多言語LLM推論を最大2.3倍高速化する新技術「ADASPEC」を開発 ―言語ごとに適応する推論最適化で多言語AIの実用化を加速―
多言語LLM推論を最大2.3倍高速化する新技術「ADASPEC」を開発
―言語ごとに適応する推論最適化で多言語AIの実用化を加速―
ポイント
- LLMの回答生成を高速化する「Speculative Decoding」を、多言語環境に適応させる新手法「ADASPEC」を開発。
- 英語中心の従来手法では性能が出にくかった日本語・中国語・ベトナム語などにも対応。
- LLM自身が各言語の学習データを自動生成し、推論中の文脈に応じて、最適な言語・モデル・語彙サイズを自動で切り替える仕組みを実現。
- 7言語・7タスクで検証し、既存最先端手法EAGLE-2と比べて最大2.3倍の高速化を達成。
| 北陸先端科学技術大学院大学 コンピューティング科学研究領域のグェン・ミン・レ教授らの研究グループは、大規模言語モデル(LLM)*1の多言語推論を高速化する新しいフレームワーク「ADASPEC」を開発しました。LLMは、対話AI、翻訳、要約、業務支援などに広く使われ始めていますが、高性能なモデルほど回答生成に時間がかかり、計算コストも大きくなります。従来の推論高速化技術であるSpeculative Decoding*2は英語データに依存するものが多く、日本語・中国語・ベトナム語などでは十分な効果が得られにくいという課題がありました。本研究成果は、人工知能分野のトップ国際会議である「AAAI-26」に採択されています。 ADASPECでは、言語ごとに「先読み役」となる軽量なドラフターモデル*3と、計算に使う語彙集合を最適化します。研究グループは、対象となるLLM自身を用いて各言語の命令応答データを自動生成し、そのデータで言語特化型のドラフターモデルを学習させました。さらに、各言語でよく使われるトークン*4を分析して語彙を絞り込み、推論時には直近の文脈から最適な言語・ドラフター・語彙サイズを動的に選択します。これにより、言語が変わっても品質を保ちながら、より速く応答を生成できるようになります。 評価実験では、英語・ドイツ語・フランス語・スペイン語・中国語・日本語・ベトナム語の7言語、7種類のタスクを含む多言語ベンチマーク「Multi-SpecBench」を構築し、LLaMA-3およびQwen-2.5 系列の複数モデルで検証しました。その結果、ADASPECは既存最先端手法EAGLE-2と比較して最大2.3倍の高速化を達成しました。 今回の成果は、翻訳、多言語チャットボット、国際的な対話AI、教育支援、企業の多言語業務支援などへの応用が期待されます。 |
1.背景
大規模言語モデル(LLM)は、対話AI・翻訳・要約・コード生成・質問応答など、幅広い用途で急速に普及しています。LLMは一語ずつ文章を生成するため、モデルが大きくなるほど、回答が出るまでの時間や必要な計算資源が増えます。特に、利用者が多いサービスや、多数の言語に同時に対応するサービスでは、この「遅さ」と「計算コスト」が実用化の大きな課題となっています。
この課題に対し、近年「Speculative Decoding(スペキュラティブ・デコーディング)」という推論高速化技術が注目されています。これは、軽量なドラフターモデルが先に複数の候補トークンを予測し、大規模な対象モデルがそれらをまとめて検証することで、出力品質を保ったまま生成を速くする方法です。ただし、従来手法の多くは英語データを中心に設計されており、言語ごとに語彙の使われ方や文章構造が異なる多言語環境では、十分な効果が得られない場合がありました。そこで本研究では、言語ごとの特徴に合わせて推論を最適化する新しい仕組みを開発しました。
2.研究内容
本研究で提案したADASPECは、多言語環境に適応するSpeculative Decodingフレームワークです。単に英語向けに作られた高速化手法を他言語へ適用するのではなく、各言語のデータ、語彙、推論時の文脈に合わせて処理を切り替える点に特徴があります。以下の3つの仕組みにより、多言語での高精度かつ高速な推論を実現しています。
成果の例1:言語別ドラフターモデルを自動構築
ADASPECでは、対象LLM自身を利用して各言語の命令応答データを自動生成し、そのデータを用いて言語特化型のドラフターモデルを学習します。人手で大規模な学習データを準備する必要を減らせるため、公開データが少ない低資源言語*5にも対応しやすい点が特徴です。
成果の例2:言語ごとに必要な語彙を絞り込む最適化
