2024
ZeLa: Advancing Zero-Shot Multilingual Semantic Parsing with Large Language Models and Chain-of-Thought Strategies Inproceedings
In: Calzolari, Nicoletta; Kan, Min-Yen; Hoste, Veronique; Lenci, Alessandro; Sakti, Sakriani; Xue, Nianwen (Ed.): Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), pp. 17783–17794, ELRA and ICCL, Torino, Italia, 2024.
A Decoupling and Aggregating Framework for Joint Extraction of Entities and Relations Journal Article
In: IEEE Access, 2024.
Vietnamese Elementary Math Reasoning Using Large Language Model with Refined Translation and Dense-Retrieved Chain-of-Thought Inproceedings
In: JSAI International Symposium on Artificial Intelligence, pp. 260–268, Springer 2024.
Attentive deep neural networks for legal document retrieval Journal Article
In: Artificial Intelligence and Law, vol. 32, no. 1, pp. 57–86, 2024.
DA-TransUNet: integrating spatial and channel dual attention with transformer U-net for medical image segmentation Journal Article
In: Frontiers in Bioengineering and Biotechnology, vol. 12, pp. 1398237, 2024.
Captain at COLIEE 2023: efficient methods for legal information retrieval and entailment tasks Journal Article
In: arXiv preprint arXiv:2401.03551, 2024.
Employing label models on ChatGPT answers improves legal text entailment performance Journal Article
In: arXiv preprint arXiv:2401.17897, 2024.
FKD-Med: Privacy-Aware, Communication-Optimized Medical Image Segmentation via Federated Learning and Model Lightweighting through Knowledge Distillation Journal Article
In: IEEE Access, 2024.
VLSP 2023--LTER: A Summary of the Challenge on Legal Textual Entailment Recognition Journal Article
In: arXiv preprint arXiv:2403.03435, 2024.
A Mutual Inclusion Mechanism for Precise Boundary Segmentation in Medical Images Journal Article
In: arXiv preprint arXiv:2404.08201, 2024.
RPMTD: A Route Planning Model with Consideration of Tourists’ Distribution Journal Article
In: IEEE Access, 2024.
A Decoupling and Aggregating Framework for Joint Extraction of Entities and Relations Journal Article
In: IEEE Access, 2024.
CAPTAIN at COLIEE 2024: large language model for legal text retrieval and entailment Inproceedings
In: JSAI International Symposium on Artificial Intelligence, pp. 125–139, Springer Nature Singapore Singapore 2024.
Semantic Parsing for Question and Answering over Scholarly Knowledge Graph with Large Language Models Inproceedings
In: JSAI International Symposium on Artificial Intelligence, pp. 284–298, Springer Nature Singapore Singapore 2024.
Pushing the boundaries of legal information processing with integration of large language models Inproceedings
In: JSAI International Symposium on Artificial Intelligence, pp. 167–182, Springer Nature Singapore Singapore 2024.
Vietnamese Elementary Math Reasoning Using Large Language Model with Refined Translation and Dense-Retrieved Chain-of-Thought Inproceedings
In: JSAI International Symposium on Artificial Intelligence, pp. 260–268, Springer Nature Singapore Singapore 2024.
Directional cooperative networks Journal Article
In: Neurocomputing, vol. 593, pp. 127788, 2024.
ZeLa: Advancing Zero-Shot Multilingual Semantic Parsing with Large Language Models and Chain-of-Thought Strategies Inproceedings
In: Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), pp. 17783–17794, 2024.
