
人間の内面・コミュニケーション・行動を理解する計算モデルによる社会的人工知能の実現
社会的信号処理・マルチモーダルインタラクション研究室
Social Signal and Multimodal Interaction Laboratory
教授:岡田 将吾(OKADA Shogo)
E-mail:
[研究分野]
マルチモーダルインタラクション、データマイニング、機械学習、パターン認識
[キーワード]
社会的信号処理、コミュニケーションのモデル化、Affective Computing、Social Computing
研究を始めるのに必要な知識・能力
画像/音声情報処理、時系列データ解析、線形代数、確率・統計、機械学習、プログラミングの知識・経験のいずれかを有していることが望ましいです。ただし研究室に入った後でも、研究テーマごとに必要な基礎知識の勉強会を行うので心配いりません。一番重要なのは機械学習・データマイニングを駆使して人間の行動、内面状態、対人コミュニケーションをモデル化することに興味があり、地道に研究目標に向かって研究を進めようとする「やる気・持続力」が重要となります。
この研究で身につく能力
機械学習、データマイニング、信号処理を、人間行動・内面状態・コミュニケーションの理解・実現に応用するという立場で研究を行います。例えば、どのようなコミュニケーションの側面を捉えることで新しい応用先が見つかるか、その側面を捉えるためにはどのようなセンサを利用してデータを取るか、といった問題設定とデータ収集から研究がスタートすることが多いです。このため問題設定の立案、データ収集、信号処理・機械学習・データマイニング、アウトプットの分析・可視化といったデータサイエンティストに必要な一連の素養を身につけることが出来ます。機械学習に基づく人工知能システムは多用な応用先を有しており、社会で扱われる問題も広範囲かつ複雑になっています。上記の複雑な問題に人工知能技術を適用し、問題を解決するための方法論を習得させることを目指します。
研究内容
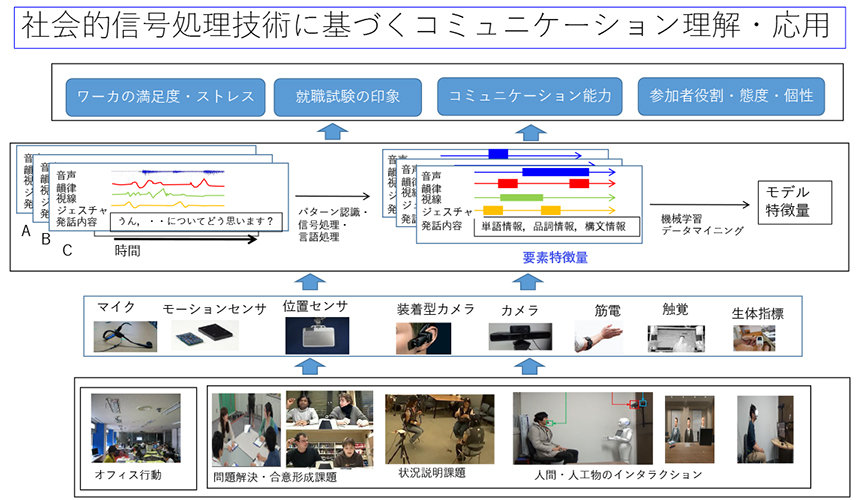 機械学習、データマイニング、パターン認識、信号処理の技術を駆使し人間の行動、人間同士のコミュニケーション・インタラクションから観測される言語・非言語情報から態度・状況・グループコミュニケーションの質・コミュニケーションスキル、感情、人の関係性といった高次の抽象的概念をモデル化する技術と、インタラクティブシステム、会話エージェントへの応用に関する研究を行っています。これらの研究は社会的信号処理(Social Signal Processing)と呼ばれており、人間と共感し、適応する社会的人工知能の実現に欠かせません。
機械学習、データマイニング、パターン認識、信号処理の技術を駆使し人間の行動、人間同士のコミュニケーション・インタラクションから観測される言語・非言語情報から態度・状況・グループコミュニケーションの質・コミュニケーションスキル、感情、人の関係性といった高次の抽象的概念をモデル化する技術と、インタラクティブシステム、会話エージェントへの応用に関する研究を行っています。これらの研究は社会的信号処理(Social Signal Processing)と呼ばれており、人間と共感し、適応する社会的人工知能の実現に欠かせません。
[1:マルチモーダルインタラクション]
各種センサで観測した、会話参加者の発話内容(言語)・韻律・視線・姿勢・ジェスチャ・心拍や皮膚電位などの生体信号を処理・解析するマルチモーダルセンシング技術と、マルチモーダルな特徴量を扱う機械学習技術に基づき、抽出・統合・階層化することで、①対話中の非言語行動の理解、②会話者の感情、態度、発話意欲といった会話参加者の高次状態・意図の推定、③コミュニケーションスキル、説明するスキル、面接スキル、プレゼンスキルの推定、④2者の関係性、グループディスカッションの質の推定に関する研究を行っています。
[2:ユビキタスセンサを用いた人間行動理解]
自動車運転行動解析:様々な道路の運転中に観測されるアクセル・ブレーキ・操舵角の時系列データから、運転者個人の性格・運転スタイル・認知状態等を予測するモデルを研究開発し、個人適合型運転支援システムの実現を目指しています。
高齢者の認知状態のモニタリング:認知症の早期発見に向けて、認知機能をできる限り負荷をかけずにモニタリングするために、i-beacon、ベッドセンサ等を利用して、移動・睡眠データに基づき認知機能の低下傾向を予測する技術を研究しています。
[3:マルチモーダル・時系列データのための機械学習]
1:、2: の技術の根幹はマルチモーダルデータ・時系列データの機械学習・データマイニングの手法により支えられています。深層学習における時間構造の異なる異種のモダリティデータの統合方法、少量のラベル付き教師データを用いて学習する方法(半教師付き学習、転移学習)、曖昧なラベルデータを用いて学習する方法(弱教師付き学習)、系列データから多用な特徴量を抽出するデータマイニングの手法等の研究を行っています。
主な研究業績
- Shogo Okada et al, Modeling Dyadic and Group Impressions with Intermodal and Interperson Features. ACM Transactions on. Multimedia Computing, Communications, and Applications (TOMM) 15(1s): 13:1-13:30 (2019)
- Shun Katada, Shogo Okada and Kazunori Komatani, Effects of Physiological Signals in Different Types of Multimodal Sentiment Estimation, IEEE Transactions on Affective Computing, vol. 14, no. 3, pp. 2443-2457, 1 (2023)
- Fuminori Nagasawa, Shogo Okada, et al, Adaptive Interview Strategy Based on Interviewee’s Speaking Willingness Recognition for Interview Robots, IEEE Transactions on Affective Computing, Early Access (2023)
使用装置
ビデオカメラ、ウェアラブルカメラ、マイクロフォンアレイ、Kinect、携帯型筋電センサ、加速度・ジャイロセンサ、VRゴーグル、ヒューマノイドロボット
研究室の指導方針
2017年度に発足した研究室です。研究の基盤となる機械学習・データマイニング・パターン認識の勉強と同時に、研究室でターゲットとしている研究分野の最新の成果とのつながりを明確にしながら、勉強と研究を進めていきます。
これにより、世界の研究水準を知ると同時に、その水準での研究に挑戦することを目指します。
[研究室HP] URL:https://www.jaist.ac.jp/~okada-s/