|
|
| PAPERS (01/Jul/2017) |
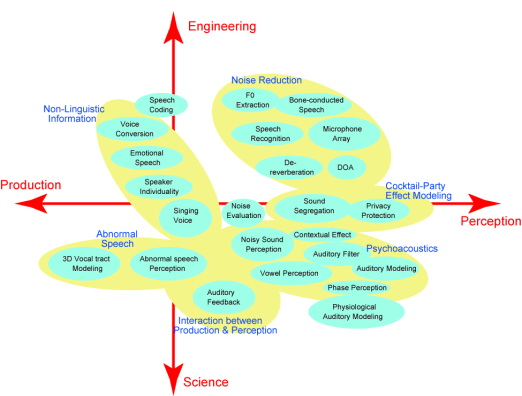
1. Non-linguistic Information
1-1 Singing Voice
1-2 Speaker Individuality
1-3 Emotional Speech
1-4 Voice Conversion
1-5 Speech Coding
2. Speech recovery
2-1 Noise Reduction
2-2 F0 Extraction
2-3 De-reverberation
2-4 Bone-conducted Speech
2-5 Speech Recognition
2-6 DOA
3. Cocktail-party Effect Modeling
3-1 Sound Segregation
3-2 Privacy Protection
3-3 Noisy Sound Perception
4. Psychoacoustics
4-1 Auditory Model
4-2 Contextual Effect
4-3 Auditory Filter
4-4 Phase Perception
4-5 Speech Perception
4-6 Noise Evaluation
4-7 Pitch Perception
4-8 Direction Perception
5. Physiological Auditory Modeling
6. Abnormal Speech
6-1 Abnormal Speech Perception
6-2 3D Vocal Tract Modeling
7. Interaction between Perception and Production
8. Signal Analysis
9. Others
9-1 NTT & ATR
9-2 Tokyo Institute of Technology
|
If you are interested in my research topics and want to see my publications,
why don't you visit the JAIST Repositry and download my papers?

|
1. Non-linguistic Information
[1] Akagi, M. (2010/11/29). “Rule-based voice conversion derived from expressive
speech perception model: How do computers sing a song joyfully?” Tutorial,
ISCSLP2010, Tainan, Taiwan.
[2] Akagi, M. (2009/10/6). "Analysis of production and perception
characteristics of non-linguistic information in speech and its application
to inter-language communications," Proc. APSIPA2009, Sapporo, 513-519.
[3] Akagi, M. (2009/08/14). “Multi-layer model for expressive speech perception and its application to expressive speech synthesis,” Plenary lecture, NCMMSC2009, Lanzhou, China.
[4] Akagi, M. (2009/02/20). "Introduction of SCOPE project: Analysis of production and perception characteristics of non-linguistic information in speech and its application to inter-language communications," International symposium on biomechanical and physiological modeling and speech science, 51-62.
1-1 Singing Voice
[1] Motoda, H. and Akagi, M. (2013/03/5). “A singing voices synthesis system
to characterize vocal registers using ARX-LF model,” Proc. NCSP2013, Hawaii,
USA, 93-96.
[2] Saitou, T., Goto, M., Unoki, M., and Akagi, M. (2009/08/15). “Speech-to-Singing
Synthesis System: Vocal Conversion from Speaking Voices to Singing Voices
by Controlling Acoustic Features Unique to Singing Voices,” NCMMSC2009,
Lanzhou, China.
[3] Nakamura, T., Kitamura, T. and Akagi, M. (2009/03/01). "A study
on nonlinguistic feature in singing and speaking voices by brain activity
measurement," Proc. NCSP'09, 217-220.
[4] Saitou, T., Goto, M., Unoku, M., and Akagi, M. (2007). "Speech-to-singing synthesis: converting speaking voices to singing voices by controlling acoustic features unique to singing voices," Proc. WASPAA2007, New Paltz, NY, pp.215-218
[5] Saitou, T., Goto, M., Unoki, M., and Akagi, M. (2007). "Vocal
conversion from speaking voice to singing voice using STRAIGHT," Proc.
Interspeech2007, Singing Challenge.
[6] Saitou, T., Unoki, M., and Akagi, M. (2006). "Analysis of acoustic
features affecting singing-voice perception and its application to singing-voice
synthesis from speaking-voice using STRAIGHT," J. Acoust. Soc. Am.,
120, 5, Pt. 2, 3029.
[7] Saitou, T., Unoki, M. and Akagi, M. (2005). "Development of an F0 control model based on F0 dynamic characteristics for singing-voice synthesis," Speech Communication 46, 405-417.
[8] Saitou, T., Tsuji, N., Unoki, M. and Akagi, M. (2004). “Analysis of
acoustic features affecting “singing-ness” and its application to singing-voice
synthesis from speaking-voice,” Proc. ICSLP2004, Cheju, Korea.
[9] Saitou, T., Unoki, M., and Akagi, M. (2004). “Control methods of acoustic
parameters for singing-voice synthesis,” Proc. ICA2004, 501-504.
[10] Saitou, T., Unoki, M., and Akagi, M. (2004). “Development of the F0 control method for singing-voices synthesis,” Proc. SP2004, Nara, 491-494.
[11] Akagi, M. (2002). "Perception of fundamental frequency fluctuation,"
HEA-02-003-IP, Forum Acousticum Sevilla 2002 (Invited).
[12] Saitou, T., Unoki, M., and Akagi, M. (2002). "Extraction of F0
dynamic characteristics and development of F0 control model in singing
voice," Proc. ICAD2002, Kyoto.
[13] Unoki, M., Saitou, T., and Akagi, M. (2002). "Effect of F0 fluctuations and development of F0 control model in singing voice perception," NATO Advanced Study Institute 2002 Dynamics of Speech Production and Perception.
[14] Akagi, M. and Kitakaze, H. (2000). "Perception of synthesized singing voices with fine fluctuations in their fundamental frequency contours," Proc. ICSLP2000, Beijing, III-458-461.
1-2 Speaker Individuality
[1] Izumida, T. and Akagi, M. (2012/03/05). “Study on hearing impression
of speaker identification focusing on dynamic features,” Proc. NCSP2012,
Honolulu, HW, 401-404.
[2] Akagi, M., Iwaki, M. and Minakawa, T. (1998). “Fundamental frequency fluctuation in continuous vowel utterance and its perception,” ICSLP98, Sydney, Vol.4, 1519-1522.
[3] Akagi, M. and Ienaga, T. (1997). "Speaker individuality in fundamental
frequency contours and its control", J. Acoust. Soc. Jpn. (E), 18,
2 73-80.
[4] Kitamura, T. and Akagi, M. (1996). "Relationship between physical
characteristics and speaker individualities in speech spectral envelopes",
Proc ASA-ASJ Joint Meeting, 833-838.
[5] Akagi, M. and Ienaga, T. (1995). "Speaker individualities in fundamental frequency contours and its control", Proc. EUROSPEECH95, 439-442.
[6] Kitamura, T. and Akagi, M. (1995). "Speaker individualities in
speech spectral envelopes", J. Acoust. Soc. Jpn. (E), 16, 5, 283-289.
[7] Kitamura, T. and Akagi, M. (1994). "Speaker Individualities in
speech spectral envelopes", Proc. Int. Conf. Spoken Lang. Process.
94, 1183-1186.
1-3 Emotional Speech
[1] Asai, T., Suemitsu, A., and Akagi, M. (2017/03/02). “Articulatory Characteristics
of Expressive Speech in Activation-Evaluation Space,” Proc. NCSP2017, Guam,
USA, 313-316.
[2] Xue, Y., Hamada, Y., and Akagi, M. (2016/12/15). “Voice Conversion
to Emotional Speech based on Three-layered Model in Dimensional Approach
and Parameterization of Dynamic Features in Prosody,” Proc. APSIPA2016,
Cheju, Korea
[3] Akagi, M. (2016/12/13). “Toward Affective Speech-to-Speech Translation,” Keynote Speech, International Conference on Advances in Information and Communication Technology 2016, Thai Nguyen, Vietnam, DOI 10.1007/978-3-319-49073-1 3.