2023
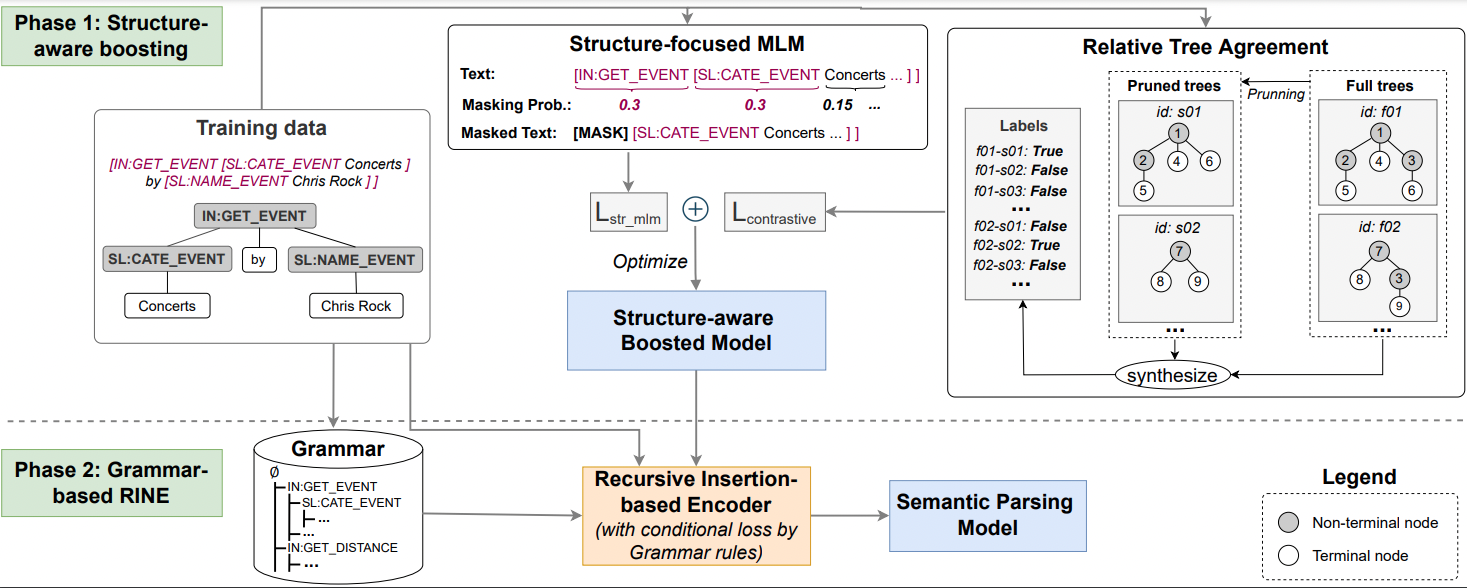
StructSP: Efficient Fine-tuning of Task-Oriented Dialog System by Using Structure-aware Boosting and Grammar Constraints Inproceedings
In: Findings of the Association for Computational Linguistics: ACL 2023, 2023.
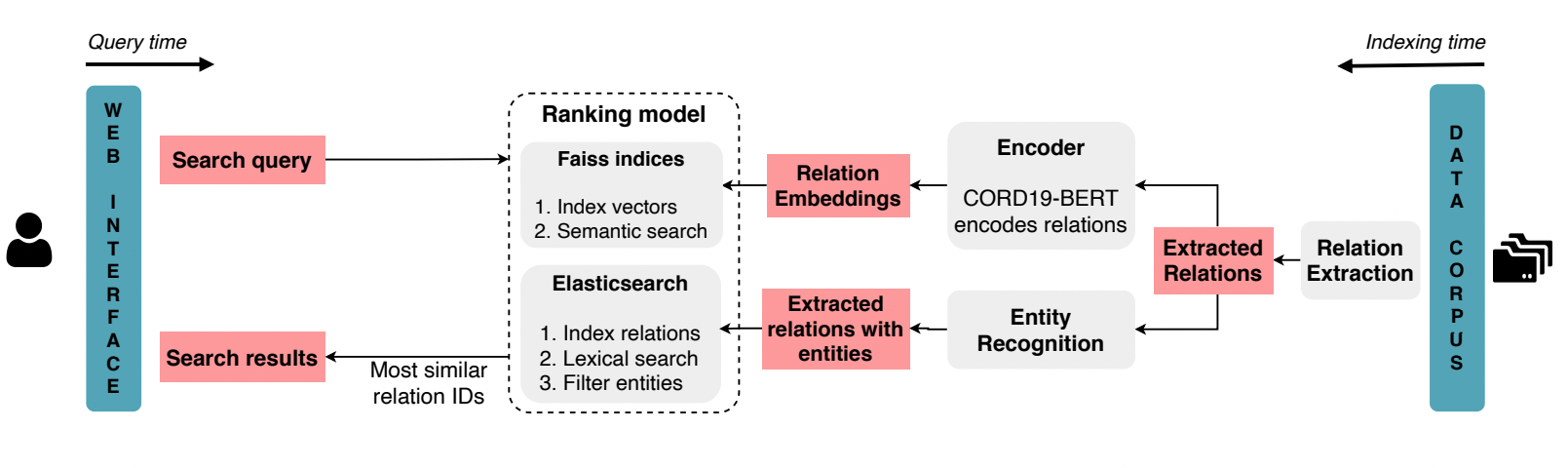
CovRelex-SE: Adding Semantic Information for Relation Search via Sequence Embedding Inproceedings
In: Proceedings of the 17th conference of the european chapter of the association for computational linguistics: system demonstrations, 2023.
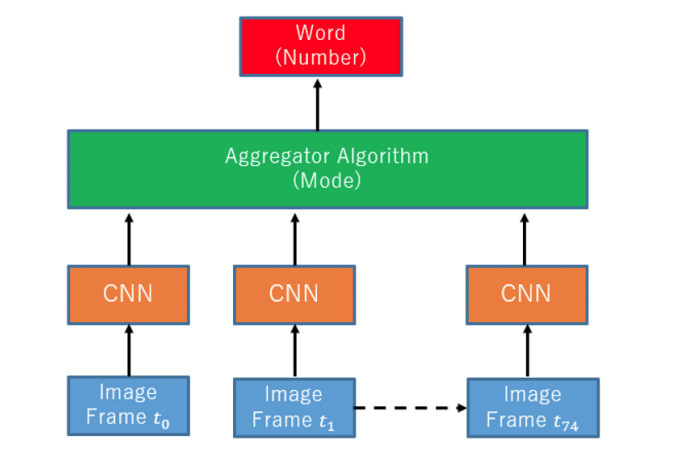
Video-Based Sign Language Digit Recognition for the Thai Language: A New Dataset and Method Comparisons Journal Article
In: International Conference on Pattern Recognition Applications and Methods, 2023.
SM-BERT-CR: a deep learning approach for case law retrieval with supporting model Journal Article
In: Artificial Intelligence and Law, vol. 31, no. 3, pp. 601–628, 2023.
SubTST: a consolidation of sub-word latent topics and sentence transformer in semantic representation Journal Article
In: Applied Intelligence, vol. 53, no. 11, pp. 13470–13487, 2023.
Welcome Message from the KSE 2023 General Committee Inproceedings
In: 2023 15th International Conference on Knowledge and Systems Engineering (KSE), pp. 1–2, IEEE 2023.
Improving diversity and quality of adversarial examples in adversarial transformation network Journal Article
In: Soft Computing, vol. 27, no. 7, pp. 3689–3706, 2023.
