Publication
Recent publications from our team
Papers
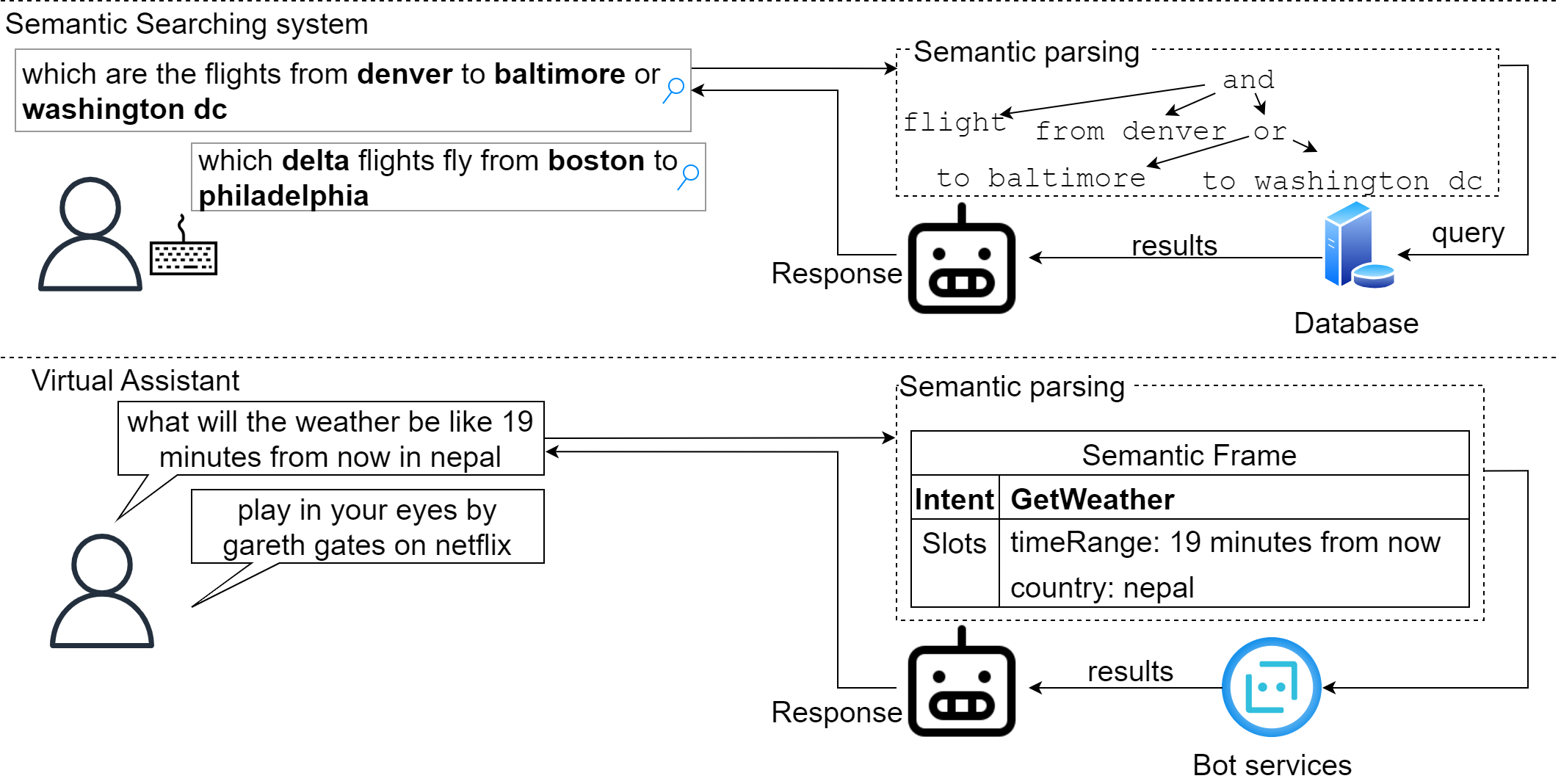
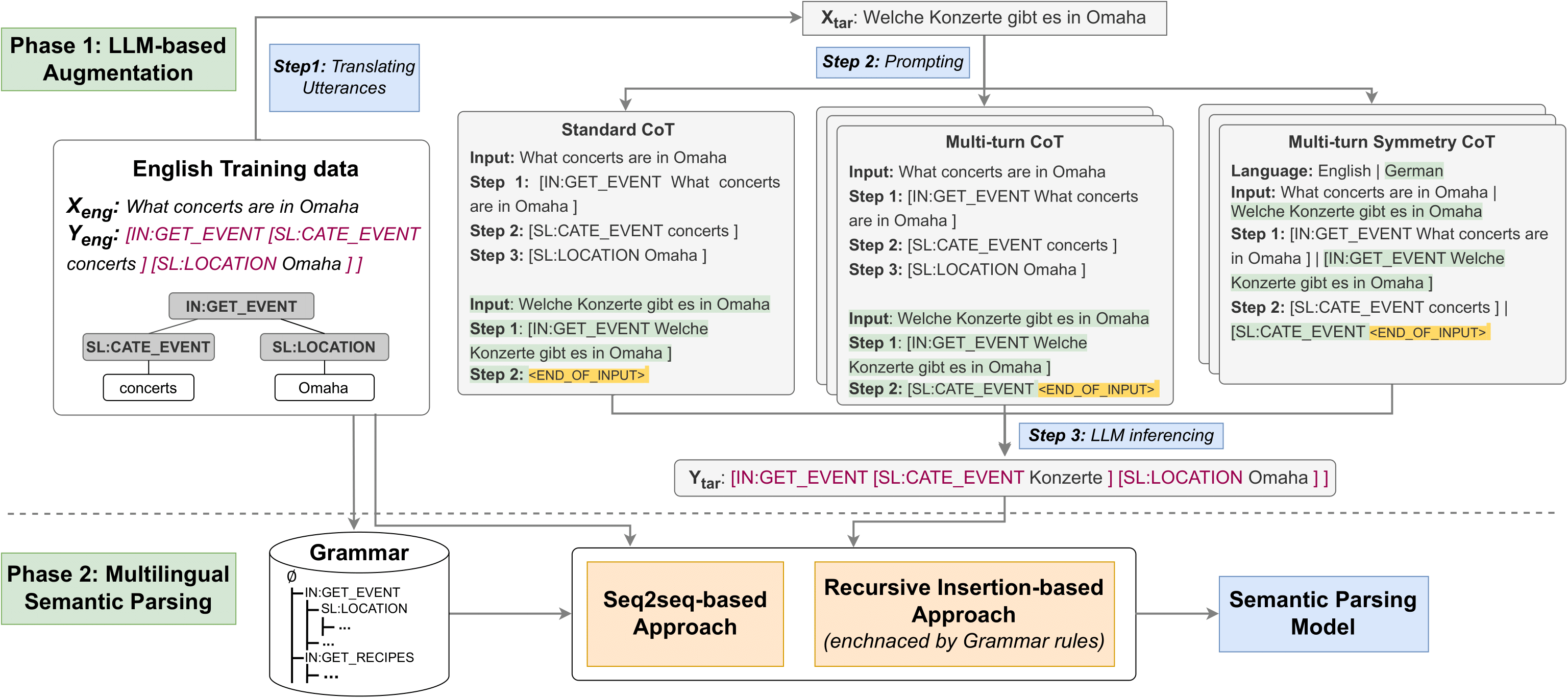
ZeLa: Advancing Zero-Shot Multilingual Semantic Parsing with Large Language Models and Chain-of-Thought Strategies
Author: Dinh-Truong Do, Minh-Phuong Nguyen and Le-Minh Nguyen
In 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024) (Accepted)
Abstract: In recent years, there have been significant advancements in semantic parsing tasks, thanks to the introduction of pre-trained language models. However, a substantial gap persists between English and other languages due to the scarcity of annotated data. One promising strategy to bridge this gap involves augmenting multilingual datasets using labeled English data and subsequently leveraging this augmented dataset for training semantic parsers (known as zero-shot multilingual semantic parsing). In our study, we propose a novel framework to effectively perform zero-shot multilingual semantic parsing under the support of large language models (LLMs). Given data annotated pairs (sentence, semantic representation) in English, our proposed framework automatically augments data in other languages via multilingual chain-of-thought (CoT) prompting techniques that progressively construct the semantic form in these languages. By breaking down the entire semantic representation into sub-semantic fragments, our CoT prompting technique simplifies the intricate semantic structure at each step, thereby facilitating the LLMs in generating accurate outputs more efficiently. Notably, this entire augmentation process is achieved without the need for any demonstration samples in the target languages (zero-shot learning). In our experiments, we demonstrate the effectiveness of our method by evaluating it on two well-known multilingual semantic parsing datasets: MTOP and MASSIVE.