[4] Li, Y., Morikawa, D., and Akagi, M. (2016/11/28). “A method to estimate
glottal source waves and vocal tract shapes for widely pronounced types
using ARX-LF model,” 2016 ASA-ASJ Joint meeting, Honolulu, Hawaii, JASA
140, 2963. doi: http://dx.doi.org/10.1121/1.4969159
[5] Xue, Y., Hamada, Y., and Akagi, M. (2016/11/28). “Emotional voice conversion
system for multiple languages based on three-layered model in dimensional
space,” 2016 ASA-ASJ Joint meeting, Honolulu, Hawaii, JASA 140, 2960. doi:
http://dx.doi.org/10.1121/1.4969141
[6] Xue, Y., Hamada, Y., Elbarougy, R., and Akagi, M. (2016/10/27). “Voice conversion system to emotional speech in multiple languages based on three-layered model for dimensional space,” O-COCOSDA2016, Bali, Indonesia, 122-127.
[7] Elbarougy, R. and Akagi, M. (2016/10/24). “Optimizing Fuzzy Inference
Systems for Improving Speech Emotion Recognition,” The 2nd International
Conference on Advanced Intelligent Systems and Informatics (AISI2016),
Cairo, Egypt, 85-95.
[8] Li, X. and Akagi, M. (2016/09/12). “Multilingual Speech Emotion Recognition
System Based on a Three-Layer Model,” Proc. InterSpeech2016, San Francisco,
3608-3612.
[9] Xue, Y. and Akagi, M. (2016/03/07). “A study on applying target prediction model to parameterize power envelope of emotional speech,” Proc. NCSP2016, Honolulu, HW, USA, 157-160.
[10] Li, X. and Akagi, M. (2016/03/07). “Automatic Speech Emotion Recognition
in Chinese Using a Three-layered Model in Dimensional Approach,” Proc.
NCSP2016, Honolulu, HW, USA, 17-20.
[11] Xue, Y., Hamada, Y., and Akagi, M. (2015/12/19). “Emotional speech
synthesis system based on a three-layered model using a dimensional approach,”
Proc. APSIPA2015, Hong Kong, 505-514.
[12] Hamada, Y., Elbarougy, R., Xue, Y., and Akagi, M. (2015/12/9). “Study on method to control fundamental frequency contour related to a position on Valence-Activation space,” Proc. WESPAC2015, Singapore, 519-522.
[13] Li, X. and Akagi, M. (2015/10/28). “Toward Improving Estimation Accuracy
of Emotion Dimensions in Bilingual Scenario Based on Three-layered Model,”
Proc. O-COCOSDA2015, Shanghai, 21-26.
[14] Xiao Han, Reda Elbarougy, Masato Akagi,Junfeng Li, Thi Duyen Ngo,
and The Duy Bui (2015/02/28). “A study on perception of emotional states
in multiple languages on Valence-Activation approach,” Proc NCSP2015, Kuala
Lumpur, Malaysia.
[15] Yasuhiro Hamada, Reda Elbarougy and Masato Akagi (2014/12/12). “A Method for Emotional Speech Synthesis Based on the Position of Emotional State in Valence-Activation Space,” Proc. APSIPA2014, Siem Reap, Cambodia.
[16] Masato AKAGI, Xiao HAN, Reda ELBAROUGY, Yasuhiro HAMADA, and Junfeng
LI (2014/12/10). “Toward Affective Speech-to-Speech Translation: Strategy
for Emotional Speech Recognition and Synthesis in Multiple Languages,”
Proc. APSIPA2014, Siem Reap, Cambodia.
[17] Elbarougy. R., Han.X., Akagi, M., and Li, J. (2014/09/10). “Toward
relaying an affective speech-to-speech translator: Cross-language perception
of emotional state represented by emotion dimensions,” Proc. O-COCOSDA2014,
Phuket, Thailand, 48-53.
[18] Akagi, M., Han, X., El-Barougy, R., Hamada, Y. and Li, J. (2014/08/27). “Emotional Speech Recognition and Synthesis in Multiple Languages toward Affective Speech-to-Speech Translation System,” Proc. IIHMSP2014, Kitakyushu, Japan, 574-577.
[19] Akagi, M. and Elbarougy, R. (2014/07/16). “Toward Relaying Emotional
State for Speech-To-Speech Translator: Estimation of Emotional State for
Synthesizing Speech with Emotion,” Proc. ICSV2014. Beijing.
[20] Li, Y. and Akagi, M. (2014/03/02). “Glottal source analysis of emotional
speech,” Proc. NCSP2014, Hawaii, USA, 513-516.
[21] Elbarougy, R. and Akagi, M. (2014/03/01). “Improving Speech Emotion Dimensions Estimation Using a Three-Layer Model for Human Perception,” Acoustical Science and Technology, 35, 2, 86-98.
[22] Elbarougy, R. and Akagi, M. (2013/11/01). “Cross-lingual speech emotion
recognition system based on a three-layer model for human perception,”
Proc. APSIPA2013, Kaohsiung, Taiwan.
[23] Elbarougy, R. and Akagi, M. (2012/12/04). “Speech Emotion Recognition
System Based on a Dimensional Approach Using a Three-Layered Model,” Proc.
APSIPA2012, Hollywood, USA.
[24] Dang, J., Li, A., Erickson, D., Suemitsu, A., Akagi, M., Sakuraba, K., Mienmatasu, N., and Hirose, K. (2010/11/01). “Comparison of emotion perception among different cultures,” Acoust. Sci. & Tech. 31, 6, 394-402.
[25] Zhou, Y., Li, J., Sun, Y., Zhang, J., Yan, Y., and Akagi, M. (2010/10).
“A hybrid speech emotion recognition system based on spectral and prosodic
features,” IEICE Trans. Info. & Sys., E93D (10): 2813-2821.
[26] Hamada, Y., Kitamura, T., and Akagi, M. (2010/08/24). “A study on
brain activities elicited by emotional voices with various F0 contours,”
Proc. ICA2010, Sydney, Australia.
[27] Hamada, Y., Kitamura, T., and Akagi, M. (2010/07/01). “A study of brain activities elicited by synthesized emotional voices controlled with prosodic features,” Journal of Signal Processing, 14, 4, 265-268.
[28] Hamada, Y., Kitamura, T., and Akagi, M. (2010/03/04). "A study
on brain activities elicited by synthesized emotional voices controlled
with prosodic features," Proc. NCSP10, Hawaii, USA, 472-475.
[29] Dang, J., Li, A., Erickson, D., Suemitsu, A., Akagi, M., Sakuraba,
K., Minematsu, N., and Hirose, K. (2009/10/6). "Comparison of emotion
perception among different cultures," Proc. APSIPA2009, Sapporo, 538-544.
[30] Aoki, Y., Huang, C-F., and Akagi, M. (2009/03/01). "An emotional speech recognition system based on multi-layer emotional speech perception model," Proc. NCSP'09, 133-136.
[31] Huang, C. F. and Akagi, M. (2008/10) "A three-layered model for
expressive speech perception," Speech Communication 50, 810-828.
[32] Huang, C. F., Erickson, D., and Akagi, M. (2008/07/01). "Comparison
of Japanese expressive speech perception by Japanese and Taiwanese listeners,"
Acoustics2008, Paris, 2317-2322.
[33] Huang, C. F. and Akagi, M. (2007). "A rule-based speech morphing for verifying an expressive speech perception model," Proc. Interspeech2007, 2661-2664.
[34] Sawamura K., Dang J., Akagi M., Erickson D., Li, A., Sakuraba, K.,
Minematsu, N., and Hirose, K. (2007). "Common factors in emotion perception
among different cultures," Proc. ICPhS2007, 2113-2116.
[35] Huang, C. F. and Akagi, M. (2007). "The building and verification
of a three-layered model for expressive speech perception," Proc.
JCA2007, CD-ROM.
[36] Huang, C. F. and Akagi, M. (2005). "Toward a rule-based synthesis of emotional speech on linguistic description of perception," Affective Computing and Intelligent Interaction, Springer LNCS 3784, 366-373.
[37] Huang, C. F. and Akagi, M. (2005). "A Multi-Layer fuzzy logical
model for emotional speech Perception," Proc. EuroSpeech2005, Lisbon,
Portugal, 417-420.
[38] Ito, S., Dang, J., and Akagi, M. (2004). “Investigation of the acoustic
features of emotional speech using physiological articulatory model,” Proc.
ICA2004, 2225-2226.