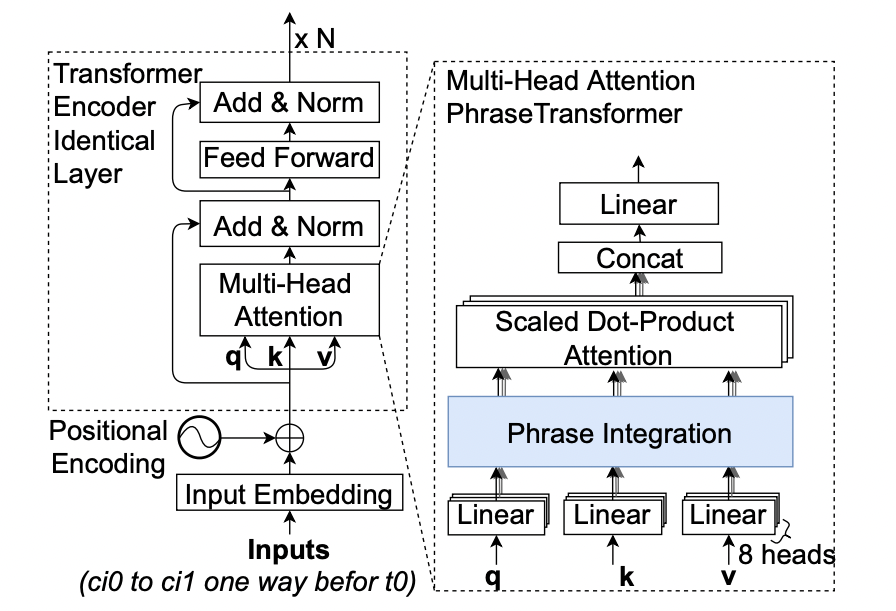
PhraseTransformer: an incorporation of local context information into sequence-to-sequence semantic parsing Journal Article
In: Applied Intelligence, vol. 53, no. 12, pp. 15889–15908, 2023.
Video-Based Sign Language Digit Recognition for the Thai Language: A New Dataset and Method Comparisons. Inproceedings
In: ICPRAM, pp. 775–782, 2023.
WeExt: A Framework of Extending Deterministic Knowledge Graph Embedding Models for Embedding Weighted Knowledge Graphs Journal Article
In: IEEE Access, vol. 11, pp. 48901–48911, 2023.
Improving Vietnamese Legal Question--Answering System Based on Automatic Data Enrichment Inproceedings
In: JSAI International Symposium on Artificial Intelligence, pp. 49–65, Springer Nature Switzerland Cham 2023.
Directional Generative Networks Journal Article
In: Available at SSRN 4474512, 2023.
GRAM: Grammar-Based Refined-Label Representing Mechanism in the Hierarchical Semantic Parsing Task Inproceedings
In: International Conference on Applications of Natural Language to Information Systems, pp. 339–351, Springer Nature Switzerland Cham 2023.
Parametric loss-based super-resolution for scene text recognition Journal Article
In: Machine Vision and Applications, vol. 34, no. 4, pp. 61, 2023.
StructSP: Efficient Fine-tuning of Task-Oriented Dialog System by Using Structure-aware Boosting and Grammar Constraints Inproceedings
In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10206–10220, 2023.
CovRelex-SE: Adding Semantic Information for Relation Search via Sequence Embedding Inproceedings
In: Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics: System Demonstrations, pp. 35–42, 2023.
An Effective Method using Phrase Mechanism in Neural Machine Translation Journal Article
In: arXiv preprint arXiv:2308.10482, 2023.
NegT5: A Cross-Task Text-to-Text Framework for Negation in Question Answering Inproceedings
In: Asian Conference on Intelligent Information and Database Systems, pp. 272–285, Springer Nature Singapore Singapore 2023.
ViWiQA: Efficient end-to-end Vietnamese Wikipedia-based Open-domain Question-Answering systems for single-hop and multi-hop questions Journal Article
In: Information Processing & Management, vol. 60, no. 6, pp. 103514, 2023.
The impact of large language modeling on natural language processing in legal texts: a comprehensive survey Inproceedings
In: 2023 15th International Conference on Knowledge and Systems Engineering (KSE), pp. 1–7, IEEE 2023.
A Summary of the ALQAC 2023 Competition Inproceedings
In: 2023 15th International Conference on Knowledge and Systems Engineering (KSE), pp. 1–6, IEEE 2023.
