| Regularity (Bregman, 1993) | Constraint (Unoki and Akagi, | 1999) |
| (i) Unrelated sounds seldom start or stop at exactly | Synchronism of onset/offset |
|
| the same time ( common onset/offset) |
|
|
| (ii) Gradualness of change | (a) Slowness (piecewise- | dAk(t)/dt=Ck,R(t) |
| (a) A single sound tends to smoothly and slowly | differentiable polynomial |
|
| change its properties | approximation) | dF0(t)/dt=E0,R(t) |
| (b) A sequence of sounds from the same source | (b) Smoothness |
|
| tends to slowly change its properties | (Spline interpolation) |
|
|
|
||
|
|
||
| (iii) When a body vibrates with a repetitive period, | Multiples of the repetitive | |
| these vibrations give rise to an acoustic pattern | fundamental frequency |
|
| in which the frequency components are multiples |
|
|
| of a common fundamental ( harmonicity) | ||
| (iv) Many changes that take place in an acoustic | (a) Slow modulation | |
| event will affect all components of the result- | Correlation between the |
|
| ing sound in the same way and at the | instantaneous amplitudes | |
| same time | (b) Fast modulation | |
| Channel envelopes with |
|
|
| periodicity at the F0(t) |
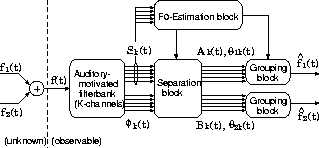
In this paper, the desired signal f1(t) is assumed to be a harmonic complex tone, where F0(t) is the fundamental frequency.
The proposed model segregates the desired signal from the mixed signal by constraining the temporal differentiation of Ak(t),
![]() ,
and F0(t).
,
and F0(t).
The proposed model is composed of four blocks: an auditory-motivated filterbank, an F0 estimation block, a separation block, and a grouping block, as shown in Fig. 1. Constraints used in this model are shown in Table 1.