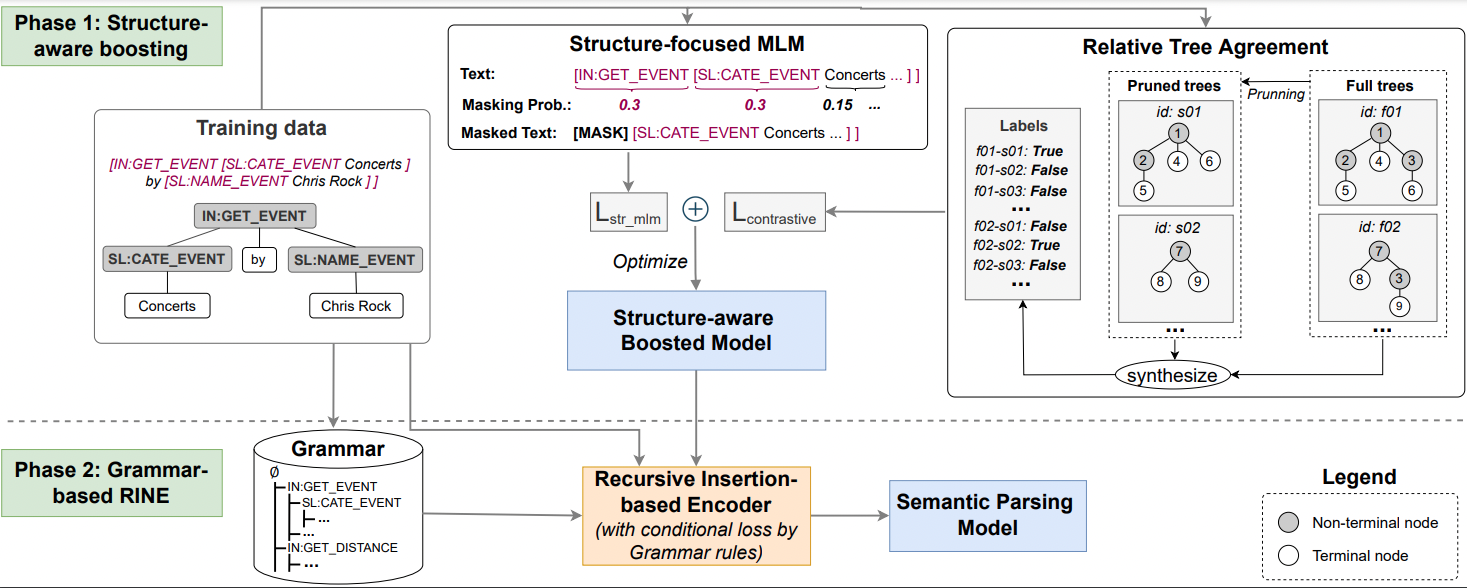
StructSP: Efficient Fine-tuning of Task-Oriented Dialog System by Using Structure-aware Boosting and Grammar Constraints
Author: Dinh-Truong Do, Minh-Phuong Nguyen and Le-Minh Nguyen
In Findings of the Association for Computational Linguistics: ACL 2023. Association for Computational Linguistics.
