Publication
Recent publications from our team
Papers
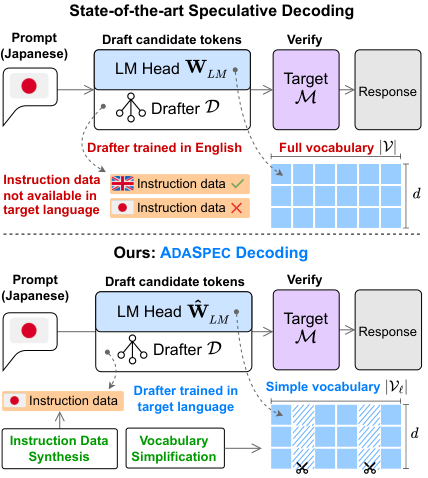
AdaSpec: Adaptive Multilingual Speculative Decoding with Self-Synthesized Language-Aware Training and Vocabulary Simplification
Author: Dinh-Truong Do, Nguyen-Khang Le, Le-Minh Nguyen
AAAI 2026
Abstract: Speculative decoding accelerates large language model (LLM) inference by using a lightweight drafter to propose multiple tokens, which are then verified in parallel by the base model. While effective in English, existing methods often struggle in multilingual scenarios due to static vocabularies and the lack of language-specific instruction data. To address these limitations, we present AdaSpec, a multilingual speculative decoding framework that dynamically adapts both the drafter and vocabulary at decoding time. AdaSpec generates language-specific instruction data using the LLM itself, enabling training of drafters for low-resource languages. It also constructs adaptive vocabularies tailored to each language's characteristics. In addition, we introduce Multi-SpecBench, a comprehensive multilingual benchmark covering seven languages and seven generation tasks, to evaluate multilingual speculative decoding performance. Extensive experiments show that AdaSpec achieves up to 2.3× speedup over the state-of-the-art method of EAGLE-2, even in English, demonstrating its effectiveness across diverse languages and tasks.
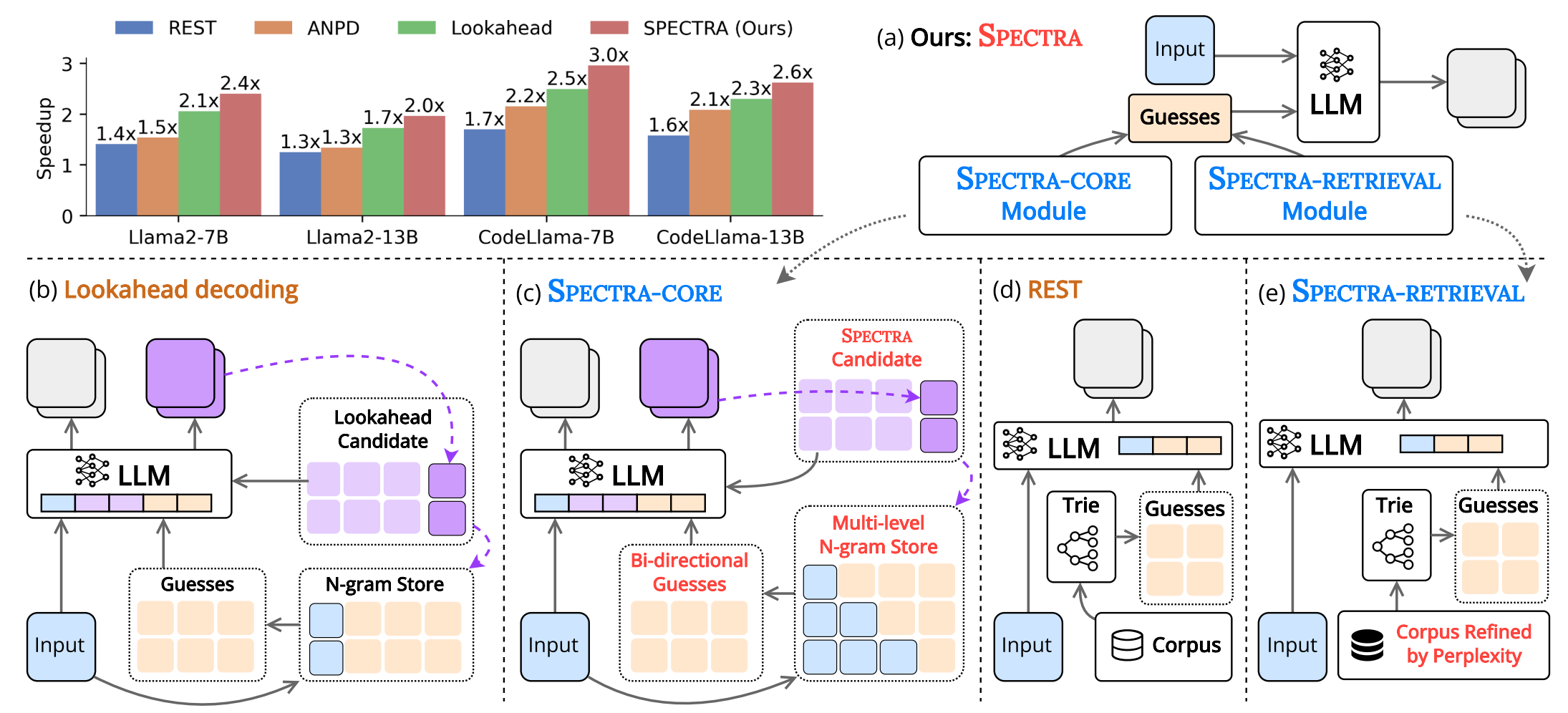
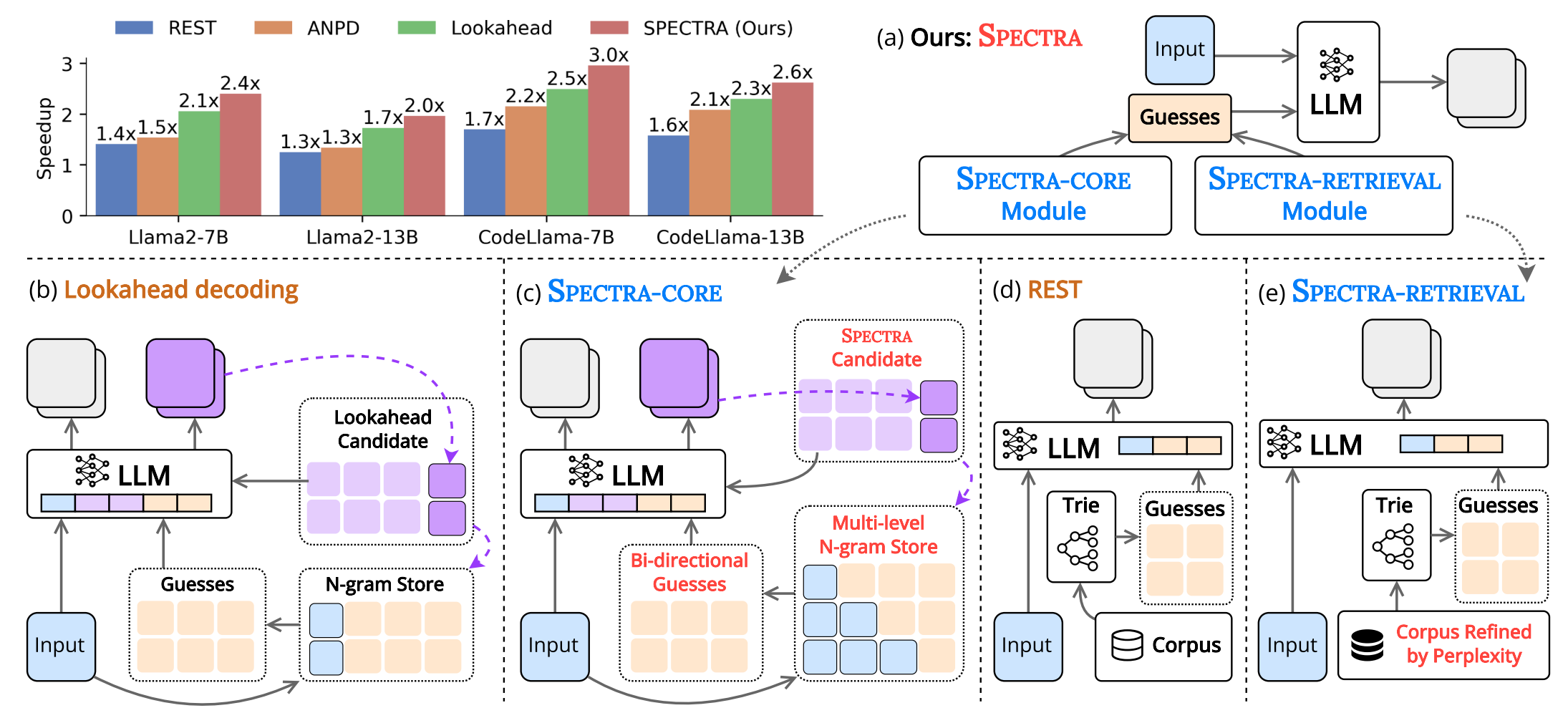
