Researh Topics
Our research focuses the following topics.
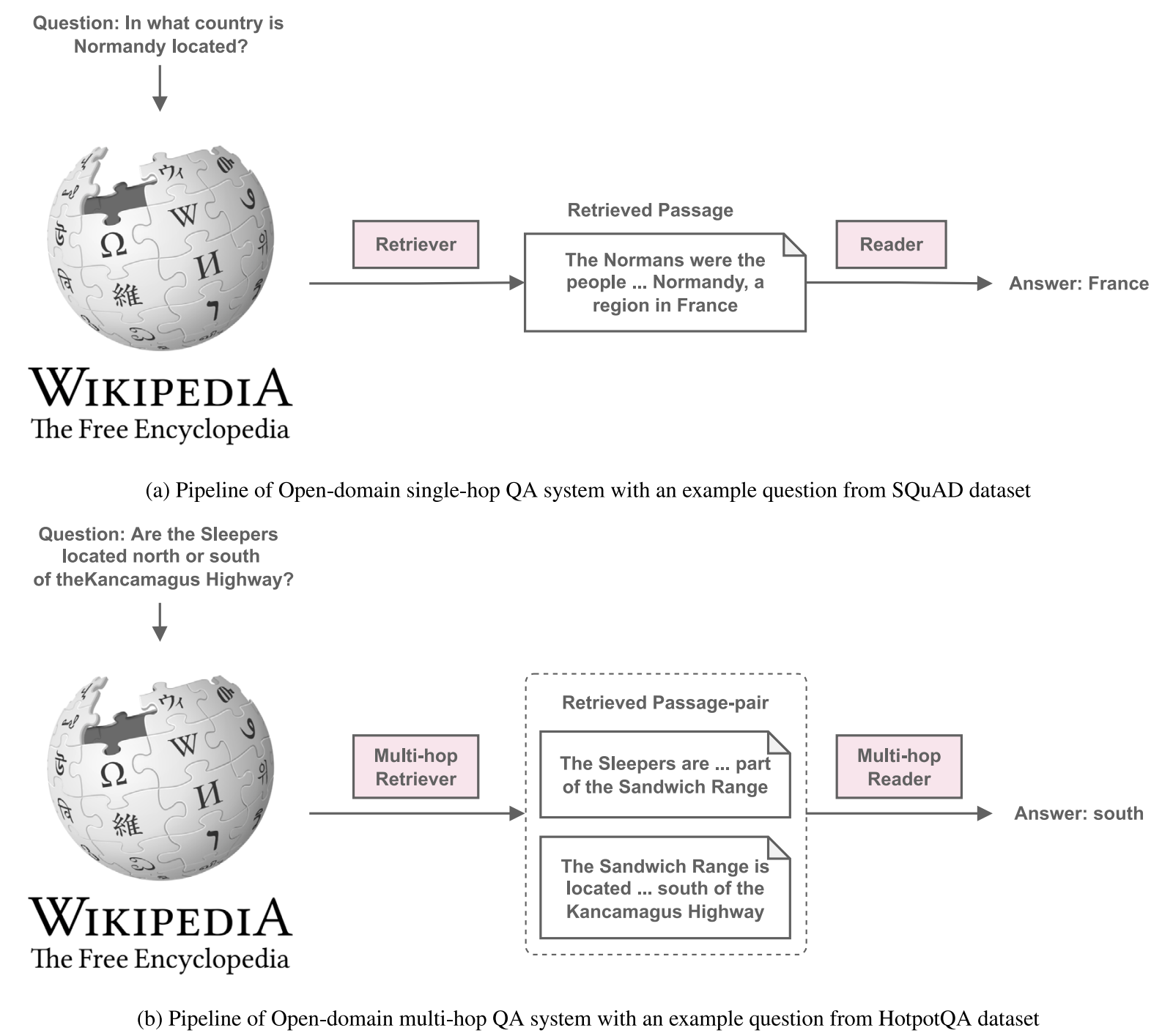
Open-Domain Question-Answering
Open-domain Question-Answering (ODQA) task requires a QA system to answer a given question using a large knowledge base like Wikipedia. ODQA is one of the most important tasks in NLP and is employed in many practical applications.
Multilingual and Low-resource Question-Answering
Although resource-rich languages like English witnessed many advancements in Open-domain QA, these methods often suffer from low-resource language situations (Vietnamese, Japanese, etc.). Developing efficient Open-domain QA systems for single and multi-hop questions in low-resource languages have many potential applications and remain a challenging task.
Multi-modal Question-Answering
Visual-Question-Answering (VQA) is an important task requiring systems to answer natural language questions corresponding to visual information. VQA has a long history and has seen many advances in recent years. VQA tasks are diverse across many domains and require many reasoning skills
Multi-hop & Mathematics QA
Many Question-Answering tasks require advanced skills such as Multi-hop Question-Answering or Mathematical reasoning. These are important tasks in Question-Answering and intriguing research topics.