Abstract: We have investigated methods utilizing hierarchical structure information representation in the semantic parsing task and have devised a method that reinforces the semantic awareness of a pre-trained language model via a two-step fine-tuning mechanism: hierarchical structure information strengthening and a final specific task. The model used is better than existing ones at learning the contextual representations of utterances embedded within its hierarchical semantic structure and thereby improves system performance. In addition, we created a mechanism using inductive grammar to dynamically prune the unpromising directions in the semantic structure parsing process. Finally, through experimentsOur code will be published when this paper is accepted. on the TOP and TOPv2 (low-resource setting) datasets, we achieved state-of-the-art (SOTA) performance, confirming the effectiveness of our proposed model.
GRAM: Grammar-Based Refined Label Representing Mechanism in the Hierarchical Semantic Parsing Task
Author: Dinh-Truong Do, Minh-Phuong Nguyen and Le-Minh Nguyen
In Natural Language Processing and Information Systems. NLDB 2023.
Abstract: In this study, we proposed an efficient method to improve the performance of the hierarchical semantic parsing task by strengthening the meaning representation of the label candidate set via inductive grammar. In particular, grammar was first synthesized from the logical representations of training annotated data. Then, the model utilizes it as additional structured information for all expression label predictions. The grammar was also used to prevent unpromising directions in the semantic parsing process dynamically. The experimental results on the three well-known semantic parsing datasets, TOP, TOPv2 (low-resource settings), and ATIS, showed that our proposed method work effectiveness, which achieved new state-of-the-art (SOTA) results on TOP and TOPv2 datasets, and competitive results on the ATIS dataset.
PhraseTransformer: an incorporation of local context information into sequence-to-sequence semantic parsing
Author: Minh-Phuong Nguyen, Tung Le, Huy-Tien Nguyen, Vu Tran and Le-Minh Nguyen
In Computer Science Applied intelligence (Boston) 29 November 2022.
Abstract: Semantic parsing is a challenging task mapping a natural language utterance to machine-understandable information representation. Recently, approaches using neural machine translation (NMT) have achieved many promising results, especially the Transformer. However, the typical drawback of adapting the vanilla Transformer to semantic parsing is that it does not consider the phrase in expressing the information of sentences while phrases play an important role in constructing the sentence meaning. Therefore, we propose an architecture, PhraseTransformer, that is capable of a more detailed meaning representation by learning the phrase dependencies in the sentence. The main idea is to incorporate Long Short-Term Memory into the Self-Attention mechanism of the original Transformer to capture the local context of a word. Experimental results show that our proposed model performs better than the original Transformer in terms of understanding sentences structure as well as logical representation and raises the model local context-awareness without any support from external tree information. Besides, although the recurrent architecture is integrated, the number of sequential operations of the PhraseTransformer is still O(1) similar to the original Transformer. Our proposed model achieves strong competitive performance on Geo and MSParS datasets, and leads to SOTA performance on the Atis dataset for methods using neural networks. In addition, to prove the generalization of our proposed model, we also conduct extensive experiments on three translation datasets IWLST14 German-English, IWSLT15 Vietnamese-English, WMT14 English-German, and show significant improvement. Our code is available at https://github.com/phuongnm94/PhraseTransformer.git.
Learning to Map the GDPR to Logic Representation on DAPRECO-KB
Author: Minh-Phuong Nguyen, Thi-Thu-Trang Nguyen, Vu Tran, Ha-Thanh Nguyen, Le-Minh Nguyen and Ken Satoh
In Intelligent Information and Database Systems. ACIIDS 2022.
Abstract: General Data Protection Regulation (GDPR) is an important framework for data protection that applies to all European Union countries. Recently, DAPRECO knowledge base (KB) which is a repository of if-then rules written in LegalRuleML as a formal logic representation of GDPR has been introduced to assist compliance checking. DAPRECO KB is, however, constructed manually and the current version does not cover all the articles in GDPR. Looking for an automated method, we present our machine translation approach to obtain a semantic parser translating the regulations in GDPR to their logic representation on DAPRECO KB. We also propose a new version of GDPR Semantic Parsing data by splitting each complex regulation into simple subparagraph-like units and re-annotating them based on published data from DAPRECO project. Besides, to improve the performance of our semantic parser, we propose two mechanisms: Sub-expression intersection and PRESEG. The former deals with the problem of duplicate sub-expressions while the latter distills knowledge from pre-trained language model BERT. Using these mechanisms, our semantic parser obtained a performance of 60.49% F1 in sub-expression level, which outperforms the baseline model by 5.68%.