1-4 Voice Conversion
[1] Dinh, A. T., Phan, T. S., and Akagi, M. (2016/12/12). “Quality Improvement
of Vietnamese HMM-Based Speech Synthesis System Based on Decomposition
of Naturalness and Intelligibility Using Non-negative Matrix Factorization,”
International Conference on Advances in Information and Communication Technology
2016, Thai Nguyen, Vietnam, 490-499, DOI 10.1007/978-3-319-49073-1 53.
[2] Dinh, A. T. and Akagi, M. (2016/10/26). “Quality Improvement of HMM-based
Synthesized Speech Based on Decomposition of Naturalness and Intelligibility
using Non-Negative Matrix Factorization,” O-COCOSDA2016, Bali, Indonesia,
62-67.
[3] Dinh, T. A, Morikawa, D., and Akagi, M. (2016/07/01), “Study on quality
improvement of HMM-based synthesized voices using asymmetric bilinear model,”
Journal of Signal Processing, 20, 4, 205-208.
[4] Dinh, T. A, Morikawa, D., and Akagi, M. (2016/03/07), “A study on quality improvement of HMM-based synthesized voices using asymmetric bilinear model,” Proc. NCSP2016, Honolulu, HW, USA, 13-16.
[5] Phung Trung Nghia, Luong Chi Mai, Masato Akagi (2015). “Improving the
naturalness of concatenative Vietnamese speech synthesis under limited
data conditions,” Journal of Computer Science and Cybernetics, V.31, N.1,
1-16.
[6] Phung, T. N., Phan, T. S., Vu, T. T., Loung, M. C., and Akagi, M. (2013/11/01).
“Improving naturalness of HMM-based TTS trained with limited data by temporal
decomposition,” IEICE Trans. Inf. & Syst., E96-D, 11, 2417-2426.
[7] Phung, T. N., Luong, M. C., and Akagi, M. (2013/09/02). “A Hybrid TTS between Unit Selection and HMM-based TTS under limited data conditions,” Proc. 8th ISCA Speech Synthesis Workshop, Barcelona, Spain 281-284.
[8] Phung, T. N., Luong, M. C., and Akagi, M. (2012/12/12). “Transformation
of F0 contours for lexical tones in concatenative speech synthesis of tonal
languages,” Proc. O-COCOSDA2012, Macau, 129-134.
[9] Phung, T. N., Luong, M. C., and Akagi, M. (2012/12/06). “A concatenative
speech synthesis for monosyllabic languages with limited data,” Proc. APSIPA2012,
Hollywood, USA.
[10] Phung, T. N., Luong, M. C., and Akagi, M. (2012/08). “On the stability of spectral targets under effects of coarticulation,” International Journal of Computer and Electrical Engineering, Vol. 4, No. 4, 537-541.
[11] Phung, T. N., Luong, M. C., and Akagi, M. (2012/08). “An investigation
on speech perception under effects of coarticulation,” International Journal
of Computer and Electrical Engineering, Vol. 4, No. 4, 532-536.
[12] Trung-Nghia Phung, Mai Chi Luong, and Masato Akagi (2011/02). “An
investigation on perceptual line spectral frequency (PLP-LSF) target stability
against the vowel neutralization phenomenon,” Proc. ICSAP2011, VI, 512-514.
[13] Trung-Nghia Phung, Mai Chi Luong, and Masato Akagi (2011/02). “An investigation on speech perception over coarticulation,” Proc. ICSAP2011, VI, 507-511.
[14] Nguyen B. P. and Akagi M. (2009/9/9). “Efficient modeling of temporal
structure of speech for applications in voice transformation,” Proc. InterSpeech2009,
Brighton, 1631-1634.
[15] Nguyen, B. P. and Akagi, M. (2009/5/1) "A flexible spectral modification
method based on temporal decomposition and Gaussian mixture model,"
Acoust. Sci. & Tech., 30, 3, 170-179.
[16] Nguyen, B. P. and Akagi, M. (2009/02/20). "Applications of Temporal Decomposition to Voice Transformation," International symposium on biomechanical and physiological modeling and speech science, 19-24.
[17] Nguyen, B. P., Shibata, T., and Akagi, M. (2008/09/24). "High-quality
analysis/synthesis method based on Temporal decomposition for speech modification,"
Proc. InterSpeech2008, Brisbane, 662-665.
[18] Nguyen B. P. and Akagi M. (2008/6/6). "Phoneme-based spectral
voice conversion using temporal decomposition and Gaussian mixture model,"
Proc. ICCE2008, 224-229.
[19] Nguyen B. P. and Akagi M. (2008/3/7). "Control of spectral dynamics using temporal decomposition in voice conversion and concatenative speech synthesis," Proc. NCSP08, 279-282.
[20] Shibata, T. and Akagi, M. (2008/3/6). "A study on voice conversion
method for synthesizing stimuli to perform gender perception experiments
of speech," Proc. NCSP08, 180-183.
[21] Nguyen B. P. and Akagi M. (2007). "A flexible spectral modification
method based on temporal decomposition and Gaussian mixture model,"
Proc. Interspeech2007, 538-541.
[22] Nguyen B. P. and Akagi M. (2007). "Spectral Modification for Voice Gender Conversion using Temporal Decomposition," Journal of Signal Processing, 11, 4, 333-336.
[23] Akagi, M., Saitou, T., and Huang, C. F. (2007). "Voice conversion
to add non-linguistic information into speaking voices," Proc. JCA2007,
CD-ROM.
[24] Nguyen B. P. and Akagi M. (2007). "Spectral Modification for
Voice Gender Conversion using Temporal Decomposition," Proc. NCSP2007,
481-484.
[25] Takeyama, Y., Unoki, M., Akagi, M., and Kaminuma, A. (2006). "Synthesis
of mimic speech sounds uttered in noisy car environments," Proc. NCSP2006,
118-121.
1-5 Speech Analysis and Coding
[1] Kosugi, T., Haniu, A., Miyauchi, R., Unoki, M., and Akagi, M. (2011/03/01).
“Study on suitable-architecture of IIR all-pass filter for digital-audio
watermarking technique based on cochlear-delay characteristics,”Proc. NCSP2011,
Tianjin, China, 135-138.
[2] Tomoike, S. and Akagi, M. (2008). "Estimation of local peaks based
on particle filter in adverse environments," Journal of Signal Processing,
12, 4, 303-306.
[3] Tomoike, S. and Akagi, M. (2008/3/7). "Estimation of local peaks based on particle filter in adverse environments," Proc. NCSP08, 391-394.
[4] Nguyen, P. C., Akagi, M., and Nguyen, P. B. (2007). "Limited error
based event localizing temporal decomposition and its application to variable-rate
speech coding," Speech Communication, 49, 292-304.
[5] Akagi, M., Nguyen, P. C., Saitou, T., Tsuji, N., and Unoki, M. (2004).
“Temporal decomposition of speech and its application to speech coding
and modification,” Proc. KEST2004, 280-288.
[6] Akagi, M. and Nguyen, P. C. (2004). “Temporal decomposition of speech and its application to speech coding and modification,” Proc. Special Workshop in MAUI (SWIM), 1-4, 2004.
[7] Nguyen, P. C. and Akagi, M. (2003). “Efficient quantization of speech
excitation parameters using temporal decomposition,” Proc. EUROSPEECH2003,
Geneva, 449-452.
[8] Nguyen, P. C., Akagi, M., and Ho, T. B. (2003). "Temporal decomposition:
A promising approach to VQ-based speaker identification," Proc. ICME2003,
Baltimore, V.III, 617-620.
[9] Nguyen, P. C., Akagi, M., and Ho, T. B. (2003). "Temporal decomposition: A promising approach to VQ-based speaker identification," Proc. ICASSP2003, Hong Kong, I-184-187.
[10] Nguyen, P. C., Ochi, T., and Akagi, M. (2003). “Modified Restricted
Temporal Decomposition and its Application of Low Rate Speech Coding,”
IEICE Trans. Inf. & Syst., E86-D, 3, 397-405.
[11] Nguyen, P. C. and Akagi, M. (2002). "Variable rate speech coding
using STRAIGHT and temporal decomposition," Proc. SCW2002, Tsukuba,
26-28.
[12] Nguyen, P. C. and Akagi, M. (2002). "Coding speech at very low rates using STRAIGHT and temporal decomposition," Proc. ICSLP2002, Denver, 1849-1852.
