ADASPEC : Making Large Language Models Faster and More Efficient Across Multiple Languages
Researchers have developed a framework that dynamically adapts to different languages during inference, speeding up multilingual AI systems
Speculative decoding is a technique used to speed up large language models (LLMs), but existing approaches were mostly developed for English and are less effective in other languages. Now, researchers from Japan have developed ADASPEC, a speculative decoding framework that automatically generates language-specific training data and adapts its vocabulary during inference. Tested across seven languages and seven tasks, ADASPEC consistently outperformed existing methods while remaining practical and efficient for real-world multilingual applications.
Large language models (LLMs), which are the artificial intelligence (AI) systems behind modern chatbots, translation tools, and virtual assistants, have become revolutionary tools worldwide. Companies, governments, schools, and developers now rely on them to serve users across dozens of languages. Unfortunately, as these systems grow more capable and incorporate support for more and more languages, they also become more computationally demanding. Generating responses from large multilingual models not only costs more but also take significantly more time.
One of the leading approaches for addressing this issue is called speculative decoding. This technique can speed up LLM output by using a small internal "drafter" model to predict several words ahead at once, which the main model then checks in parallel. While powerful, most existing speculative decoding methods were built and optimized for English; high-quality training data for drafters is widely available in English but scarce or absent for many other languages. As a result, these speed-boosting techniques lose much of their effectiveness when dealing with non-English languages.
To tackle this problem, a research team (Do Dinh Truong and Le Nguyen Khang) led by Professor Le-Minh Nguyen from Japan Advanced Institute of Science and Technology, Japan, developed ADASPEC, a multilingual speculative decoding framework designed to work across languages from the ground up. Their paper, which was presented at Proceedings of the AAAI Conference on Artificial Intelligence [The Fortieth AAAI Conference on Artificial Intelligence (AAAI-26)] on March 14, 2026, introduces not only this new framework, but also a new benchmark for evaluating multilingual inference speed in LLMs.
The core challenge the team faced was twofold. First, training effective drafter models requires language-specific instruction data, which is limited or unavailable for many languages. Second, the vocabulary set a drafter uses to predict tokens needs to reflect the language being generated, not a one-size-fits-all list.
ADASPEC addresses both problems simultaneously. Rather than relying on existing datasets, it uses the target LLM itself to automatically generate instruction data in any desired language, including low-resource ones. Moreover, it analyzes word frequency across language-specific text sources to build compact and language-tailored vocabulary sets. "During inference, the system dynamically selects the optimal language, drafter model, and vocabulary size based on the recently generated context. By reducing unnecessary vocabulary computations, ADASPEC achieves faster and more stable multilingual inference," explains Prof. Nguyen. In other words, because the framework can adaptively identify the most suitable language-specific configuration from the generated context and switch drafters and vocabularies on the fly, it is well suited for real-world situations where users may write in any language.
To validate their approach, the researchers introduced Multi-SpecBench, a novel multilingual benchmark for evaluating speculative decoding that supports more rigorous comparisons. Using this, they tested ADASPEC across seven languages, namely English, German, French, Spanish, Chinese, Japanese, and Vietnamese, and seven task types, including question answering, summarization, code generation, translation, and math reasoning. Notably, the proposed framework consistently outperformed other state-of-the-art techniques, achieving up to a 2.3× speedup over EAGLE-2, one of today's strongest speculative decoding methods. The team found that some existing speculative decoding methods actually slowed down inference in non-English settings compared with using no acceleration at all, revealing how poorly adapted they are for multilingual use.
The researchers believe ADASPEC holds great potential in any setting where fast LLM responses in multiple languages matter, such as multilingual customer support systems, AI tutors, translation and summarization tools, and real-time conversational agents. Looking further ahead, this kind of research could help reduce the energy and infrastructure costs of running multilingual AI services, and meaningfully narrow the gap between the quality of AI assistance available in English and in other languages. "We expect the proposed technology to reduce response times and computational costs for multilingual AI services in general," concludes Prof. Nguyen. On top of this, for smaller organizations or communities working with lower-resource languages, a system that can generate its own training data and adapt without manual intervention represents a meaningful step toward more accessible and equitable AI.
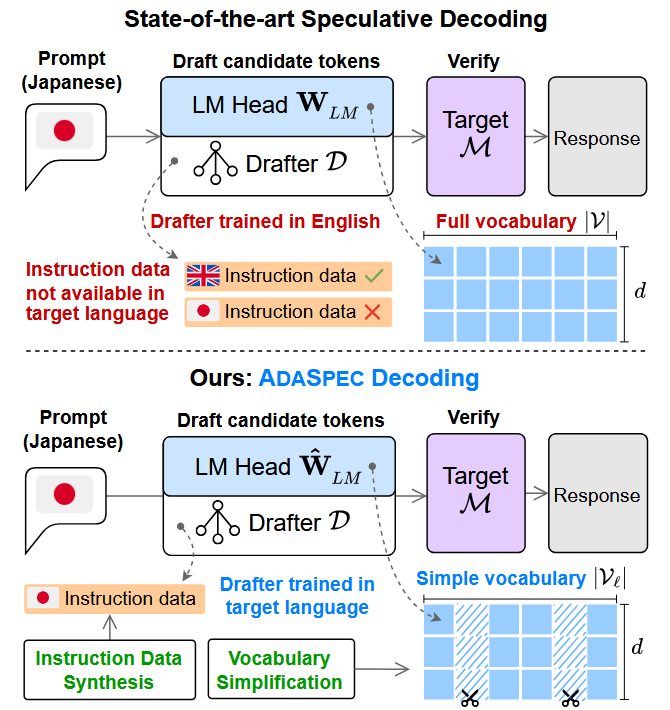
Image title: Conventional speculative decoding and ADASPEC
Image caption: ADASPEC overcomes the pervasive problem of instruction data being available mostly in English. By synthesizing data to train the drafter model in the target language and simplifying the vocabulary set, ADASPEC can make LLM inference faster and more computationally efficient.
Image credit: Professor Le-Minh Nguyen at JAIST
Image source link: Not available
License type: Original content
Usage restrictions: Cannot be reproduced without permission.
Reference
| Title of original paper: | ADASPEC: Adaptive Multilingual Speculative Decoding with Self-Synthesized Language-Aware Training and Vocabulary Simplification |
| Authors: | Dinh-Truong Do, Nguyen-Khang Le, and Le-Minh Nguyen |
| Journal: | Proceedings of the AAAI Conference on Artificial Intelligence; The Fortieth AAAI Conference on Artificial Intelligence (AAAI-26) |
| DOI: | 10.1609/aaai.v40i36.40307 |
Additional information for EurekAlert
| Latest Article Publication Date: | 14 March 2026 |
| Method of Research: | Experimental study |
| Subject of Research: | Not applicable |
| Conflicts of Interest Statement: | None |
June 4, 2026