Publication
Recent publications from our team
Papers
ViWiQA: Efficient end-to-end Vietnamese Wikipedia-based Open-domain Question-Answering systems for single-hop and multi-hop questions
Author: Dieu-Hien Nguyen, Nguyen-Khang Le, Le-Minh Nguyen
Information Processing & Management, Volume 60, Issue 6, 2023
Abstract: Open-domain Question-Answering (QA) task requires a QA system to answer a given question using a large knowledge base like Wikipedia. Modern Open-domain QA systems often follow the two-stage framework Retriever-Reader where the retriever greatly impacts the end-to-end performance. Efficient Vietnamese Open-domain QA systems for single and multi-hop questions have yet to be studied. Although resource-rich languages like English witnessed many advancements in Open-domain QA, these methods often suffer from low data situations. This study proposes ViWiQA, an efficient Vietnamese Open-domain QA system over the Wikipedia knowledge base, with two novel retriever methods for single-hop and multi-hop questions. ViWiQA can be effectively trained with low data and significantly outperforms Lucene-BM25 and Dense Passage Retrieval when adapted to Vietnamese datasets. For single-hop QA, the proposed retriever outperforms Lucene-BM25 by 20% in top-1 retrieval accuracy, and the end-to-end system achieves 15% and 17% absolute gain in EM and F1 scores, respectively. For multi-hop QA, the proposed retriever increases the accuracy of retrieving correct passage pairs by 4% compared to Lucene-BM25, and the end-to-end system shows 7% and 17% absolute gains in EM and F1 scores.
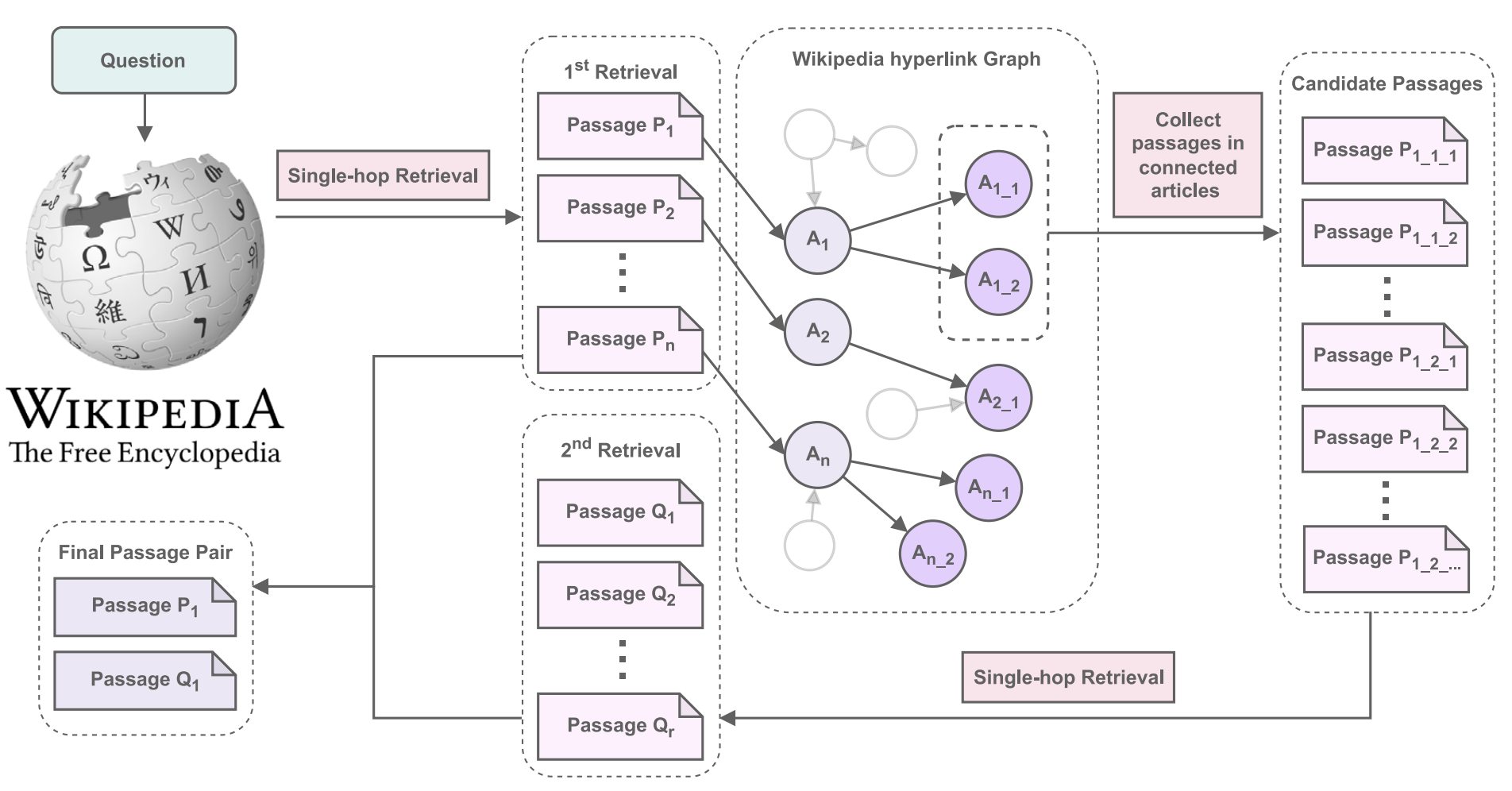
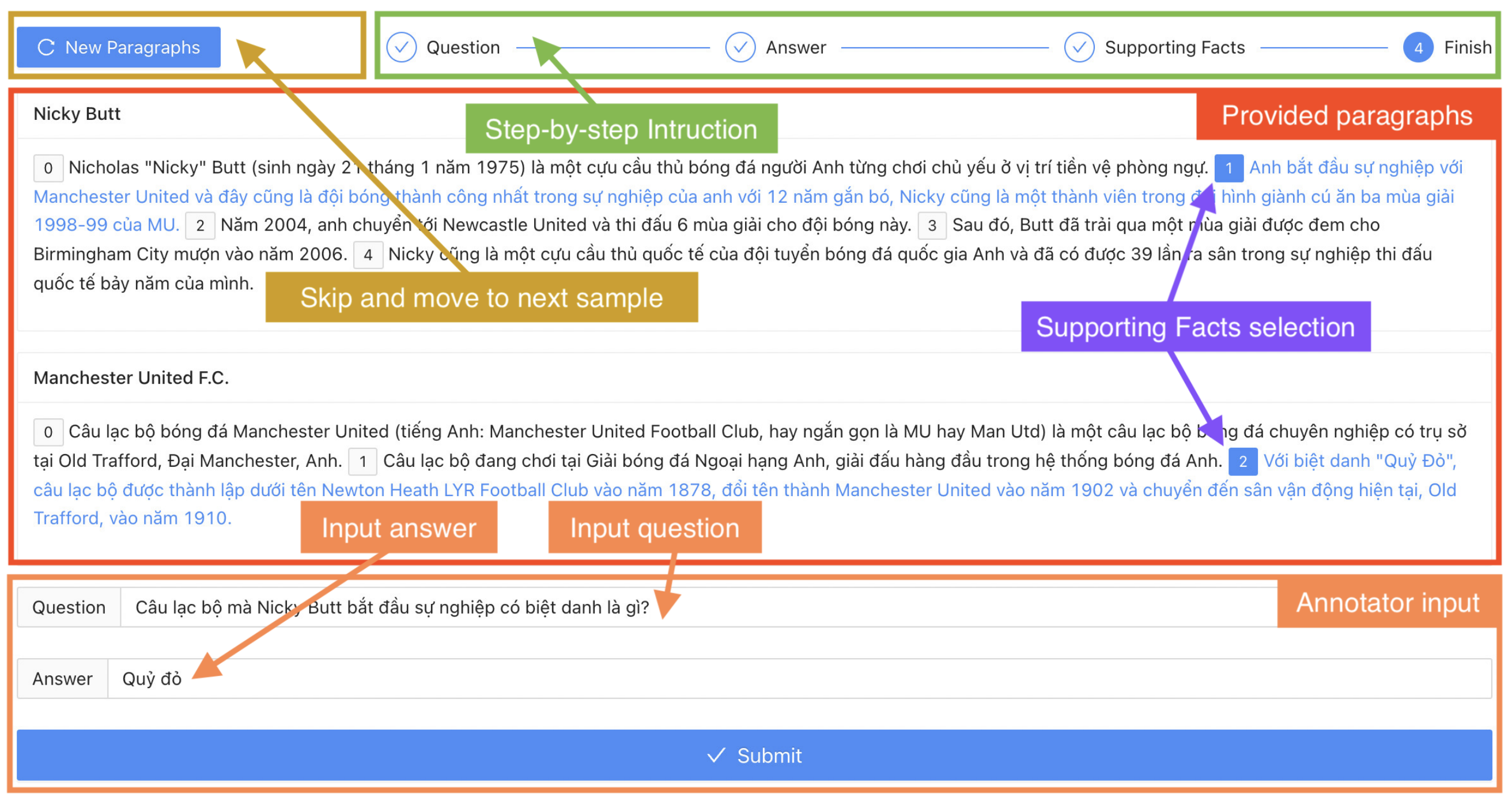
VIMQA: A Vietnamese Dataset for Advanced Reasoning and Explainable Multi-hop Question Answering
Author: Nguyen-Khang Le, Dieu-Hien Nguyen, Le-Minh Nguyen
In Proceedings of the Thirteenth Language Resources and Evaluation Conference (LREC 2022)