CAE: Mechanism to Diminish the Class Imbalanced in SLU Slot Filling Task
Author: Minh-Phuong Nguyen, Tung Le and Le-Minh Nguyen
In Advances in Computational Collective Intelligence. ICCCI 2022.
Abstract: Spoken Language Understanding (SLU) task is a wide application task in Natural Language Processing. In the success of the pre-trained BERT model, NLU is addressed by Intent Classification and Slot Filling task with significant improvement performance. However, classed imbalance problem in NLU has not been carefully investigated, while this problem in Semantic Parsing datasets is frequent. Therefore, this work focuses on diminishing this problem. We proposed a BERT-based architecture named JointBERT Classify Anonymous Entity (JointBERT-CAE) that improves the performance of the system on three Semantic Parsing datasets ATIS, Snips, ATIS Vietnamese, and a well-known Named Entity Recognize (NER) dataset CoNLL2003. In JointBERT-CAE architecture, we use multitask joint-learning to split conventional Slot Filling task into two sub-task, detect Anonymous Entity by Sequence tagging and Classify recognized anonymous entities tasks. The experimental results show the solid improvement of JointBERT-CAE when compared with BERT on all datasets, as well as the wide applicable capacity to other NLP tasks using the Sequence Tagging technique.
Marking mechanism in sequence-to-sequence model for mapping language to logical form
Author: Minh-Phuong Nguyen, Khoat Than and Le-Minh Nguyen
In 2019 11th International Conference on Knowlerdge and System Engineering (KSE'19)
Abstract: Spoken Language Understanding (SLU) task is a wide application task in Natural Language Processing. In the success of the pre-trained BERT model, NLU is addressed by Intent Classification and Slot Filling task with significant improvement performance. However, classed imbalance problem in NLU has not been carefully investigated, while this problem in Semantic Parsing datasets is frequent. Therefore, this work focuses on diminishing this problem. We proposed a BERT-based architecture named JointBERT Classify Anonymous Entity (JointBERT-CAE) that improves the performance of the system on three Semantic Parsing datasets ATIS, Snips, ATIS Vietnamese, and a well-known Named Entity Recognize (NER) dataset CoNLL2003. In JointBERT-CAE architecture, we use multitask joint-learning to split conventional Slot Filling task into two sub-task, detect Anonymous Entity by Sequence tagging and Classify recognized anonymous entities tasks. The experimental results show the solid improvement of JointBERT-CAE when compared with BERT on all datasets, as well as the wide applicable capacity to other NLP tasks using the Sequence Tagging technique.
Demostration System
There are demostration systems of our works.
Monolingual Semantic Parser
Our system specializes in parsing English sentences into hierarchical semantic representations. At present, we offer support for two specific domains: Navigation and Event.
Multilingual Semantic Parsr
Our system specializes in multilingual semantic parser (English, German, French, etc.). At present, we offer support for specific domains: Alarm, Calling, Event, Messaging, Music, News, People, Recipes, Reminder, Timer and Weather.
Our Team

Professor. Nguyen Le Minh
Director of Research Centre for Interpretable AI at JAIST
PhD. Nguyen Minh Phuong
Postdoctoral Researcher at Nguyen's Lab
MSc. Do Dinh Truong
PhD Student at Nguyen's LabContact Us
We are seeking students passionate about Natural Language Processing (NLP) and Deep Learning.
Location:
IS Building Ⅲ 7F, 1 Chome-1 Asahidai, Nomi, Ishikawa, Japan
Email:
nguyenml[at]jaist.ac.jp
Call:
+81 761-51-1221