LLMは膨大な語彙候補の中から次に出力するトークンを選びますが、実際によく使われるトークンは言語によって異なります。ADASPECでは、各言語で頻繁に使われるトークンを分析し、言語ごとに効率的な語彙集合を構築しました。これにより、不要な語彙計算を削減し、処理速度を大幅に向上させています。
成果の例3:推論中に言語・モデル・語彙サイズを自動切り替え
推論時には、直近に生成された文脈をもとに、現在どの言語で処理しているかを判断し、最適なドラフターモデルと語彙サイズを自動で選択します。固定された英語中心の仕組みではなく、言語の変化に応じて処理方法を切り替えることで、多言語環境でも安定した高速化を実現します。評価実験では、7言語・7タスクを含む多言語ベンチマーク「Multi-SpecBench」を構築してLLaMA-3やQwen-2.5系列のモデルで検証し、既存最先端手法EAGLE-2と比較して最大2.3倍の高速化を達成しました。
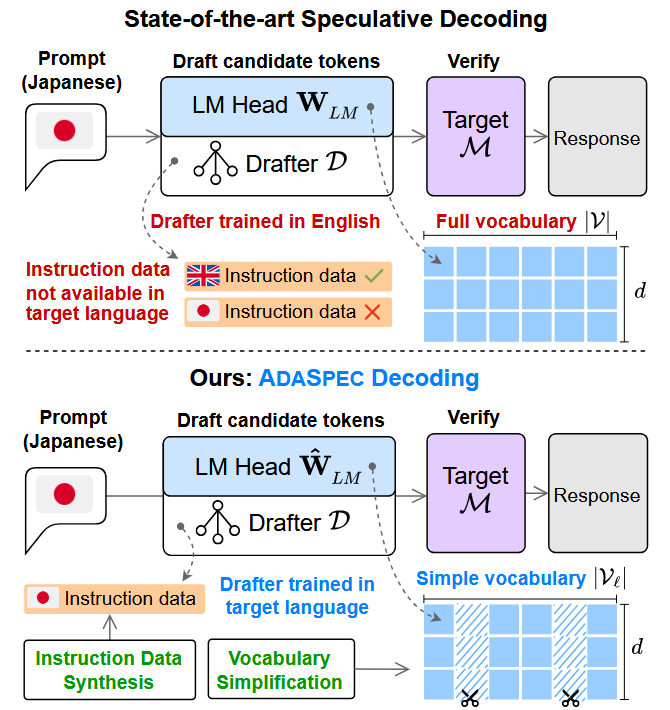
| 図1: ADASPECの概要(下段)と、従来の最先端Speculative Decoding手法(上段)との比較 従来手法では英語中心のドラフターと固定的な語彙を利用するため、言語が変わると高速化の効果が下がる場合があります。これに対し、ADASPECは、対象言語に応じた命令データ生成、言語別ドラフター、言語別語彙簡略化を組み合わせることで、多言語推論に適応します。 |
3.今後の期待・社会的意義
今回の成果は、多言語AIサービスの応答時間短縮と計算コスト削減に直接貢献するものです。たとえば、翻訳、国際的な対話AI、教育支援、カスタマーサポート、企業の多言語文書処理などでは、回答の速さが利用者の使いやすさに直結します。ADASPECにより、品質を維持しながら応答を高速化できれば、多言語AIをより多くの場面で実用化しやすくなります。
また、本研究で用いた「LLM自身によるデータ生成」と「言語別語彙最適化」のアプローチは、学習データが限られる低資源言語の処理改善にも応用できる可能性があります。英語など一部の主要言語だけでなく、多様な言語でAIを使いやすくすることは、AIの言語的公平性の向上にもつながります。今後は、より多くの言語や実サービス環境での検証を進めることで、多言語AI基盤の高度化への貢献が期待されます。
【用語説明】
大量のテキストを学習し、文章生成・質問応答・翻訳・要約などを行うAIモデル。ChatGPTのような対話AIの基盤技術として使われる。
軽量モデルが候補を先に生成し、大規模モデルがまとめて検証することで推論を高速化する技術。大規模モデルの出力品質を保ちながら、回答生成にかかる時間を短縮できる。
Speculative Decodingにおいて、生成候補をあらかじめ提案する軽量モデル。大規模モデルに対する「先読み役」として働く。
LLMが文章を処理する際の最小単位。単語、文字、記号、またはそれらを分割した単位など、モデルによって異なる。
学習や評価に利用できる公開データが比較的少ない言語。データが少ないため、AIモデルの性能向上が難しい場合がある。ベトナム語などが例として挙げられる。
【論文情報】
| 論文タイトル | AdaSpec: Adaptive Multilingual Speculative Decoding with Self-Synthesized Language-Aware Training and Vocabulary Simplification |
| 日本語タイトル | ADASPEC:自己合成言語認識訓練と語彙簡略化による適応型多言語スペキュラティブ・デコーディング |
| 著者 | Dinh-Truong Do, Nguyen-Khang Le, Le-Minh Nguyen |
| 発表学会 | The Fortieth AAAI Conference on Artificial Intelligence (AAAI-26) |
| 掲載誌 | Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 40 No. 36 |
| 掲載日 | 2026年3月14日 |
| DOI | https://doi.org/10.1609/aaai.v40i36.40307 |
【研究資金・謝辞】
本研究は、科学技術振興機構(JST) 先端国際共同研究推進事業(ASPIRE)(課題番号:JPMJAP25B2)、同 戦略的創造研究推進事業(CREST)(課題番号:JPMJCR2554)の一部支援を受けて実施されました。また、本研究の一部は株式会社リコーとの共同研究として実施されました。著者らは、有益な議論と継続的なご支援に深く感謝いたします。
令和8年6月2日