[13] Nguyen, P. C. and Akagi, M. (2002). "Limited error based event
localizing temporal decomposition," Proc. EUSIPCO2002, Toulouse, 190.
[14] Nguyen, P. C. and Akagi, M. (2002). "Improvement of the restricted
temporal decomposition method for line spectral frequency parameters,"
Proc. ICASSP2002, Orlando, I-265-268.
[15] Nandasena, A. C. R., Nguyen, P. C. and Akagi, M. (2001). " Spectral stability based event localizing temporal decomposition", Computer Speech & Language, Vol. 15, No. 4, 381-401
[16] Nandasena, A.C.R. and Akagi, M. (1998). “Spectral stability based event localizing temporal decomposition,” Proc. ICASSP98, II, 957-960
1-6 Announce System
[1] Ngo, T. V., Kubo, R., Morikawa, D., and Akagi, M. (2017/03/02). “Acoustical
analyses of Lombard speech by different background noise levels for tendencies
of intelligibility,” Proc. NCSP2017, Guam, USA, 309-312.
[2] Kubo, R, Morikawa, D., and Akagi, M. (2016/08/22). “Effects of speaker’s
and listener’s acoustic environments on speech intelligibility and annoyance”,
Proc. Inter-Noise2016, Hamburg, Germany, 171-176.
2. Speech recovery
2-1 Noise Reduction
[1] Junfeng Li, Risheng Xia, Dongwen Ying, Yonghong Yan, and Masato Akagi
(2014/12/05). “Investigation of objective measures for intelligibility
prediction of noise-reduced speech for Chinese, Japanese, and English,”
J. Acoust. Soc. Am. 136 (6), 3301-3312.
[2] Li, J, Chen, F., Akagi, M., and Yan, Y. (2013/08/27), “Comparative
investigation of objective speech intelligibility prediction measures for
noise-reduced signals in Mandarin and Japanese,” Proc. InterSpeech2013,
Lyon, 1184-1187.
[3] Li, J., Akagi, M., and Yan, Y. (2013/07/09). “Objective Japanese intelligibility prediction for noisy speech signals before and after noise-reduction processing,” Proc. ChinaSIP2013, Beijing, 352-355.
[4] Xia, R., Li, J., Akagi, M., and Yan, Y. (2012/03/28). “Evaluation of
objective intelligibility prediction measures for noise-reduced signals
in Mandarin,” Proc. ICASSP2012, Kyoto, 4465-4468.
[5] Li, J., Sakamoto, S., Hongo, S., Akagi, M., and Suzuki, Y. (2011/06).
“Two-stage binaural speech enhancement with Wiener filter for high-quality
speech communication,” Speech Communication 53 677-689.
[6] Li, J., Yang, L., Zhang, J., Yan, Y., Hu, Y., Akagi, M., and Loizou, P. C. (2011/05). “Comparative intelligibility investigation of single-channel noise-reduction algorithms for Chinese, Japanese, and English,” J. Acoust. Soc. Am., 129, 3291-3301.
[7] Li, J., Chau, D. T., Akagi, M., Yang, L., Zhang, J., and Yan, Y. (2010/11/30).
“Intelligibility Investigation of Single-Channel Noise Reduction Algorithms
for Chinese and Japanese,” in: Proc. ISCSLP2010, Tainan, Taiwan.
[8] Li, J., Sakamoto, S., Hongo, S., Akagi, M., and Suzuki, Y. (2009/10/20).
"Two-stage binaural speech enhancement with Wiener filter based on
equalization-cancellation model," Proc. WASPAA, New Palts, NY, 133-136.
[9] Li, J., Sakamoto, S., Hongo, S., Akagi, M., and Suzuki, Y. (2009/9/21). "Advancement of two-stage binaural speech enhancement (TS-BASE) for high-quality speech communication," Proc. WESPAC2009, Beijing, CD-ROM.
[10] Yang, L., Li, J., Zhang, J., Yan, Y., and Akagi, M. (2009/6/26). "Effects
of single-channel enhancement algorithms on Mandarin speech intelligibility,"
IEICE Tech. Report, EA2009-32.
[11] Li, J., Fu, Q-J., Jiang, H., and Akagi, M. (2009/04/24). "Psychoacoustically-motivated
adaptive β-order generalized spectral subtraction for cochlear implant
patients," Proc ICASSP2009, 4665-4668.
[12] Li, J., Jiang, H., and Akagi, M. (2008/09/23). "Psychoacoustically-motivated adaptive β-order generalized spectral subtraction based on data-driven optimization," Proc. InterSpeech2008, Brisbane, 171-174.
[13] Li, J., Sakamoto, S., Hongo, S., Akagi, M., and Suzuki, Y. (2008).
“Adaptive -order generalized spectral subtraction for speech enhancement,”
Signal Processing, vol. 88, no. 11, pp. 2764-2776, 2008.
[14] Li, J., Sakamoto, S., Hongo, S., Akagi, M., and Suzuki, Y. (2008/08/16).
"Improved two-stage binaural speech enhancement based on accurate
interference estimation for hearing aids," IHCON2008
[15] Li, J., Sakamoto, S., Hongo, S., Akagi, M., and Suzuki, Y. (2008/0630). "A two-stage binaural speech enhancement approach for hearing aids with preserving binaural benefits in noisy environments," Acoustics2008, Paris, 723-727.
[16] Li, J., Akagi, M., and Suzuki, Y. (2008). "A two-microphone noise
reduction method in highly non-stationary multiple-noise-source environments,"
IEICE Trans. Fundamentals, E91-A, 6, 1337-1346.
[17] Li, J. and Akagi, M. (2008). "A hybrid microphone array post-filter
in a diffuse noise field," Applied Acoustics 69, 546-557.
[18] Li, J., Sakamoto, S., Hongo, S., Akagi, M., and Suzuki, Y. (2007). "A speech enhancement approach for binaural hearing aids," Proc. 22th SIP Symposium, Sendai, 263-268.
[19] Li, J., Sakamoto, S., Hongo, S., Akagi, M., and Suzuki, Y. (2007).
"Noise reduction based on adaptive beta-order generalized spectral
subtraction for speech enhancement," Proc. Interspeech2007, 802-805.
[20] Li, J., Akagi, M., and Suzuki, Y. (2006). "Multi-channel noise
reduction in noisy environments," Chinese Spoken Language Processing,
Proc. ISCSLP2006, Springer LNCS 4274, 258-269.
[21] Li, J., Akagi, M., and Suzuki, Y. (2006). "Noise reduction based on microphone array and post-filtering for robust speech recognition," Proc. ICSP, Guilin.
[22] Li, J. and Akagi, M. (2006). "Noise reduction method based on
generalized subtractive beamformer," Acoust. Sci. & Tech., 27,
4, 206-215.
[23] Li, J, Akagi, M., and Suzuki, Y. (2006). "Improved hybrid microphone
array post-filter by integrating a robust speech absence probability estimator
for speech enhancement," Proc. ICSLP2006, Pittsburgh, USA, 2130-2133.
[24] Li, J. and Akagi, M. (2006). "A noise reduction system based on hybrid noise estimation technique and post-filtering in arbitrary noise environments," Speech Communication, 48, 111-126.
[25] Li, J., Akagi, M., and Suzuki, Y. (2006). "Noise reduction based
on generalized subtractive beamformer for speech enhancement," WESPAC2006,
Seoul
[26] Li, J. and Akagi, M. (2005). "Theoretical analysis of microphone
arrays with postfiltering for coherent and incoherent noise suppression
in noisy environments," Proc. IWAENC2005, Eindhoven, The Netherlands,
85-88.
[27] Li, J. and Akagi, M. (2005). "A hybrid microphone array post-filter in a diffuse noise field," Proc. EuroSpeech2005, Lisbon, Portugal, 2313-2316.
[28] Li, J., Lu, X., and Akagi, M. (2005). "Noise reduction based
on microphone array and post-filtering for robust speech recognition in
car environments," Proc. Workshop DSPinCar2005, S2-9
[29] Li, J., Lu, X., and Akagi, M. (2005). “A noise reduction system in
arbitrary noise environments and its application to speech enhancement
and speech recognition,” Proc. ICASSP2005, Philadelphia, III-277-280.
[30] Li, J. and Akagi, M. (2005). “Suppressing localized and non-localized noises in arbitrary noise environments,” Proc. HSCMA2005, Piscataway.
