




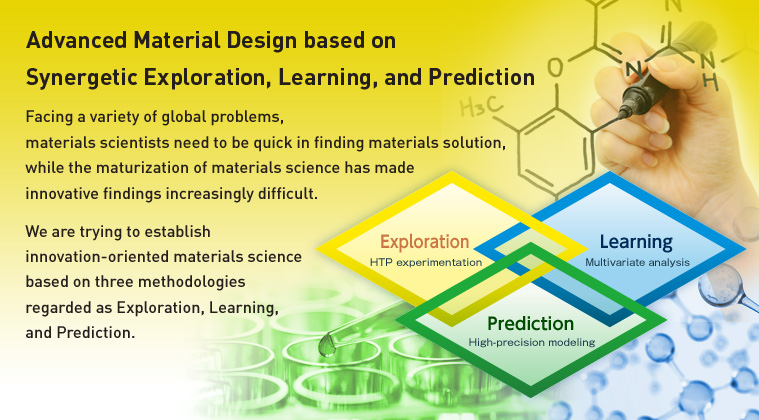
Taniike Lab.
MENU











2025.06.13 by 中野渡 淳 Sunao NakanowatariIn recent years, a growing number of catalyst datasets compiled from the literature have been made publicly available and actively used in data science. While these tabular datasets also contain historical insights into catalyst development, understanding such trends remains difficult in their raw form. In this study, we propose a "catalyst phylogenetic tree" to visualize the underlying design history embedded in these datasets. By grouping catalysts based on elemental combinations and mapping their physicochemical distances onto a phylogenetic tree, our method offers an intuitive overview of catalyst design lineages and trends. This versatile approach is also applicable to materials beyond catalysts.
2025.05.29 by Poulami MUKHERJEEWhat if advanced photocatalysts could be designed simply by mixing, screening, and discovering? Our high-throughput approach offers one such possibility. In this work, we propose an efficient synthesis of perovskites using citric acid, which holds promise for a wide range of applications, including environmental purification through photocatalysis.
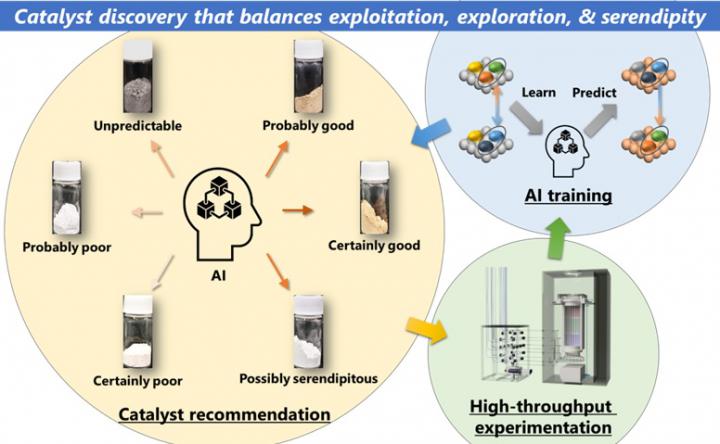
2025.05.15 by 中野渡 淳 Sunao NakanowatariIs an unknown catalyst likely to be high-performing, low-performing, potentially either, lacking sufficient information for prediction, or seemingly low-performing but with unexpected potential (serendipity)? In this study, we developed a system capable of inferring these possibilities from existing catalyst data. Using this system, we demonstrated the potential of a data-driven, efficient, and systematic approach to catalyst development that balances the exploitation of existing knowledge, exploration of unknowns, and discovery of serendipitous outcomes.
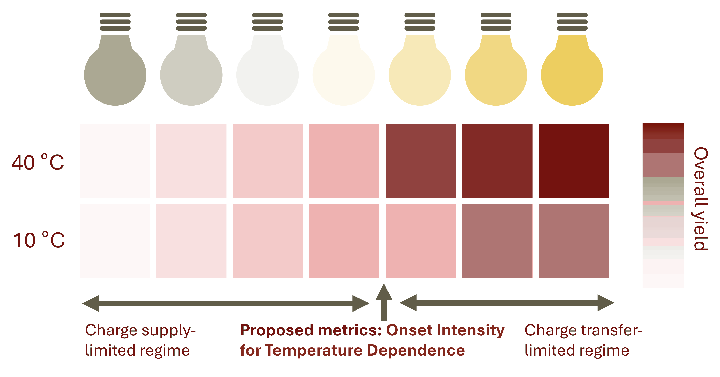
2025.04.11 by 張 葉平 Yohei ChoPhotocatalysis involves a series of sequential steps, including light absorption, excited carrier diffusion, and surface redox reactions, making the identification of the rate-limiting step challenging. This study demonstrates that the surface imbalance of excited carriers, manifested as variations in reaction temperature, can be utilized to distinguish whether the supply or consumption of excited carriers governs the reaction rate. This finding is anticipated to not only directly enhance photocatalytic performance but also significantly improve the precision of design hypotheses that were previously often ambiguous.
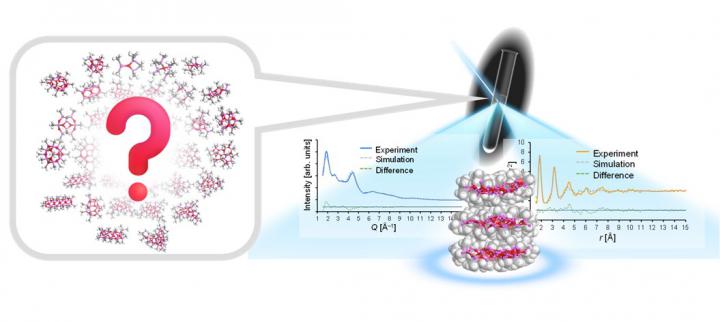
2025.02.27 by 和田 透 Toru WadaMolecular catalysts for synthesizing polyethylene and polypropylene exhibit catalytic activity upon contact with activators. Methylaluminoxane (MAO) is the most widely used activator, but its structure remains unclear, hindering the understanding of catalyst activation mechanisms and the development of new activators. In this study, we analyzed the molecular structure of MAO using synchrotron X-ray total scattering and identified it as plate-like molecules with diameters of approximately 2 nm. These findings are crucial for elucidating the working mechanism of MAO and expected to contribute to the development of new activators and plastic materials.