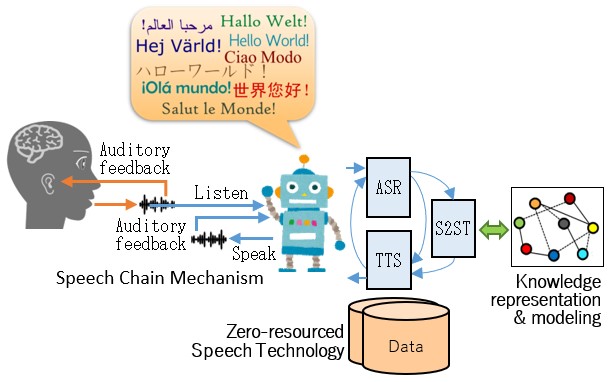
Speech recognition and synthesis
Research and develop technologies that can listen and speak by way of automatic speech recognition (ASR) and text-to-speech synthesis (TTS). Possible research topics include multilingual/code-switching ASR & TTS, incremental ASR & TTS.
Related papers:
- S. Novitasari, A. Tjandra, S. Sakti, S. Nakamura, "Sequence-to-sequence Learning via Attention Transfer for Incremental Speech Recognition", Proc. of Interspeech 2019, Graz, Austria, Sep 2019 [PDF]
- T. Yanagita, S. Sakti and S. Nakamura, "Neural iTTS: Toward Synthesizing Speech in Real-time with End-to-end Neural Text-to-Speech Framework 10th Speech Synthesis Workshop (SSW10), Sep. 2019 [PDF]
- M. Okamoto, S. Sakti and S. Nakamura, "Towards Speech Entrainment: Considering ASR Information in Speaking Rate Variation of TTS Waveform Generation Oriental COCOSDA, pp.139-144, Nov. 6, 2020 [PDF]
- S. Nakayama, A. Tjandra, S. Sakti, S. Nakamura, "Code-Switching ASR and TTS using Semisupervised Learning with Machine Speech Chain", IEICE Transactions on Information and Systems, Vol.E104-D, No.10, July. 7-8, 2021 [PDF]
Machine speech chain
The research focuses on integrating human speech perception & production behaviors, not only to provide technology that can listen and speak but also listen while speaking. Possible research topics include multilingual/multimodal speech chain, incremental speech chain, speech entrainment.
Related papers:
- A. Tjandra, S. Sakti, S. Nakamura, "Machine Speech Chain," IEEE/ACM Transactions on Audio, Speech, and Language Processing, Vol. 28, pp. 976-989, 2020 [PDF]
- S. Novitasari, A. Tjandra, S. Sakti, S. Nakamura, "Cross-Lingual Machine Speech Chain for Javanese, Sundanese, Balinese, and Bataks Speech Recognition and Synthesis", Proc. SLTU-CCURL, pp. 131-138, May 2020 [PDF]
- J. Effendi, A. Tjandra, S. Sakti, S. Nakamura, "Multimodal Chain: Cross-Modal Collaboration Through Listening, Speaking, and Visualizing", IEEE Access, pp. 70286-70299, 2021 [PDF]
- S. Novitasari, S. Sakti, S. Nakamura, "Dynamically Adaptive Machine Speech Chain Inference for TTS in Noisy Environment: Listen and Speak Louder", Proc. Interspeech 2021, pp. 4124-4128, Aug. 30, 2021 [PDF]
Zero-resourced Speech Technology
The research focuses on developing technologies that can learn a language like a toddler and gradually construct knowledge. Possible research topics include zero-resource speech processing, unsupervised/semi-supervised deep learning, knowledge representation & modeling.
Related papers:
- M. Heck, S. Sakti, S. Nakamura, "Feature Optimized DPGMM Clustering for Unsupervised Subword Modeling: A Contribution to ZeroSpeech 2017", Proceedings of IEEE Automatic Speech Recognition and Understanding (ASRU), 2017 [PDF]
- A. Tjandra, B. Sisman, M. Zhang, S. Sakti, H. Li, S. Nakamura, "VQVAE Unsupervised Unit Discovery and Multi-Scale Code2Spec Inverter for Zerospeech Challenge 2019", Interspeech, 2019 [PDF]
- B. Wu, S. Sakti, J. Zhang and S. Nakamura, "Tackling Perception Bias in Unsupervised Phoneme Discovery Using DPGMM-RNN Hybrid Model and Functional Load", IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2020", Proc. SLTU-CCURL, pp. 131-138, May 2020 [PDF]
- S. Takahashi, S. Sakti, S. Nakamura, "Unsupervised Neural-Based Graph Clustering for Variable-Length Speech Representation Discovery of Zero-Resource Languages", Proc. Interspeech 2021, pp. 1559-1563, 2021 [PDF]
- J. Effendi, S. Sakti, S. Nakamura, "End-to-End Image-to-Speech Generation for Untranscribed Unknown Languages", IEEE Access, pp.55144-55154, Apr. 7, 2021 [PDF]
Speech Translation
The research focuses on human-like simultaneous speech interpretation that does not translate into text but directly from speech to speech, covering both linguistic and paralinguistic information. Possible research topics include direct speech translation, paralinguistic representation & translation.
関連論文:
- T. Kano, S. Sakti, S. Nakamura, "End-to-end Speech Translation with Transcoding by Multi-task Learning for Distant Language Pairs", IEEE/ACM Transactions on Audio, Speech and Language Processing, Vol: 28, No. 1, pp. 1342-1355, 2020 [PDF]
- Q.-T. Do, S. Sakti, and S. Nakamura, "Sequence-to-Sequence Models for Emphasis Speech Translation", IEEE/ACM Transactions on Audio, Speech, and Language Processing, Vol. 26, No. 10, 2018 [PDF]
- H. Tokuyama, S. Sakti, Katsuhito Sudoh, S. Nakamura, "Transcribing Paralinguistic Acoustic Cues to Target Language Text in Transformer-Based Speech-to-Text Translation", Proc. Interspeech 2021, pp. 2262-2266, 2021 [PDF]
- A. Tjandra, S. Sakti, S. Nakamura, "Speech-to-speech Translation between Untranscribed Unknown Languages", Proc. of the IEEE Automatic Speech Recognition and Understanding (ASRU) Workshop, 2019 [PDF]