[31] Li, J. and Akagi, M. (2004). “Noise reduction using hybrid noise estimation
technique and post-filtering,” Proc. ICSLP2004, Cheju, Korea.
[32] Akagi, M. and Kago, T. (2002). " Noise reduction using a small-scale
microphone array in multi noise source environment," Proc. ICASSP2002,
Orlando, I-909-912.
[33] Mizumachi, M., Akagi, M. and Nakamura, S. (2000). "Design of robust subtractive beamformer for noisy speech recognition," Proc. ICSLP2000, Beijing, IV-57-60.
[34] Mizumachi, M. and Akagi, M. (2000). "Noise reduction using a
small-scale microphone array under non-stationary signal conditions,"
Proc. WESTPRAC7, 421-424.
[35] Mizumachi, M. and Akagi, M. (1999). "Noise reduction method that
is equipped for robust direction finder in adverse environments,"
Proc. Workshop on Robust Methods for Speech Recognition in Adverse Conditions,
Tampere, Finland, 179-182.
[36] Mizumachi, M. and Akagi, M. (1998). “Noise reduction by paired-microphones using spectral subtraction,” Proc. ICASSP98, II, 1001-1004
[37] Akagi, M. and Mizumachi, M. (1997). "Noise Reduction by Paired Microphones", Proc. EUROSPEECH97, 335-338.
2-2 F0 Extraction
[1] Ishimoto, Y., Akagi, M., Ishizuka, K., and Aikawa, K. (2004). “Fundamental
frequency estimation for noisy speech using entropy-weighted periodic and
harmonic features,” IEICE Trans. Inf. & Syst., E87-D, 1, 205-214.
[2] Ishimoto, Y., Unoki, M., and Akagi, M. (2001). "A fundamental
frequency estimation method for noisy speech based on instantaneous amplitude
and frequency", Proc. EUROSPEECH2001, Aalborg, 2439-2442.
[3] Ishimoto, Y., Unoki, M., and Akagi, M. (2001). "A fundamental frequency estimation method for noisy speech based on instantaneous amplitude and frequency ", Proc. CRAC, Aalborg.
[4] Ishimoto, Y., Unoki, M., and Akagi, M. (2001). "A fundamental
frequency estimation method for noisy speech based on periodicity and harmonicity",
Proc. ICASSP2001, SPEECH-SF3, Salt Lake City.
[5] Ishimoto, Y. and Akagi, M. (2000). "A fundamental frequency estimation
method for noisy speech," Proc. WESTPRAC7, 161-164.
2-3 De-reverberation
[1] Morita, S., Unoki, M., Lu, X., and Akagi, M. (2015/06/11). “Robust
Voice Activity Detection Based on Concept of Modulation Transfer Function
in Noisy Reverberant Environments,” Journal of Signal Processing Systems,
DOI 10.1007/s11265-015-1014-4
[2] Morita, S., Unoki, M., Lu, X., and Akagi, M. (2014/09/13). “Robust
Voice Activity Detection Based on Concept of Modulation Transfer Function
in Noisy Reverberant Environments,” Proc. ISCSLP2014, Singapore, 108-112.
[3] Unoki, M., Ikeda, T., Sasaki, K., Miyauchi, R., Akagi, M., and Kim, N-S. (2013/07/08). “Blind method of estimating speech transmission index in room acoustics based on concept of modulation transfer function,” Proc. ChinaSIP2013, Beijing, 308-312.
[4] Sasaki, Y. and Akagi, M. (2012/03/05), “Speech enhancement technique
in noisy reverberant environment using two microphone arrays,” Proc. NCSP2012,
Honolulu, HW, 333-336.
[5] Unoki, M., Lu, X., Petrick, R., Morita, S., Akagi, M., and Hoffmann
R. (2011/08/30). “Voice activity detection in MTF-based power envelope
restoration,” Proc. INTERSPEECH 2011, Florence, Italy, 2609-2612.
[6] Unoki, M., Ikeda, T., and Akagi, M. (2011/06/27). “Blind estimation method of speech transmission index in room acoustics,” Proc. Forum Acousticum 2011, Aalborg, Denmark, 1973-1978.
[7] Morita, S., Lu, X., Unoki, M., and Akagi, M. (2011/03/02). “Study
on MTF-based power envelope restoration in noisy reverberant environments,”
Proc. NCSP2011, Tianjin, China, 247-250.
[8] Ikeda, T., Unoki, M., and Akagi, M. (2011/03/02). “Study on blind estimation
of Speech Transmission Index in room acoustics,”Proc. NCSP2011, Tianjin,
China, 235-238.
[9] Morita, S., Unoki, M., and Akagi, M. (2010/07/01). “A study on the IMTF-based filtering on the modulation spectrum of reverberant signal,” Journal of Signal Processing, 14, 4, 269-272.
[10] Li, J. Sasaki, Y., Akagi, M. and Yan, Y. (2010/03/04). "Experimental
evaluations of TS-BASE/WF in reverberant conditions," Proc. NCSP10,
Hawaii, USA, 269-272.
[11] Morita, S., Unoki, M., and Akagi, M. (2010/03/04). "A study on
the MTF-based inverse filtering for the modulation spectrum of reverberant
speech," Proc. NCSP10, Hawaii, USA, 265-268.
[12] Unoki, M., Yamasaki, Y., and Akagi, M. (2009/08/25). “MTF-based power envelope restoration in noisy reverberant environments,” Proc. EUSIPCO2009, Glasgow, Scotland, 228-232.
[13] Petric, R., Lu, X., Unoki, M., Akagi, M., and Hoffmann, R. (2008/09/24).
"Robust front end processing for speech recognition in reverberant
environments: Utilization of speech characteristics," Proc. InterSpeech2008,
Brisbane, 658-661.
[14] Uniki, M., Toi, M., Shibano, Y., and Akagi, M. (2006). "Suppression
of speech intelligibility loss through a modulation transfer function-based
speech dereverberation method," J. Acoust. Soc. Am., 120, 5, Pt. 2,
3360.
[15] Unoki, M., Toi, M., and Akagi, M. (2006). "Refinement of an MTF-based speech dereverberation method using an optimal inverse-MTF filter," SPECOM2006, St. Petersburg, 323-326.
[16] Unoki, M., Toi, M., and Akagi, M. (2005). “Development of the MTF-based
speech dereverberation method using adaptive time-frequency division,”
Proc. Forum Acousticum 2005, 51-56.
[17] Toi, M., Unoki, M. and Akagi, M. (2005). “Development of adaptive
time-frequency divisions and a carrier reconstruction in the MTF-based
speech dereverberation method,” Proc. NCSP05, Hawaii, 355-358.
[18] Unoki, M., M., Sakata, Furukawa, K. and Akagi, M. (2004). “A speech dereverberation method based on the MTF concept in power envelope restoration,” Acoust. Sci. & Tech., 25, 4, 243-254.
[19] Unoki, M., Furukawa, M., Sakata, K. and Akagi, M. (2004). “An improved
method based on the MTF concept for restoring the power envelope from a
reverberant signal,” Acoust. Sci. & Tech., 25, 4, 232-242.
[20] Unoki, M., Toi, M., and Akagi, M. (2004). “A speech dereverberation
method based on the MTF concept using adaptive time-frequency divisions,”
Proc. EUSIPCO2004, 1689-1692.
[21] Unoki, M., Sakata, K., Toi, M., and Akagi, M. (2004). “Speech dereverberation based on the concept of the modulation transfer function,” Proc. NCSP2004, Hawaii, 423-426.
[22] Unoki, M., Sakata, K. and Akagi, M. (2003). “A speech dereverberation
method based on the MTF concept,” Proc. EUROSPEECH2003, Geneva, 1417-1420.
[23] Unoki, M., Furukawa, M., Sakata, K., and Akagi, M. (2003). "A
method based on the MTF concept for dereverberating the power envelope
from the reverberant signal," Proc. ICASSP2003, Hong Kong, I-840-843.
[24] Unoki, M., Furukawa, M., and Akagi, M. (2002). "A method for
recovering the power envelope from reverberant speech," SPA-Gen-002,
Forum Acousticum Sevilla 2002.
2-4 Bone-conducted Speech
[1] Phung, T. N., Unoki, M., and Akagi, M. (2012/09/01). “A study on restoration
of bone-conducted speech in noisy environments with LP-based model and
Gaussian mixture model,” Journal of Signal Processing, 16, 5, 409-417.