Abstract: Vietnamese is the native language of over 98 million people in the world. However, existing Vietnamese Question Answering (QA) datasets do not explore the model’s ability to perform advanced reasoning and provide evidence to explain the answer. We introduce VIMQA, a new Vietnamese dataset with over 10,000 Wikipedia-based multi-hop question-answer pairs. The dataset is human-generated and has four main features: (1) The questions require advanced reasoning over multiple paragraphs. (2) Sentence-level supporting facts are provided, enabling the QA model to reason and explain the answer. (3) The dataset offers various types of reasoning to test the model’s ability to reason and extract relevant proof. (4) The dataset is in Vietnamese, a low-resource language. We also conduct experiments on our dataset using state-of-the-art Multilingual single-hop and multi-hop QA methods. The results suggest that our dataset is challenging for existing methods, and there is room for improvement in Vietnamese QA systems. In addition, we propose a general process for data creation and publish a framework for creating multilingual multi-hop QA datasets. The dataset and framework are publicly available to encourage further research in Vietnamese QA systems.
Exploring Retriever-Reader Approaches in Question-Answering on Scientific Documents
Author: Dieu-Hien Nguyen, Nguyen-Khang Le, Le-Minh Nguyen
In Recent Challenges in Intelligent Information and Database Systems. ACIIDS 2022
Abstract: As readers of scientific articles often read to answer specific questions, the task of Question-Answering (QA) in academic papers was proposed to evaluate the ability of intelligent systems to answer questions in long scientific documents. Due to the large contexts in the questions, this task poses many challenges to state-of-the-art QA models. This paper explores the retriever-reader approaches widely used in open-domain QA and their impact when adapting to QA on long scientific documents. By treating one scientific article as the corpus for retrieval, we propose a retriever-reader method to extract the answer from the relevant parts of the document and an effective sliding window technique that improves the pipeline by splitting the articles into disjoint text blocks of fixed size. Experiments on QASPER, a dataset for QA in Natural Language Processing papers, showed that our method outperforms all state-of-the-art models and establishes a new state-of-the-art in the extractive questions subset with 30.43% F1.

