研究概要
「音楽は確かに楽しみを与えてくれるものだが,音楽を生み出す能力は,日々の生活に直接役立つものとは言い難い.人間の持つ能力のうちでもとりわけ神秘的なものである.どんな人種にもどんな未開人にも音楽はある.いたって未熟なもの,原始的なものであるかも知れないが,ともかく音楽は持っている」
「はるかな過去には,男も女も,言語によって自らの愛を明確に表現することはできなかったであろう.その代わりに使ったのは音楽ではないか.旋律とリズムの力によって愛する人を惹きつけようとしたのではないだろうか」
-- チャールズ・ダーウィン: The Descent of Man (1871)
ダーウィンのこの考え方は音楽・言語を同一起源とする,次の仮説に基づく.『人類の進化の過程においては,脳の発達とともに人類はより複雑な言語を獲得していった.太古の人類が持っていた未熟なコミュニケーション手段のうち,有意味な部分のみが言語として独立し,音楽はその名残りである.』この仮説にも疑念はある.なぜ未熟な言語である音楽は,新言語に完全に置き代わることなく,忘れ去られなかったのか? あるいは,言語を芽生えさせた人類も,なぜ未熟な原始言語から音楽を独立させたのか? 進化言語学の研究においては,言語は化石を作らないために,仮説を検証することができない.しかし,音楽・言語同一起源説はそれなりに説得力を持つ.ノーム・チョムスキー(1928~)は,人間の言語は句構造文法を持つとした.すなわち,隣り合った文字列が語を作り,句を作り,さらには節を作って文は階層的な木構造を作ると考える.そして,音楽にもこのような階層的な木構造が存在する!
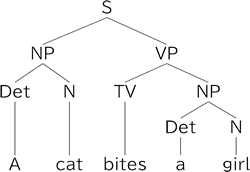
20世紀の初頭,ハインリッヒ・シェンカー(1868~1935)は,楽曲には構造上重要な音とそうでない音があると考えた.重要な音は楽曲の骨格をなすUrsatz (基本形)と呼ばれ,音楽の意味であるとする.これらの音は重要度の比較において前景・中景・後景をなすとした.前景は多くの装飾的な音を含む楽曲の表面である.そこから重要な音のみに簡約する操作により,多段階の中景を経て後景として上声部には旋律線・下声部にはトニック--ドミナント--トニックという進行が残るとした.
図1.3:シェンカー理論における楽曲の基本構造
シェンカーの理論を実装するためには,楽曲を構成する各楽音を重要度において比較する指標が必要である.JackendoffとLehrdahlによるGenerative Theory of Tonal Music (GTTM)は,この指標を明示化し,楽曲を簡約化する手順を与えた.楽曲の各音は隣り合う音を重要度で比較することで,ボトムアップなトーナメントによる簡約操作ができる.この結果,曲全体は木構造をなす.上層部に残った音は,シェンカーの意味で重要な音である.

文法による木構造生成
我々はGTTMを計算機科学の視点から読み直し,重要度による簡約の操作をコンピュータ・システムに実装した.この結果得られる楽曲の木構造を用いて,楽曲の編曲・類似度比較・モーフィングなど顕著な成果を挙げてきた.また同時に,我々は自然言語の文法理論を研究し,文が文法規則にしたがって階層的な木構造をなし,語の意味が構文木にしたがって構成的に組み合わされて全体の意味を形成するプロセスを実装してきた.今日では,ウェブ上の豊富なディジタル音楽データが利用可能になっており,その構造生成・意味理解においては先行する自然言語処理の現代的な成果を援用すべき好機にある.
確率として得られる文法
我々は日本語の文法規則を学んだわけでもないのに,日本語文を生成することができる.文法規則は外から(親や先生から)与えられたのではない.チョムスキー的な考え方をすれば,人間の赤ちゃんにはこうした第一言語を獲得するひな形があるとし,我々は自身でこのひな形を整形したことになる.実際,我々は第二言語(外国語)を学ぶとき,文法を学んだほうが効率が良かった.赤ちゃんのときのひな形は既に使用済みで,再利用できないらしい.
ところで,ある言語の文法規則をすべて書き下すことは可能だろうか.可能であるにしても稀れにしか使われない規則まで含めて,すべてを規則化する意味はあるだろうか.我々は現在,膨大なコーパスを電子データとして持っている.ならば,文法は単なる統計的な傾向であり,規則は使用頻度まで含めて統計的に取り出すべきである.音楽にしても同様である.音楽の木構造を作り,その構成的意味から内部の参照関係を捉えたいなら,文法は統計的に学習するのが効率的である.

構成的な意味論
ケルシュ(Koelsch)によれば,音楽が人間の外にある何かを表象するとき,形象的・指示的・象徴的な区別があるとした.形象的意味とは,楽音が動物の鳴き声・雷鳴や雨などの気象・川のせせらぎなど実在の何かを連想させ,オノマトペのように,あるいは形象文字のように働く意味である.指示的意味は,個人の感情を喚起する.すなわち,音楽が喜びや悲しみ,愛・嫌悪・絶望と言った情動を引き起こすものであると考える.象徴的意味とは,特定の音楽を聴くことによってそれと結びついた社会的規範を想起させる意味である.「ほたるの光」や国歌が我々にどのような行動規範を催すか考えるとよい.
一方,構成的意味論とは,このような人間の認知的意味論とは別に,階層的な木構造がなす意味である.すなわち文法構成に基づいて,パーツの意味を組み合わせることによって得られた全体が,木の意味であるとする.
この両者は全く切り離して考えることはできない.情動は単音ではなく,ある長さの楽句を聞いて想起されるものである.形式的意味表現もパーツを統合して得られるものであるから,いずれもゲシュタルト(個々の構成要素に意味を感じなくても,それらが組み合わさると全体として何かを表象する)意味と考えられる.楽曲内には,楽譜上必ずしも明示されていない関係がある.例えば和音間の遠隔の依存関係,楽句(あるいはモティーフ)によるグループ構造,繰り返し構造,対称構造などが内在している.これらを楽句の間の参照関係と捉え,それらを発見をすることは,構成的意味論におけるゲシュタルト意味の構成と考えられる.
この研究の企図するところは,音楽の情動を論理的に議論する俎上に載せることにある.言語コミュニケーションにおいては,話者と聴者が同じ構文木を構成でき,照応詞に同じ参照関係ができた場合に相互理解ができたと考えた.音楽においても同様に,これまで情動として曖昧に論じられてきた音楽の認知的意味に対し,本研究では聴者が受け取った木のトポロジー(内部参照関係含めて)の再現が音楽意味の伝達であると考える.

学術的な特色・独創的な点
- 最新の統計的機械学習・計算言語学の技術を武器に,楽曲の確率文脈自由文法モデルを確立する.本モデルを教師なし学習することは,人間が音楽的な訓練を受けずに音楽的感覚を自己組織的に身につける知能の計算モデルとなっている.これは,表層的な音楽情報処理ではなく,人間の内部観測を伴う新たな研究体系の先駆けである.
- 楽曲から得られる構文木において,内部の依存関係(参照関係)を付加して楽曲の構成的意味とする.木構造は解析結果の情報によってアノテートされたゲシュタルト意味構造とする.
- 楽曲の代わりに木構造を代数的に編集操作するという工学的視点に立ち,解析・作曲・編曲に応用する.