[2] Phung, T. N., Unoki, M. and Akagi, M. (2010/12/14). “Improving Bone-Conducted
Speech Restoration in noisy environment based on LP scheme,” Proc. APSIPA2010,
Student Symposium, 12.
[3] Kinugasa, K., Unoki, M., and Akagi, M. (2009/07/01). "An MTF-based method for Blind Restoration for Improving Intelligibility of Bone-conducted Speech," Journal of Signal Processing, 13, 4, 339-342.
[4] Kinugasa, K., Unoki, M., and Akagi, M. (2009/6/24). "An MTF-based
method for blindly restoring bone-conducted speech," Proc. SPECOM2009,
St. Petersburg, Russia, 199-204.
[5] Kinugasa, K., Unoki, M., and Akagi, M. (2009/03/01). "An MTF-based
Blind Restoration Method for Improving Intelligibility of Bone-conducted
Speech," Proc. NCSP'09, 105-108.
[6] Vu, T. T. Unoki, M. and Akagi, M. (2008/6/5). "An LP-based blind model for restoring bone-conducted speech," Proc. ICCE2008, 212-217.
[7] Vu, T. T., Unoki, M., and Akagi, M. (2008/3/7). "A study of blind
model for restoring bone-conducted speech based on liner prediction scheme,"
Proc. NCSP08, 287-290.
[8] Vu, T. T. Unoki, M. and Akagi, M. (2007). “The Construction of Large-scale
Bone-conducted and Air-conducted Speech Databases for Speech Intelligibility
Tests,” Proc. Oriental COCOSDA2007, 88-91.
[9] Vu, T. T., Unoki, M., and Akagi, M. (2007). "A blind restoration model for bone-conducted speech based on a linear prediction scheme," Proc. NOLTA2007, Vancouver, 449-452.
[10] Vu, T. T., Seide, G., Unoki, M., and Akagi, M. (2007). "Method
of LP-based blind restoration for improving intelligibility of bone-conducted
speech," Proc. Interspeech2007, 966-969.
[11] Vu, T., Unoki, M., and Akagi, M. (2006). "A Study on Restoration
of Bone-Conducted Speech with MTF-Based and LP-based Models," Journal
of Signal Processing, 10, 6, 407-417.
[12] Vu, T., Unoki, M., and Akagi, M. (2006). "A study on an LP-based model for restoring bone-conducted speech," Proc. HUT-ICCE2006, Hanoi.
[13] Vu, T. T., Unoki, M., and Akagi, M. (2006). "A study on an LPC-based
restoration model for improving the voice-quality of bone-conducted speech,"
Proc. NCSP2006, 110-113.
[14] Kimura, K., Unoki, M. and Akagi, M. (2005). “A study on a bone-conducted
speech restoration method with the modulation filterbank,” Proc. NCSP05,
Hawaii, 411-414.
2-5 Speech Recognition
[1] Du, Y. and Akagi, M. (2014/03/02). “Speech recognition in noisy conditions
based on speech separation using Non-negative Matrix Factorization,” Proc.
NCSP2014, Hawaii, USA, 429-432.
[2] Haniu, A., Unoki, M., and Akagi, M. (2009/9/21). "A psychoacoustically-motivated
conceptual model for automatic speech recognition," Proc. WESPAC2009,
Beijing, CD-ROM.
[3] Lu, X., Unoki, M., and Akagi, M. (2008/11/1). "Comparative evaluation of modulation-transfer-function-based blind restoration of sub-band power envelopes of speech as a front-end processor for automatic speech recognition systems," Acoustical Science and Technology, 29, 6, 351-361.
[4] Lu, X., Unoki, M., and Akagi, M. (2008/07/01). "An MTF-based blind
restoration for temporal power envelopes as a front-end processor for automatic
speech recognition systems in reverberant environments," Acoustics2008,
Paris, 1419-1424.
[5] Haniu, A., Unoki, M., and Akagi, M. (2008/3/6). "A speech recognition
method based on the selective sound segregation in various noisy environments,"
Proc. NCSP08, 168-171.
[6] Haniu, A., Unoki, M. and Akagi, M. (2007). " A study on a speech recognition method based on the selective sound segregation in various noisy environments," Proc. NOLTA2007, Vancouver, 445-448.
[7] Haniu, A., Unoki, M. and Akagi, M. (2007). "A study on a speech
recognition method based on the selective sound segregation in noisy environment,"
Proc. JCA2007, CD-ROM.
[8] Lu, X., Unoki, M., and Akagi, M. (2006). "A robust feature extraction
based on the MTF concept for speech recognition in reverberant environment,"
Proc. ICSLP2006, Pittsburgh, USA, 2546-2549.
[9] Lu, X., Unoki, M., and Akagi, M. (2006). "MTF-based sub-band power envelope restoration in reverberant environment for robust speech recognition, " Proc. NCSP2006, 162-165.
[10] Haniu, A., Unoki, M. and Akagi, M. (2005). “A study on a speech recognition method based on the selective sound segregation in noisy environment,” Proc. NCSP05, Hawaii, 403-406.
2-6 DOA
[1] Chau, D. T., Li, J., and Akagi, M. (2014/10/01). “Binaural sound source
localization in noisy reverberant environments based on Equalization-Cancellation
Theory,” IEICE Trans. Fund., E97-A, 10, 2011-2020.
[2] Chau, D. T., Li, J., and Akagi, M. (2013/07/08). “Improve equalization-cancellation-based
sound localization in noisy reverberant environments using direct-to-reverberant
energy ratio,” Proc. ChinaSIP2013, Beijing, 322-326.
[3] Chau, D. T., Li, J., and Akagi, M. (2011/07/01). “Towards intelligent binaural speech enhancement by meaningful sound extraction,” Journal of Signal Processing, 15, 4, 291-294.
[4] Chau, D. T., Li, J., and Akagi, M. (2011/03/03). “Towards an intelligent
binaural speech enhancement system by integrating meaningful signal extraction,”Proc.
NCSP2011, Tianjin, China, 344-347.
[5] Chau, D. T., Li, J., and Akagi, M. (2010/09/30). "A DOA estimation
algorithm based on equalization-cancellation theory," Proc. INTERSPEECH2010,
Makuhari, 2770-2773.
3. Cocktail-party Effect Modeling
3-1 Sound Segregation
[1] Unoki, M., Kubo, M., Haniu, A., and Akagi, M. (2006). "A Model-Concept
of the Selective Sound Segregation: — A Prototype Model for Selective Segregation
of Target Instrument Sound from the Mixed Sound of Various Instruments
—," Journal of Signal Processing, 10, 6, 419-431.
[2] Unoki, M., Kubo, M., Haniu, A., and Akagi, M. (2005). "A model
for selective segregation of a target instrument sound from the mixed sound
of various instruments," Proc. EuroSpeech2005, Lisbon, Portugal, 2097-2100.
[3] Unoki, M., Kubo, M., and Akagi, M. (2003). “A model for selective segregation of a target instrument sound from the mixed sound of various instruments,” Proc. ICMC2003, Singapore, 295-298.
[4] Akagi, M., Mizumachi, M., Ishimoto, Y., and Unoki, M. (2002). "Speech
enhancement and segregation based on human auditory mechanisms", in
Enabling Society with Information Technology, Q. Jin, J. Li, N. Zhang,
J. Cheng, C. Yu, and S. Noguchi (Eds.), Springer Tokyo, 186-196
[5] Akagi, M., Mizumachi, M.,Ishimoto, Y., and Unoki, M. (2000). "Speech
enhancement and segregation based on human auditory mechanisms", Proc.
IS2000, Aizu, 246-253.
[6] Unoki, M. and Akagi, M. (1999). "Segregation of vowel in background noise using the model of segregating two acoustic sources based on auditory scene analysis", Proc. EUROSPEECH99, 2575-2578.
[7] Unoki, M. and Akagi, M. (1999). "Segregation of vowel in background
noise using the model of segregating two acoustic sources based on auditory
scene analysis", Proc. CASA99, IJCAI-99, Stockholm, 51-60.
[8] Akagi, M., Iwaki, M. and Sakaguchi, N. (1998). “Spectral sequence compensation
based on continuity of spectral sequence,” Proc. ICSLP98, Sydney, Vol.4,
1407-1410.