SPECTRA: Faster Large Language Model Inference with Optimized Internal and External Speculation
Author:Nguyen-Khang Le, Dinh-Truong Do, Le-Minh Nguyen
ACL 2025
Abstract: Inference with modern Large Language Models (LLMs) is both computationally expensive and time-consuming. Speculative decoding has emerged as a promising solution, but existing approaches face key limitations: training-based methods require a draft model that is challenging to obtain and lacks generalizability, while training-free methods offer limited speedup gains. In this work, we present Spectra, a novel framework for accelerating LLM inference without the need for additional training or modification to the original LLM. Spectra introduces two new techniques for efficiently utilizing internal and external speculation, each outperforming corresponding state-of-the-art (SOTA) methods independently. When combined, these techniques achieve up to a 4.08x speedup across various benchmarks and LLM architectures, significantly surpassing existing training-free approaches. The implementation of Spectra is publicly available.
Our Team

Professor. Nguyen Le Minh
Director of Research Centre for Interpretable AI at JAIST
MSc. Do Dinh Truong
PhD Student at Nguyen's Lab
MSc. Le Nguyen Khang
PhD Student at Nguyen's LabContact Us
We are seeking students passionate about Natural Language Processing (NLP) and Deep Learning.
Location:
IS Building Ⅲ 7F, 1 Chome-1 Asahidai, Nomi, Ishikawa, Japan
Email:
nguyenml[at]jaist.ac.jp
Call:
+81 761-51-1221