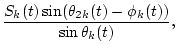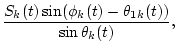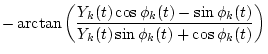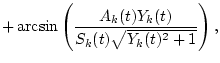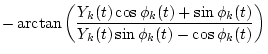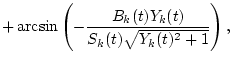The problem of segregating the desired signal from a noisy signal is an important issue not only in robust speech recognition systems but also in various types of signal processing. This problem has been investigated by many researchers, and many methods have been proposed. For example, an investigation of robust speech recognition [Furui and Sondhi1991], includes noise reduction or suppression [Boll1979] and speech enhancement methods [Junqua and Haton1996]. An investigation of signal processing includes signal estimation using a linear system [Papoulis1977] and signal estimation based on a stochastic process for signals and noise [Papoulis1991]. One recent proposal is Blind Separation [Shamsunder and Giannakis1997], which estimates the inverse-translation-operator (input-output translation function) by using the observed signal to estimate the original input.
However, in practice, it is difficult to segregate each original signal from a mixed signal, because this problem is an ill-posed inverse problem and the signals exist in a concurrent time-frequency region. Furthermore this problem is difficult to solve without using constraints on acoustic sources and the real environment.
On the other hand, the human auditory system can easily segregate the desired signal in a noisy environment that simultaneously contains speech, noise, and reflections. Recently, this ability of the auditory system has been regarded as a function of an active scene analysis system called "Auditory Scene Analysis (ASA)". ASA has become widely known as a result of Bregman's book [Bregman1990]. Bregman has reported that the human auditory system uses four psychoacoustically heuristic regularities related to acoustic events to solve the problem of Auditory Scene Analysis. These regularities are (i) common onset and offset, (ii) gradualness of change, (iii) harmonicity, and (iv) changes occurring in the acoustic event [Bregman1993]. If an auditory sound segregation model were constructed using constraints related to these heuristic regularities, it should be possible to uniquely solve the sound segregation problem (ill-posed inverse problem). In addition, this model should be applicable not only to a preprocessor for robust speech recognition systems but also to various types of signal processing.
Some ASA-based investigations have shown that it is possible to solve the segregation problem by applying constraints to sounds and the environment. These approaches are called "Computational Auditory Scene Analysis (CASA)". Some CASA-based sound segregation models already exist. There are two main types of models, based on either bottom-up or top-down processes. Typical bottom-up models include an auditory sound segregation model based on acoustic events [Cooke1993,Brown1992], a concurrent harmonic sounds segregation model based on the fundamental frequency [de Cheveigne1993], and a sound source separation system with an automatic tone modeling ability [Kashino and Tanaka1993]. Typical top-down models include a segregation model based on psychoacoustic grouping rules [Ellis1996] and a computational model of sound segregation agents [Nakatani et al.1995a,Nakatani et al.1995b]. All of these models use some of the four regularities and the amplitude (or power) spectrum as the acoustic feature. Thus, they cannot completely extract the desired signal from a noisy signal when the signal and noise exist in the same frequency region.
In contrast, we have been tackling the problem of segregating two acoustic sources as a fundamental problem. We believe that this problem can be uniquely solved by using amplitude, phase information, and mathematical constraints related to the four psychoacoustically heuristic regularities [Unoki and Akagi1997,Unoki and Akagi1999a].
This fundamental problem is defined as follows [Unoki and Akagi1997,Unoki and Akagi1999a].
First, only the mixed signal f(t), where
f(t)=f1(t)+f2(t), can be observed.
Next, f(t) is decomposed into its frequency components by a filterbank (the number of channels is K).
The output of the k-th channel Xk(t) is represented by
| X1,k(t) | = | (2) | |
| X2,k(t) | = | (3) |
| Yk(t) | = | (8) | |
| Zk(t) | = | Sk(t)2-Ak(t)2-Bk(t)2. | (9) |
To overcome this problem, we have tried to construct a basic solution using constraints related to the four regularities [Unoki and Akagi1997,Unoki and Akagi1999a]. Thus, we have proposed a sound segregation model based on auditory scene analysis [Unoki and Akagi1999b]. This model solves the problem of segregating two acoustic sources by using constraints on the continuity of instantaneous phases as well as constraints on the continuity of instantaneous amplitudes and fundamental frequencies. In simulations, we showed that all constraints related to the four regularities are useful in segregating an AM-FM harmonic complex tone from a noisy AM-FM harmonic complex tone. We also showed that the proposed model can precisely segregate a real vowel from a noisy vowel even in waveforms.
However, this model has the following disadvantages:
This paper proposes an improved sound segregation model based on auditory scene analysis to overcome the above disadvantages.