[9] Unoki, M. and Akagi, M. (1998). “Signal extraction from noisy signal based on auditory scene analysis,” ICSLP98, Sydney, Vol.5, 2115-2118.
[10] Unoki, M. and Akagi, M. (1998). “A method of signal extraction from
noisy signal based on auditory scene analysis,” Speech Communication, 27,
3-4, 261-279.
[11] Unoki, M. and Akagi, M. (1998). “A method of signal extraction from
noisy signal based on auditory scene analysis,” JAIST Tech. Report, IS-RR-98-0005P.
[12] Unoki, M. and Akagi, M. (1997). "A method of signal extraction from noisy signal", Proc. EUROSPEECH97, 2587-2590.
[13] Unoki, M. and Akagi, M. (1997). "A method of signal extraction
from noisy signal based on auditory scene analysis", Proc. CASA97,
IJCAI-97, Nagoya, 93-102.
[14] Unoki, M. and Akagi, M. (1997). “A method for signal extraction from
noise-added signals”, Electronics and Communications in Japan, Part 3,
80, 11, 1-11.
3-2 Privacy Protection
[1] Akagi, M. and Irie, Y. (2012/08/22). “Privacy protection for speech based on concepts of auditory scene analysis,” Proc. INTERNOISE2012, New York, 485.
[2] Tezuka, T. and Akagi, M. (2008/3/6). "Influence of spectrum envelope
on phoneme perception," Proc. NCSP08, 176-179.
[3] Minowa A., Unoki M., and Akagi M. (2007). "A study on physical
conditions for auditory segregation/integration of speech signals based
on auditory scene analysis," Proc. NCSP2007, 313-316.
3-3 Noisy Sound Perception
[1] Yano, Y., Miyauchi, R., Unoki, M., and Akagi, M. (2012/03/06). “Study
on detectability of signals by utilizing differences in their amplitude
modulation,” Proc. NCSP2012, Honolulu, HW, 611-614.
[2] Kuroda, N., Li, J., Iwaya, Y., Unoki, M., and Akagi, M. (2011). “Effects
of spatial cues on detectability of alarm signals in noisy environments,”
In Principles and applications of spatial hearing (Eds. Suzuki, Y., Brungart,
D., Iwaya, Y., Iida, K., Cabrera, D., and Kato, H.), World Scientific,
484-493.
[3] Yano, Y., Miyauchi, R., Unoki, M., and Akagi, M. (2011/03/02). “Study on detectability of target signal by utilizing differences between movements in temporal envelopes of target and background signals,” Proc. NCSP2011, Tianjin, China, 231-234.
[4] Mizukawa, S. and Akagi, M. (2011/03/02). “A binaural model accounting
for spatial masking release,” Proc. NCSP2011, Tianjin, China, 179-182.
[5] Naoki Kuroda, Junfeng Li, Yukio Iwaya, Masashi Unoki, and Masato Akagi,
“Effects of spatial cues on detectability of alarm signals in noisy environments,”
Proc. IWPASH2009, P7. Zaou, Japan, Nov. 2009 (CDROM).
[6] Kuroda, N., Li, J., Iwaya, Y., Unoki, M., and Akagi, M. (2009/03/01). "Effects from Spatial Cues on Detectability of Alarm Signals in Car Environments," Proc. NCSP'09, 45-48.
[7] Kusaba, M., Unoki, M., and Akagi, M. (2008/3/6). "A study on detectability
of target signal in background noise by utilizing similarity of temporal
envelopes in auditory search," Proc. NCSP08, 13-16.
[8] Uchiyama, H., Unoku, M., and Akagi, M. (2007). "Improvement in
detectability of alarm signals in noisy environments by utilizing spatial
cues," Proc. WASPAA2007, New Paltz, NY, pp.74-77.
[9] Uchiyama H., Unoki M., and Akagi M. (2007). "A study on perception of alarm signal in car environments," Proc. NCSP2007, 389-392.
[10] Nakanishi, J., Unoki, M., and Akagi, M. (2006). "Effect of ITD
and component frequencies on perception of alarm signals in noisy environments,"
Journal of Signal Processing, 10, 4, 231-234.
[11] Nakanishi, J., Unoki, M., and Akagi, M. (2006). "Effect of ITD
and component frequencies on perception of alarm signals in noisy environments,"
Proc. NCSP2006, 37-40.
4. Psychoacoustics
4-1 Auditory Model
[1] Unoki, M. and Akagi, M. (2001). "A computational model of co-modulation
masking release," in Computational Models of Auditory Function, (Eds.
Greenberg, S. and Slaney, M.), NATO ASI Series, IOS Press, Amsterdam, 221-232.
[2] Unoki, M. and Akagi, M. (1998). “A computational model of co-modulation
masking release,” Computational Hearing, Italy, 129-134.
[3] Unoki, M. and Akagi, M. (1998). “A computational model of co-modulation
masking release,” JAIST Tech. Report, IS-RR-98-0006P.
4-2 Contextual Effect
[1] Yonezawa, Y. and Akagi, M. (1996). "Modeling of contextual effects
and its application to word spotting", Proc. Int. Conf. Spoken Lang.
Process. 96, 2063-2066.
[2] Akagi, M., van Wieringen, A. and Pols, L. C. W. (1994). "Perception
of central vowel with pre- and post-anchors", Proc. Int. Conf. Spoken
Lang. Process. 94, 503-506.
4-3 Auditory Filter
4-4 Phase Perception
[1] Akagi, M., and Nishizawa, M. (2001). "Detectability of phase change and its computational modeling," J. Acoust. Soc. Am., 110, 5, Pt. 2, 2680.
4-5 Speech Perception
[1] Kubo, R., Akagi, M., and Akahane-Yamada, R. (2015/9/1). “Dependence on age of interference with phoneme perception by first- and second-language speech maskers,” Acoustical Science and Technology, 36, 5, 397-407.
[2] Kubo, R., Akagi, M., and Akahane-Yamada, R. (2014/05/09). “Perception
of second language phoneme masked by first- or second-language speech in
20 – 60 years old listeners,” 167th ASA, Providence, RI
[3] Kubo, R. and Akagi, M. (2013/06/04). “Exploring auditory aging can
exclusively explain Japanese adults′ age-related decrease in training effects
of American English /r/-/l/,” Proc. ICA2013, 2aSC34, Montreal.
4-6 Noise Evaluation
[1] Akagi, M., Kakehi, M., Kawaguchi, M., Nishinuma, M., and Ishigami,
A. (2001). "Noisiness estimation of machine working noise using human
auditory model", Proc. Internoise2001, 2451-2454.
[2] Mizumachi, M. and Akagi, M. (2000). "The auditory-oriented spectral
distortion for evaluating speech signals distorted by additive noises,"
J. Acoust. Soc. Jpn. (E), 21, 5 251-258.
[3] Mizumachi, M. and Akagi, M. (1999). "An objective distortion estimator
for hearing aids and its application to noise reduction," Proc. EUROSPEECH99,
2619-2622.
4-7 Pitch Perception
[1] Ishida, M. and Akagi, M. (2010/03/04). "Pitch perception of complex sounds with varied fundamental frequency and spectral tilt," Proc. NCSP10, Hawaii, USA, 480-483.
4-8 Direction Perception
[1] Akagi, M. and Hisatsune, H. (2013/10/17). “Admissible range for individualization
of head-related transfer function in median plane,” Proc. IIHMSP2013, Beijing.
[2] Hisatsune, H. and Akagi, M. (2013/03/6). “A Study on individualization
of Head-Related Transfer Function in the median plane,” Proc. NCSP2013,
Hawaii, USA, 161-164.
5. Physiological Auditory Modeling
[1] Ito, K. and Akagi, M. (2005). "Study on improving regularity of
neural phase locking in single neurons of AVCN via a computational model,"
In Auditory Signal Processing, Springer, 91-99.
[2] Maki, K. and Akagi, M. (2005). "A computational model of cochlear nucleus neurons," In Auditory Signal Processing, Springer, 84-90.
[3] Ito, K. and Akagi, M. (2003). “Study on improving regularity of neural
phase locking in single neuron of AVCN via computational model,” Proc.
ISH2003, 77-83.
[4] Maki, K. and Akagi, M. (2003). “A computational model of cochlear nucleus
neurons,” Proc. ISH2003, 70-76.