AIEPU at ALQAC 2023: deep learning methods for legal information retrieval and question answering Inproceedings
In: 2023 15th International Conference on Knowledge and Systems Engineering (KSE), pp. 1–6, IEEE 2023.
Constructing a Closed-Domain Question Answering System with Generative Language Models Inproceedings
In: 2023 15th International Conference on Knowledge and Systems Engineering (KSE), pp. 1–6, IEEE 2023.
A fast method to filter noisy parallel data wmt2023 shared task on parallel data curation Inproceedings
In: Proceedings of the Eighth Conference on Machine Translation, pp. 359–365, 2023.
Improving Multilingual Neural Machine Translation with Artificial Labels Inproceedings
In: Proceedings of the 12th International Symposium on Information and Communication Technology, pp. 79–84, 2023.
Deep Nested Clustering Auto-Encoder for Anomaly-Based Network Intrusion Detection Inproceedings
In: 2023 RIVF International Conference on Computing and Communication Technologies (RIVF), pp. 289–294, IEEE 2023.
Causal Intersectionality and Dual Form of Gradient Descent for Multimodal Analysis: a Case Study on Hateful Memes Journal Article
In: arXiv preprint arXiv:2308.11585, 2023.
Speaker Verification Using Distance Based on Principal Component Analysis for Household Scenario Adaptation Inproceedings
In: 2023 RIVF International Conference on Computing and Communication Technologies (RIVF), pp. 441–446, IEEE 2023.
Enhancing Legal Text Entailment with Prompt-Based ChatGPT: An Empirical Study Inproceedings
In: JSAI International Symposium on Artificial Intelligence, pp. 184–196, Springer Nature Switzerland Cham 2023.
Directional Generative Networks; Comparison to Evolutionary Algorithms, Using Measurements for Molecules Inproceedings
In: JSAI International Symposium on Artificial Intelligence, pp. 151–166, Springer Nature Switzerland Cham 2023.
2022
PhraseTransformer: an incorporation of local context information into sequence-to-sequence semantic parsing Journal Article
In: Applied Intelligence, 2022, ISSN: 1573-7497.
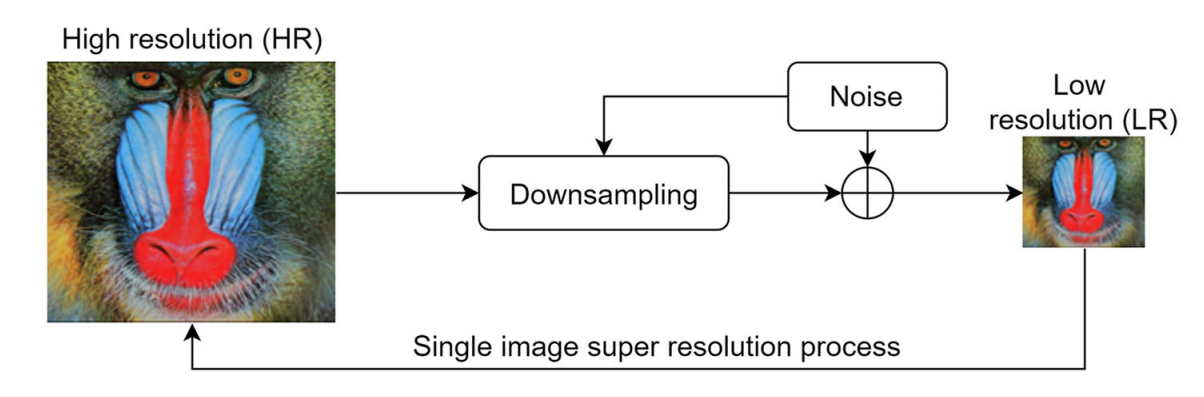
Parametric regularization loss in super-resolution reconstruction Journal Article
In: Machine Vision and Applications, vol. 33, no. 5, pp. 1–21, 2022, ISSN: 14321769.