A Novel Pipeline to Enhance Question-Answering Model by Identifying Relevant Information
Author: Nguyen-Khang Le, Dieu-Hien Nguyen, Thi-Thu-Trang Nguyen, Minh Phuong Nguyen, Tung Le, Le-Minh Nguyen
In New Frontiers in Artificial Intelligence. JSAI-isAI 2021. Lecture Notes in Computer Science
Abstract: Question-Answering (QA) systems have increasingly drawn much interest in the research community. A significant number of methods and datasets are proposed for the QA tasks. One of the gold standard QA resources is span-extraction Machine Reading Comprehension datasets, where the system must extract a span of text from the context to answer the question. Although state-of-the-art methods for span-extraction QA are proposed, distracting information in the context can be a significant factor that reduces these methods’ performance. Especially, QA in scientific documents has massive contexts whose only a small part contains the relevant information to answer the question. As a result, it is challenging for QA models to arrive at the answer in scientific documents. As an observation, performance can be improved by only considering relevant sentences. This study proposed a novel pipeline to enhance the performance of existing QA methods by identifying and keeping relevant information from the context. The proposed pipeline is model-agnostic, multilingual, and can be flexibly applied to any QA model to increase performance. Our experiments on QA datasets in scientific documents (Qasper) and SQuAD 2.0 show that our approach successfully improves the performance of state-of-the-art QA models. Especially, our detailed comparisons reveal the effectiveness and flexibility of our proposed models in enhancing the current QA systems in low-resource languages such as Vietnamese (UIT-VIQUAD).

Awards
Our Team

Professor. Nguyen Le Minh
Director of Research Centre for Interpretable AI at JAIST
MSc. Le Nguyen Khang
PhD Student at Nguyen's Lab
MSc. Nguyen Dieu Hien
PhD Student at Nguyen's LabContact Us
We are seeking students passionate about Natural Language Processing (NLP) and Deep Learning.
Location:
IS Building Ⅲ 7F, 1 Chome-1 Asahidai, Nomi, Ishikawa, Japan
Email:
nguyenml[at]jaist.ac.jp
Call:
+81 761-51-1221