[5] Itoh, K. and Akagi, M. (2001). “A computational model of auditory sound localization,” in Computational Models of Auditory Function (Eds. Greenberg, S. and Slaney, M.), NATO ASI Series, IOS Press, Amsterdam, 97-111.
[6] Ito, K. and Akagi, M. (2000). "A computational model of binaural
coincidence detection using impulses based on synchronization index."
Proc, ISA2000 (BIS2000), Wollongong, Australia.
[7] Maki, K., Akagi, M. and Hirota, K. (2000). "Effect of the basilar
membrane nonlinearities on rate-place representation of vowel in the cochlear
nucleus: A modeling approach," In Recent Developments in Auditory
Mechanics, World Scientific Publishing, 490-496.
[8] Ito, K. and Akagi, M. (2000). "A computational model of auditory sound localization based on ITD," In Recent Developments in Auditory Mechanics, World Scientific Publishing, 483-489.
[9] Ito, K. and Akagi, M. (2000). "A study on temporal information
based on the synchronization index using a computational model," Proc.
WESTPRAC7, 263-266.
[10] Maki, K., Akagi, M. and Hirota, K. (1999). "Effect of the basilar
membrane nonlinearities on rate-place representation of vowel in the cochlear
nucleus: A modeling approach," Abstracts of Symposium on Recent Developments
in Auditory Mechanics, Sendai, Japan, 29P06, 166-167.
[11] Ito, K. and Akagi, M. (1999). "A computational model of auditory sound localization based on ITD," Abstracts of Symposium on Recent Developments in Auditory Mechanics, Sendai, Japan, 29P01, 156-157.
[12] Maki, K., Hirota, K. and Akagi, M. (1998). “A functional model of
the auditory peripheral system: Responses to simple and complex stimuli,”
Computational Hearing, Italy, 13-18.
[13] Itoh, K. and Akagi, M. (1998). “A computational model of auditory
sound localization,” Computational Hearing, Italy, 67-72
[14] Maki, K. and Akagi, M. (1997). "A functional model of the auditory
peripheral system", Proc. ASVA97, Tokyo, 703-710.
6. Abnormal Speech
6-1 Abnormal Speech Perception
[1] Kozaki-Yamaguchi, Y., Suzuki, N., Fujita, Y., Yoshimasu, H., Akagi, M., and Amagasa, T. (2005). "Perception of hypernasality and its physical correlates," Oral Science International, 2, 1, 21-35.
[2] Kozaki, Y., Suzuki, N., Amagasa, T., and Akagi, M. (2004). “Perception
of hypernasality and its physical correlates,” Proc. ICA2004. 3313-3316.
[3] Akagi, M., Suzuki, N., Hayashi, K., Saito, H., and Michi, K. (2001).
" Perception of Lateral Misarticulation and Its Physical Correlates",
Folia Phoniatrica et Logopaedica, 53, 6, 291-307
[4] Akagi, M., Kitamura, T., Suzuki, N. and Michi, K. (1996). "Perception
of lateral misarticulation and its physical correlates", Proc ASA-ASJ
Joint Meeting, 933-936.
6-2 3D Vocal Tract Modeling
[1] Nishimoto, H. and Akagi, M. (2006). "Effects of complicated vocal
tract shapes on vocal tract transfer functions," Journal of Signal
Processing, 10, 4, 267-270.
[2] Nishimoto, H. and Akagi, M. (2006). "Effects of complicated vocal
tract shapes on vocal tract transfer functions," Proc. NCSP2006, 114-117.
[3] Nishimoto, H., Akagi, M., Kitamura, T. and Suzuki, N. (2004). “Estimation of transfer function of vocal tract extracted from MRI data by FEM,” Proc. ICA2004, 1473-1476.
[4] Nishimoto, H., Akagi, M., Kitamura, T., Suzuki, N., and Saito, H. (2001).
"FEM analysisof three-dimensional vocal tract models after tongue
and mouth floor resection," J. Acoust. Soc. Am., 110, 5, Pt. 2, 2761.
[5] Nishimoto, H., Akagi, M., Kitamura, T., and Suzuki, N. (2002). "FEM
analyses of three dimensional vocal tract models after tongue and mouth
floor resection," NATO Advanced Study Institute 2002 Dynamics of Speech
Production and Perception.
7. Interaction between Perception and Production
[1] Shih, T, Suemitsu, A., and Akagi, M. (2011/03/03). “Influences of transformed
auditory feedback with first three formant frequencies,” Proc. NCSP2011,
Tianjin, China, 340-343.
[2] Shih, T., Suemitsu, A., and Akagi, M. (2010/10/16). "Influences
of real-time auditory feedback on formant perturbations," Proc. Auditory
Research Meeting, ASJ, 40, 8, H-2010-121.
[3] Akagi, M., Dang, J., Lu, X., and Uchiyamada, T. (2006). "Investigation of interaction between speech perception and production using auditory feedback," J. Acoust. Soc. Am., 120, 5, Pt. 2, 3253.
[4] Dang, J., Akagi, M., and Honda, K. (2006). "Communication between
speech production and perception within the brain - Observation and simulation,"
J. Comp. Sci. & Tech., 21, 1, 95-105.
[5] Matsuoka, R., Lu, X., Dang, J., and Akagi, M. (2004). “Investigation
of interaction between speech perception and speech production,” Proc.
KIT Int. Sympo. Brain and Language 2004, 27-28.
8. Signal Analysis
[1] Kobayashi, K., Morikawa, D., and Akagi, M. (2014/03/01). “Study on
Analyzing Individuality of Instrurment Sounds Using Non-negative Matrix
Factorization,” Proc. NCSP2014, Hawaii, USA, 37-40.
[2] Nishie, S. and Akagi, M. (2013/09/11). “Acoustic sound source tracking
for a moving object using precise Doppler-shift measurement,” Proc. EUSIPCO2013,
Marrakesh, Morocco.
9. Others
9-1 NTT & ATR
[1] Akagi, M. (1993). "Modeling of contextual effects based on spectral
peak interaction", J. of Acoust. Society of America, 93, 2, 1076-1086.
[2] Akagi, M. (1992). "Psychoacoustic evidence for contextual effect models", Speech Perception, Production and Linguistic Structure, IOS Press, Amsterdam, 63-78
[3] Akagi, M. (1990). "Contextual effect models and psychoacoustic
evidence for the models", Proc. Int. Conf. Spoken Lang. Process. 90,
569-572.
[4] Akagi, M. and Tohkura, Y. (1990). "Spectrum target prediction
model and its application to speech recognition", Computer Speech
and Language, 4, Academic Press 325-344.
[5] Akagi, M. (1990). "Psychoacoustic evidence for a contextual effect model", J. Acoust. Soc. Am., Spl 1, 87, MMM2 (119th Meeting of ASA).
[6] Akagi, M. (1990). "Evaluation of a spectrum target prediction
model in speech perception", J. of Acoust. Society of America, 87,
2, 858-865.
[7] Ueda, K. and Akagi, M. (1990). "Sharpness and amplitude envelopes
of broadband noise", J. of Acoust. Society of America, 87, 2, 814-819.
[8] Akagi, M. (1989). "Modeling of contextual effect based on spectral peak interaction", J. Acoust. Soc. Am., Spl 1, 85, II8 (117th Meeting of ASA).
[9] Akagi, M. and Tohkura, Y. (1988). "On the application of spectrum
target prediction model to speech recognition", Proc. Int. Conf. Acoustics
Speech and Signal Process., New York, 139-142.
[10] Akagi, M. (1987). "Evaluation of a spectrum target prediction
model in speech perception", J. Acoust. Soc. Am., Spl 1, 81, G8 (113th
Meeting of ASA).
[11] Furui, S. and Akagi, M. (1985). "On the role of spectral transition
in phoneme perception and its modeling", Proc. 12th Int. Conf. Acoustics,
A2-6.
9-2 Tokyo Institute of Technology
[1] Akagi, M., and Iijima, T. (1984). "A construction of pole-deviation
tracking filter," Electronics and Communications in Japan, 67-A, 5,
28-36.
[2] Akagi, M., and Iijima, T. (1982). "Speech Recognition by polarized
linear predictive error coding –POLPEC method," Electronics and Communications
in Japan, 65-A, 8, 9-18.
|
|
|